Préparez-vous en clonant le dépôt d’exercices :
git clone https://github.com/Ecohydraulics/Exercise-geco.gitSacramento suckers in the South Yuba River (source: Sebastian Schwindt @hydroinformatics on YouTube).
Qu’est-ce que la qualité d’habitat?¶
Les poissons et les autres espèces aquatiques se reposent, s’orientent et se reproduisent dans un environnement fluvial qui représente leur habitat physique. Tout au long de leurs différentes étapes de vie, les différents poissons ont des préférences physiques spécifiques en matière d’habitat qui sont définies, par exemple, en fonction de la profondeur de l’eau, de la vitesse d’écoulement et de la taille des grains du lit de rivière. L’indice de qualité Habitat peut être calculé pour les paramètres hydrauliques (profondeur d’eau ou vitesse d’écoulement) et morphologiques (p. ex. granulométrie ou couverture sous forme de gros bois) afin de décrire individuellement la qualité de l’habitat physique pour un poisson et à un stade de vie précis. La figure ci-dessous montre des courbes exemplaires pour les stades de vie des alevins, des juvéniles et des adultes de truite arc-en-ciel en fonction de la profondeur de l’eau. Les courbes semblent différentes dans chaque rivière et devraient être établies individuellement par un écologue aquatique.
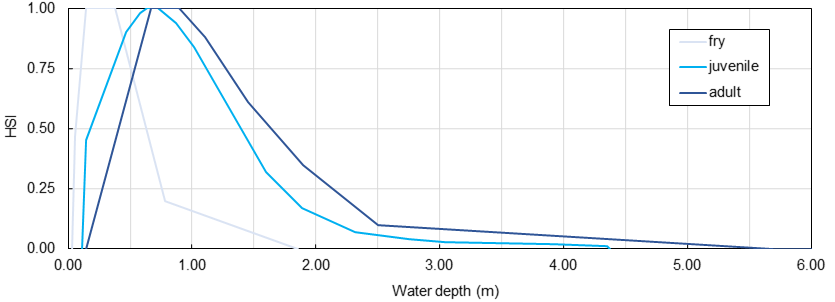
Figure 1:Habitat Suitability Index courbes pour les stades de vie des alevins, des juvéniles et des adultes de truite arc-en-ciel dans une rivière pavée. Prenez soin : les courbes HSI semblent différentes dans n’importe quelle rivière et doivent être établies par un écologue aquatique.
Le concept explique également l’habitat de couverture sous la forme de l’indice cover Habitat Suitability . L’habitat du couvert est le résultat de turbulences locales causées par des éléments de rugosité tels que le bois, les rochers ou les jetées de pont. Toutefois, dans le cadre de cet exercice, nous ne traiterons que des caractéristiques de l’habitat hydraulique (et non de l’habitat couvert).

Adult trout swimming in cover habitat created by a bridge pier in the upper Neckar River.
La combinaison de plusieurs valeurs (p. ex., en fonction de la profondeur de l’eau , en fonction de la vitesse du flux , en fonction de la taille du grain et/ou de la couverture ) donne des résultats dans l’indice combiné de qualité de l’habitat . Il existe différentes méthodes de calcul pour combiner différentes valeurs en une valeur , où la moyenne géométrique et le produit sont les méthodes de combinaison déterministe les plus utilisées:
Par conséquent, si les valeurs de basées sur pixel pour la profondeur de l’eau et la vitesse du débit sont connues à partir d’un modèle hydrodynamique bidimensionnel (2d), alors pour chaque pixel la valeur peut être calculée soit comme le produit ou la moyenne géométrique du monoparamètre rasters.
Ce concept d’évaluation de l’habitat a été introduit par Bovee (1986) et Stalnaker et al. (1995) (téléchargement direct). Cependant, ces auteurs ont construit leur évaluation (physique) de l’habitat utilisable à partir de modèles numériques unidimensionnels (1d) qui étaient couramment utilisés au cours du dernier millénaire. Aujourd’hui, les modèles numériques 2d sont à la fine pointe de la technologie pour déterminer l’habitat physique géospatialement explicite basé sur les valeurs pixel. Il existe deux options différentes pour calculer la zone d’habitat utilisable () en fonction des valeurs de pixel (et d’autres options peuvent être trouvées dans la littérature scientifique).
Une alternative au calcul déterministe des valeurs et d’un pixel est une approche logique floue Noack et al., 2013. Dans l’approche logique floue, les pixels sont classés, par exemple, comme faible, moyen ou haute qualité de l’habitat en fonction de la profondeur d’eau ou de la vitesse d’écoulement associée, en utilisant des courbes d’évaluation . La valeur résulte du centre de gravité des fonctions d’adhésion superposées de paramètres considérés (p. ex. profondeur de l’eau et vitesse du débit).
La gestion durable des cours d’eau comporte le défi de concevoir un habitat aquatique pour les espèces de poissons ciblées à différents stades de la vie. Le concept d’habitat physique utilisable représente un outil puissant pour tirer parti de l’évaluation de l’intégrité écologique des mesures de gestion et d’ingénierie des rivières. Par exemple, en calculant l’habitat utilisable avant et après la mise en oeuvre des mesures, on peut tirer des conclusions précieuses sur l’intégrité écologique des efforts de restauration.
Cet exercice démontre l’utilisation des résultats de modélisation hydrodynamique 2d pour évaluer algorithmiquement la zone d’habitat utilisable en fonction du calcul des valeurs géospatialement explicites .
Données disponibles et structure du code¶
Le diagramme suivant illustre le code et les données fournis. Les fonctions, les méthodes et les fichiers à créer dans cet exercice sont mis en évidence en gras, en italique, en caractères YELLOW-ish.
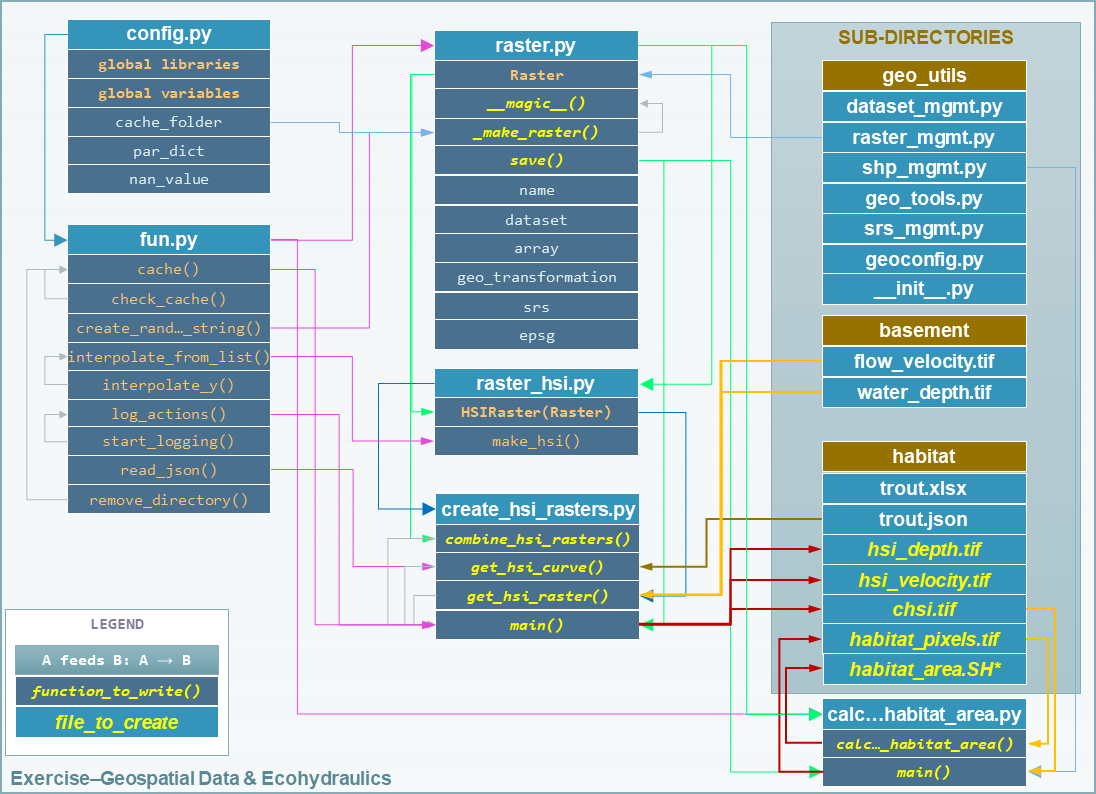
Figure 2:Structure de l’arborescence de fichiers de modèles fournie et de leurs relations.
Le fichier de projet QGIS fourni visualize_with_QGIS.qgz aide à vérifier les ensembles de données et les résultats obtenus.
Modélisation hydrodynamique bidimensionnelle (2d) (Dossier : BASEMENT)¶
Cet exercice utilise la vitesse d’écoulement (hydraulique) et la profondeur d’eau des rasters (GeoTIFFs) produits avec le logiciel ETH Zurich*s BASEMENT. En savoir plus sur la modélisation hydrodynamique avec BASE dans le chapitre BASE. Les rasters hydrauliques ont été produits avec les données du développeur de BASEMENT exemple de données de la rivière Flaz* en Suisse (en savoir plus sur leur site Web].
La profondeur d’eau water_depth.tif et la vitesse de débit flow_velocity.tif rasters sont fournies pour cet exercice dans le dossier /basement/.
Indice de qualité de l’habitat Courbes HSI (dossier : habitat)¶
The /habitat/ folder in the exercise repository contains curves in the form of an xlsx workbook (trout.xlsx) and in the form of a JSON file (trout.json). Both files contain the same data for rainbow trout of a hypothetical cobble-bed river and this exercise only uses the JSON file (the workbook serves for visual verification only).
Code¶
Créer et combiner des rasoirs HSI¶
Complete the __init__ Method of the Raster Class (raster.py)¶
Le script raster.py importe les fonctions et les bibliothèques chargées dans le script fun.py, et donc aussi le script config.py. Pour cette raison, les bibliothèques NombrePy et Pandas sont déjà disponibles (as np et pd, respectivement), et le paquet geo utils est déjà importé comme geo (import geo_utils as geo à config.py).
La classe Raster charge n’importe quel nom de fichier GeoTIFF comme un objet de tableau géoréférencé qui peut être utilisé avec des opérateurs mathématiques. Tout d’abord, nous compléterons la méthode __init__ par un Raster.name (extrait de l’argument file_name), ainsi que les géoréférences et les ensembles de données de tableau:
# __init__(...) of Raster class in raster.py
self.name = file_name.split("/")[-1].split("\\")[-1].split(".")[0]Si le file_name n’existe pas, la méthode __init__ crée un nouveau raster avec le file_name (ce comportement est déjà implémenté dans l’énoncé if not os.path.exists(file_name).
Ensuite, chargez le osgeo.gdal.dataset, le np.array et le geo_transformation du raster. À cette fin, utilisez le raster2array function de ce livre électronique, qui est également implémenté dans le paquet geo utils (geo) de l’exercice :
# __init__(...) of Raster class in raster.py
self.dataset, self.array, self.geo_transformation = geo.raster2array(file_name, band_number=band)Pour identifier le EPSG number (Authority code) d’un raster, récupérer le système de référence spatiale (SRS) du raster. À cette fin également, nous avons déjà développé une fonction dans la conférence avec le get_srs de la theory section on reprojection. Chargez le numéro SRS et EPSG en utilisant la fonction get srs avec les deux lignes de code suivantes dans la méthode __init__:
# __init__(...) of Raster class in raster.py
self.srs = geo.get_srs(self.dataset)
self.epsg = int(self.srs.GetAuthorityCode(None)La méthode __init__ de la classe Raster est complète.
Méthodes magiques complètes de la classe Raster (raster.py)¶
To enable mathematical operations between multiple instances of the Raster class, implement Surcharge et méthodes magiques that tell the class what to do when two Raster instances are for example added (+ sign), multiplied (* sign), or subtracted (- sign). For instance, implementing the magic methods __truediv__ (for using the / operator), __mul__ (for using the * operator), and __pow__ (for using the ** operator) will enable the usage of Raster instances like this:
# example for Raster instances, when operators are defined through magic methods
# load GeoTIFF rasters from file directory
velocity = Raster("/usr/geodata/u.tif")
depth = Raster("/usr/geodata/h.tif")
# calculate the Froude number using operators defined with magic methods
Froude = velocity / (depth * 9.81) ** 0.5
# save the new raster
Froude.save("/usr/geodata/froude.tif")Le modèle de classe Raster contient déjà une méthode magique exemplaire pour permettre la division (__truediv__):
# Raster class in raster.py
def __truediv__(self, constant_or_raster):
try:
self.array = np.divide(self.array, constant_or_raster.array)
except AttributeError:
self.array /= constant_or_raster
return self._make_raster("div")Voici ce que fait la méthode __truediv__ :
L’argument d’entrée
constant_or_rasterpeut être une autre instanceRasterqui a un attributarrayou une constante numérique (par exemple, 9.81).La méthode essaie d’invoquer l’attribut tableau de
constant_or_raster.Si
constant_or_rasterest un objet raster, alors invocationcontant_or_raster.arrayest réussie. Dans ce cas,self.arrayest écrasé parcontant_or_raster.array. La division par élément s’appuie sur la fonction intégrée NombrePys np.divid, qui est un wrapper efficace en calcul du code C/C++ (bien plus rapide qu’une boucle Python sur les éléments du tableau).Si
constant_or_rasterest une valeur numérique, alors invocationcontant_or_raster.arrayrésultatsAttributeErroret la méthode__truediv__tombe dans l’énoncéexcept AttributeError, oùself.arrayest simplement divisé parconstant_or_raster.
La méthode renvoie le résultat de la méthode pseudo privée
self._make_raster("div")([rappeler PEP 8 Style de code et conventions, qui correspond à une nouvelle instanceRasterde l’instanceRasterdivisée parconstant_or_raster. La nouvelle instanceRasterest un fichier temporaire GeoTIFF dans le dossier cache (appelez le cache function). Voici comment la méthode pseudo-privée_make_raster(self, file_marker)ressemble à:
Cette fonction:
Utilise l’argument de type string
file_markerpour l’ajouter au nom de fichier de la base GeoTIFF ainsi qu’un string aléatoire de quatre caractères (appelez le create_random_string).file_markerest unique pour chaque opérateur mis en œuvre. Pour la méthode__truediv__utiliserfile_marker="div". Ainsi, le nom de fichier temporaire GeoTIFF est défini commecache_folder + self.name + f_ending(par exemple"C:\Excercise-geco\__cache__\velocity__divhjev__.tif").Applique la fonction Créer un Raster (Array to Raster) de
geo_utilspour écrire le temporaire GeoTIFF au dossier__cache__avec le système de référence spatiale du raster original.returns une nouvelle instanceRasterdu fichier temporaire, cache GeoTIFF.
If you find the _make_raster method confusing...
Alors vous avez raison. L’approche décrite ci-dessus implémente la méthode _make_raster pour réutiliser les GeoTIFF temporaires plus tard avec les constantes (float) et les tableaux, mais il y a une façon plus élégante de retourner une nouvelle instance Raster. Cependant, le retour d’une nouvelle instance de la même classe exige que l’argument d’entrée soit une instance de la classe elle-même (c.-à-d. Raster) et non une variable numérique. La solution alternative pour renvoyer une instance Raster commence par une mise en œuvre différente de la méthode magique (par exemple, __truediv__) et nécessite d’importer Python4-style annotations. Par conséquent, la première ligne du script doit inclure (seulement fonctionne avec Python 3.7 et plus) l’importation suivante:
from __future__ import annotationsPuis réécrire la méthode __truediv__:
def __truediv__(self, other: Raster) -> Raster:
f_ending = "__div%s__.tif" % create_random_string(4)
return Raster(file_name=cache_folder + self.name + f_ending,
raster_array=np.divide(self.array, other.array),
epsg=self.epsg,
geo_info=self.geo_transformation)Dans ce cas, la méthode _make_raster est obsolète. En savoir plus sur les instances renvoyées de la même classe sur stack débord.
Lors de l’utilisation de la méthode _make_raster, ajoutez les méthodes magiques suivantes à la classe Raster (les détenteurs de place sont déjà présents dans le modèle raster.py):
__add__(+operator):
try:
self.array += constant_or_raster.array
except AttributeError:
self.array += constant_or_raster
return self._make_raster("add")__mul__(*operator):
try:
self.array = np.multiply(self.array, constant_or_raster.array)
except AttributeError:
self.array *= constant_or_raster
return self._make_raster("mul")__pow__(**operator):
try:
self.array = np.power(self.array, constant_or_raster.array)
except AttributeError:
self.array **= constant_or_raster
return self._make_raster("pow")__sub__(-operator):
try:
self.array -= constant_or_raster.array
except AttributeError:
self.array -= constant_or_raster
return self._make_raster("sub")Le dernier élément à compléter dans la classe Raster est la méthode intégrée save qui reçoit un argument file_name (string) définissant le répertoire et sauvant comme nom de l’instance Raster:
save_status = geo.create_raster(file_name, self.array, epsg=self.epsg, nan_val=0.0, geo_info=self.geo_transformation)
return save_statusPourquoi avons-nous besoin de la variable save_status? Tout d’abord, il indique si la sauvegarde du raster a été réussie (save_status=0), et ensuite, cette information pourrait être utilisée pour supprimer le raster du dossier __cache__ et rincer la mémoire (se sentir libre de le faire pour accélérer le code).
Écrire HSI et cHSI Raster Creation Script¶
Le script create_hsi_rasters.py contient déjà les importations de paquets requises, une déclaration if __name__ == '__main__' autonome ainsi que le vide main, get_hsi_curve, get_hsi_raster, et combine_hsi_rasters fonctions:
La déclaration if __name__ == '__main__' contient un compteur de temps (perf_counter) qui indique combien de temps le script prend pour courir (habituellement entre 3 et 6 secondes). Assurez-vous que
la liste
parameterscontient"velocity"et"depth"(selon le scriptpar_dictdans le scriptconfig.py),les chemins de fichiers sont définis correctement, et
Une étape de vie est définie (c.-à-d. soit
"fry","juvenile","adult", ou"spawning"selon le cahier de travail /habitat/fish.xlsx).
Les paragraphes suivants montrent étape par étape comment charger les courbes à partir du fichier JSON (get_hsi_curve), les appliquer à flow_velocity et water_depth rasters (get_hsi_raster), et combiner les résultats rasters en rasters (combine_hsi_rasters).
La fonction get_hsi_curve charge la courbe à partir du fichier JSON (/habitat/trut.json) dans un dictionnaire pour les deux paramètres "velocity" et "depth". Ainsi, le but est de créer un dictionnaire curve_data qui contient un objet Pandas DataFrame pour tous les paramètres (c.-à-d. vitesse et profondeur). Par exemple, curve_data["velocity"]["u"] sera un Pandas Series des entrées de vitesse (en m/s) qui correspond à curve_data["velocity"]["HSI"], qui est un Pandas Series de valeurs. De même, curve_data["depth"]["h"] est un Pandas Series des entrées de profondeur (en mètres) qui correspond à curve_data["depth"]["HSI"], qui est un Pandas Series de valeurs (correspond aux courbes indiquées dans le HSI graphs ci-dessus). Pour extraire les informations souhaitées du fichier JSON, get_hsi_curve prend trois arguments (json_file, life_stage, et parameters) afin de :
Get the information stored in the JSON file with the
read_jsonfunction (see above).Immédiatement vide
curve_dataDictionnaire qui contiendra le PandasDataFrames pour"velocity"et"depth".Lancez une boucle sur les (deux) paramètres (
"velocity"et"depth"), dans lesquels il :Crée un vide
par_pairsListe pour stocker des paires de paramètres (par) - valeurs comme listes imbriquées.Iterates through the length of provided curve data, where valid data pairs (e.g.,
[u_value, HSI_value]) are appended to thepar_pairsListe. This iteration is what actually creates the nested Liste.Convertit la liste finale
par_pairsà une PandasDataFramequ’elle ajoute à lacurve_dataDictionnaire.
returnlecurve_dataDictionnaire avec son PandasDataFrames.
# create_hsi_rasters.py
def get_hsi_curve(json_file, life_stage, parameters):
# read the JSON file with fun.read_json
file_info = read_json(json_file)
# instantiate output dictionary
curve_data = {}
# iterate through parameter list (e.g., ["velocity", "depth"])
for par in parameters:
# create a void list to store pairs of parameter-HSI values as nested lists
par_pairs = []
# iterate through the length of parameter-HSI curves in the JSON file
for i in range(0, file_info[par][life_stage].__len__():
# if the parameter is not empty (i.e., __len__ > 0), append the parameter-HSI (e.g., [u_value, HSI_value]) pair as nested list
if str(file_info[par][life_stage][i]["HSI"]).__len__() > 0:
try:
# only append data pairs if both parameter and HSI are numeric (floats)
par_pairs.append([float(file_info[par][life_stage][i][par_dict[par]]),
float(file_info[par][life_stage][i]["HSI"])])
except ValueError:
logging.warning("Invalid HSI curve entry for {0} in parameter {1}.".format(life_stage, par)
# add the nested parameter pair list as pandas DataFrame to the curve_data dictionary
curve_data.update({par: pd.DataFrame(par_pairs, columns=[par_dict[par], "HSI"])})
return curve_dataDans la fonction main, appelez get_hsi_curves pour obtenir les courbes comme une Dictionnaire. En outre, implémentez le cache et le log_actions wrappers (appelez les descriptions de provided functions) pour la fonction main:
# create_hsi_rasters.py
...
@log_actions
@cache
def main():
# get HSI curves as pandas DataFrames nested in a dictionary
hsi_curve = get_hsi_curve(fish_file, life_stage=life_stage, parameters=parameters)
...Avec la classe HSIRaster (raster_hsi.py), les rasters peuvent être créés dans la fonction get_hsi_raster. Avant d’utiliser la classe HSIRaster, assurez-vous de comprendre comment cela fonctionne. La classe HSIRaster hérite de la classe Raster et initie sa classe mère dans sa méthode __init__ par Raster.__init__(self, file_name=file_name, band=band, raster_array=raster_array, geo_info=geo_info). Ensuite, la classe appelle sa méthode make_hsi, qui prend une courbe (nested Liste) de deux paires égales Liste (Liste des paramètres et Liste de valeurs) comme argument. La méthode make_hsi:
Extrait les valeurs des paramètres (p. ex. profondeur ou vitesse) du premier élément du nid
hsi_curvesListe, et valeurs du deuxième élément du nidhsi_curvesListe.Uses NombrePys built-in
np.nditerfunction, which iterates through NombrePy arrays with high computational efficiency (read more aboutnditer).La boucle
nditerpasse lepar_valuesasx_valuesListe argument et lehsi_valuesasy_valuesListe argument à la fonctioninterpolate_from_list(rappelez le function descriptions above).The array values (i.e., flow velocity or water depth) correspond to the
xi_valuesListe argument of theinterpolate_from_listfunction.The
interpolate_from_listfunction then identifies for each element of thexi_valuesListe the closest elements ( values) in thex_valuesListe and the corresponding positions in they_valuesListe.La fonction
interpolate_from_listpasse les valeurs identifiées à la fonctioninterpolate_y, qui interpole ensuite linéairement la valeur correspondanteyi(c.-à-d. une valeur ).Ainsi, la vitesse d’écoulement ou les profondeurs d’eau dans
self.arraysont dans le sens de la ligne (au fur et à mesure) remplacées par des valeurs .
returns aRasterinstance utilisant le pseudo-privé_make_rasterméthode (recall its contents).
# raster_hsi.py
from raster import *
class HSIRaster(Raster):
def __init__(self, file_name, hsi_curve, band=1, raster_array=None, geo_info=False):
Raster.__init__(self, file_name=file_name, band=band, raster_array=raster_array, geo_info=geo_info)
self.make_hsi(hsi_curve)
def make_hsi(self, hsi_curve):
par_values = hsi_curve[0]
hsi_values = hsi_curve[1]
try:
with np.nditer(self.array, flags=["external_loop"], op_flags=["readwrite"]) as it:
for x in it:
x[...] = interpolate_from_list(par_values, hsi_values, x)
except AttributeError:
print("WARNING: np.array is one-dimensional.")
return self._make_raster("hsi")Modifier la fonction get_hsi_rasters pour retourner directement un objet HSIRaster:
# create_hsi_rasters.py
...
def get_hsi_raster(tif_dir, hsi_curve):
return HSIRaster(tif_dir, hsi_curve)
...
La fonction get_hsi_raster nécessite deux arguments, qu’elle doit recevoir de la fonction main. Pour cette raison, itérer au-dessus de la parameters Liste dans la fonction main et extraire les répertoires correspondants de la tifs Dictionnaire (appelez la définition variable dans la standalone statement). En outre, enregistrez les objets Raster retournés par la fonction get_hsi_raster dans une autre fonction Dictionnaire (eco_rasters) pour les combiner dans la prochaine étape vers un raster .
# create_hsi_rasters.py
...
@log_actions
@cache
def main():
# get HSI curves as pandas DataFrames nested in a dictionary
hsi_curve = get_hsi_curve(fish_file, life_stage=life_stage, parameters=parameters)
# create HSI rasters for all parameters considered and store the Raster objects in a dictionary
eco_rasters = {}
for par in parameters:
hsi_par_curve = [list(hsi_curve[par][par_dict[par]]),
list(hsi_curve[par]["HSI"])]
eco_rasters.update({par: get_hsi_raster(tif_dir=tifs[par], hsi_curve=hsi_par_curve)})
eco_rasters[par].save(hsi_output_dir + "hsi_%s.tif" % par)
...Bien sûr, on peut aussi contourner les paramètres Liste directement dans la fonction get_hsi_raster.
Ensuite, nous en venons à la raison pour laquelle nous avons dû définir des méthodes magiques pour la classe Raster : combiner les rasters en utilisant les deux formules combinées présentées ci-dessus (appelez les formules product and geometric mean), où "geometric_mean" devrait être utilisé par défaut. La fonction combine_hsi_rasters accepte deux arguments (a Liste de Raster objets correspondant à rasters et method à utiliser comme string).
Si la méthode correspond à la valeur par défaut "geometric_mean", alors la power à appliquer au produit de la Raster Liste est calculée à partir de la racine nth, où n correspond au nombre d’objets Raster dans la raster_list. Sinon (par exemple, method="product"), la power est exactement 1.0.
La fonction combine_hsi_rasters crée initialement un vide Raster dans le cache_folder, chaque cellule ayant la valeur 1.0 (remplie par np.ones). En boucle sur les éléments Raster de la raster_list, la fonction multiplie chaque raster avec la raster.
Enfin, la fonction retourne le produit de tous rasters à la puissance de la valeur précédemment déterminée power.
# create_hsi_rasters.py
def combine_hsi_rasters(raster_list, method="geometric_mean"):
if method is "geometric_mean":
power = 1.0 / float(raster_list.__len__()
else:
# supposedly method is "product"
power = 1.0
chsi_raster = Raster(cache_folder + "chsi_start.tif",
raster_array=np.ones(raster_list[0].array.shape),
epsg=raster_list[0].epsg,
geo_info=raster_list[0].geo_transformation)
for ras in raster_list:
chsi_raster = chsi_raster * ras
return chsi_raster ** powerPour terminer le script create_hsi_rasters.py, implémentez l’appel à la fonction combine_hsi_rasters dans la fonction main et enregistrez le résultat sous GeoTIFF raster dans le dossier /habitat/:
# create_hsi_rasters.py
...
@log_actions
@cache
def main():
...
for par in parameters:
hsi_par_curve = [list(hsi_curve[par][par_dict[par]]),
list(hsi_curve[par]["HSI"])]
eco_rasters.update({par: get_hsi_raster(tif_dir=tifs[par], hsi_curve=hsi_par_curve)})
eco_rasters[par].save(hsi_output_dir + "hsi_%s.tif" % par)
# get and save chsi raster
chsi_raster = combine_hsi_rasters(raster_list=list(eco_rasters.values(),
method="geometric_mean")
chsi_raster.save(hsi_output_dir + "chsi.tif")
...Exécuter le code HSI et cHSI¶
Une exécution réussie du script create_hsi_rasters.py devrait ressembler à ceci (en PyCharm):
Figure 3:Une console Python Windows exécutant les scripts créés ci-dessus.
Plotted in QGIS, the GeoTIFF raster should look like this:
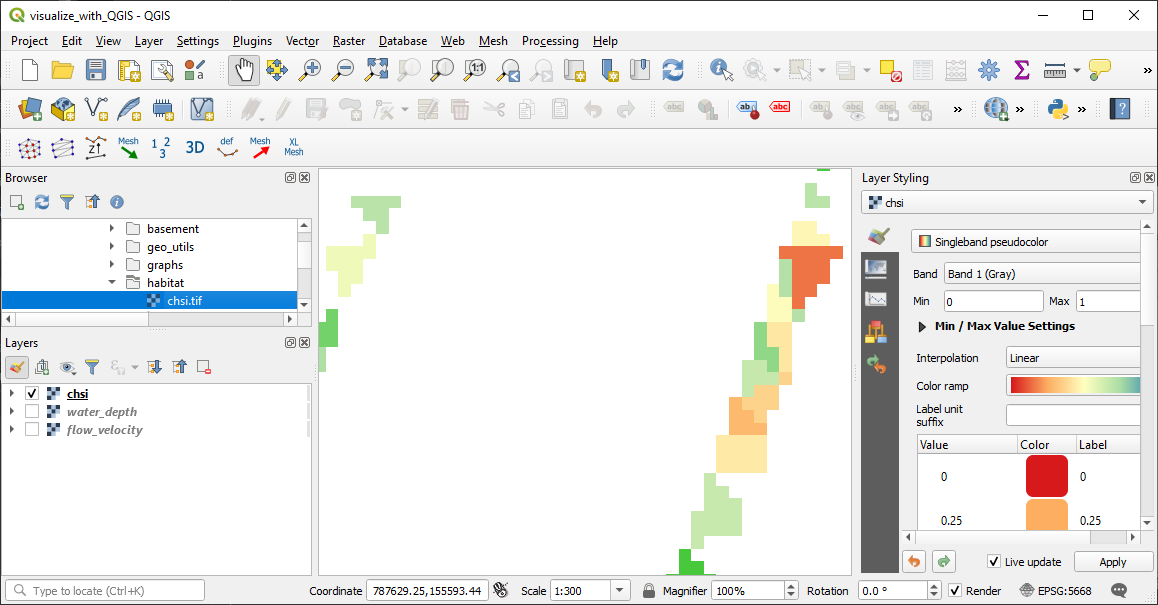
Figure 4:Le raster du cHSI tracé dans le QGIS, où la mauvaise qualité de l’habitat physique (cHSI près de 0,0) est colorée en rouge et la qualité de l’habitat physique élevée (cHSI près de 1,0) est colorée en vert.
Interprétation des résultats¶
La présentation du raster montre que les zones d’habitat préférées pour la truite juvénile n’existent que près des berges. De plus, les artefacts numériques du maillage triangulaire utilisé par BASE sont visibles. Par conséquent, la question se pose de savoir si les vitesses d’écoulement et les profondeurs d’eau calculées, ainsi que les valeurs , à proximité des berges, peuvent être considérées comme représentatives.
Calculer l’habitat utilisable UHA¶
Écrire le code¶
Les rasters permettent de calculer l’habitat utilisable disponible. La section précédente présentait des exemples utilisant l’espèce de poisson tout et son stade vital juvenile, pour lesquels nous déterminerons ici la zone d’habitat utilisable (en m) en utilisant une valeur seuil (plutôt que l’approche de pondération de la zone de pixel). Nous suivons donc le threshold formula described above, en utilisant une valeur seuil de . Ainsi, chaque pixel ayant une valeur de 0,4 ou plus compte comme zone d’habitat utilisable.
D’un point de vue technique, cette partie de l’exercice consiste à transformer un raster en un fichier de forme polygone ainsi qu’à accéder et à modifier la table Attribut du fichier de forme.
Comme pour la création du raster , il y a un script modèle disponible pour cette partie de l’exercice, appelé calculate_habitat_area.py, qui contient des paquets et des importations de modules, une déclaration autonome if __name__ == '__main__', ainsi que le vide main et calculate_habitat_area fonctions. (template uha)=
Le script template ressemble à ceci :
# this is calculate_habitat_area.py (template)
from fun import *
from raster import Raster
def calculate_habitat_area(layer, epsg):
pass
def main():
pass
if __name__ == '__main__':
chsi_raster_name = os.path.abspath("") + "\\habitat\\chsi.tif"
chsi_threshold = 0.4
main()Dans l’énoncé if __name__ == '__main__', assurez-vous que la variable globale chsi_raster_name corresponde au répertoire du raster créé dans la section précédente. L’autre variable globale (chsi_threshold) correspond à la valeur de 0,4 que nous utiliserons avec le threshold formula.
In the main function, start with loading the raster (chsi_raster) as a Raster object. Then, access the NombrePy array of the raster and compare it with chsi_threshold using NombrePys built-in greater_equal function. np.greater_equal takes an array as first argument and a second argument, which is the condition that can be a numeric variable or another NombrePy array. Then, np.greater_equal checks if the elements of the first array are greater than or equal to the second argument. In the case of the second argument being an array, this is an element-wise comparison. The result of np.greater_equal is a Booléen array (True where the greater-or-equal condition is fulfilled and False otherwise). However, to create an osgeo.gdal.Dataset object from the result of np.greater_equal, we need a numeric array. For this reason, multiply the result of np.greater_equal by 1.0 and assign it as a new NombrePy array of zeros (False) and ones (True) to a variable named habitat_pixels (see the code block below).
Avec le tableau habitat_pixels et la géoréférence de chsi_raster, créez un nouveau raster integer GeoTIFF avec la fonction create raster (également disponible dans flusstools.geotools); ici, utilisez geo.create_raster. Dans le bloc de code suivant, le nouveau raster est enregistré dans le dossier /habitat/ de l’exercice comme habitat-pixels.tif.
# calculate_habitat_area.py
...
def main():
# open the chsi raster
chsi_raster = Raster(chsi_ras_name)
# extract pixels where the physical habitat quality is higher than the user threshold value
habitat_pixels = np.greater_equal(chsi_raster.array, chsi_threshold_value) * 1
# write the habitat pixels to a binary array (0 -> no habitat, 1 -> usable habitat)
geo.create_raster(os.path.abspath("") + "\\habitat\\habitat-pixels.tif",
raster_array=habitat_pixels,
epsg=chsi_raster.epsg,
geo_info=chsi_raster.geo_transformation)
...Dans l’étape suivante, convertissez le pixel raster de l’habitat en un fichier de forme polygone et enregistrez-le dans le dossier /habitat/ sous habitat-area.shp. La conversion d’un raster en un fichier de forme polygone exige que le raster ne contienne que des valeurs integer, ce qui est le cas dans le raster pixel de l’habitat (seulement zéros et zéros - rappel Raster à Polygon). Utilisez la fonction raster2polygon dans le dossier geo utils (paquet) pour créer le nouveau fichier de formes polygones, spécifiez habitat-pixels.tif comme raster_file_name à convertir, et /habitat/habitat-area.shp comme nom de fichier de sortie. La fonction geo.raster2polygon retourne un objet osgeo.ogr.DataSource et nous pouvons passer sa couche comprenant les informations du code d’autorité EPSG (de chsi_raster) directement à la fonction non écrite calculate_habitat_area():
# calculate_habitat_area.py
...
def main():
... (create habitat pixels raster)
# convert the raster with usable pixels to polygon (must be an integer raster!)
tar_shp_file_name = os.path.abspath("") + "\\habitat\\habitat-area.shp"
habitat_polygons = geo.raster2polygon(os.path.abspath("") + "\\habitat\\habitat-pixels.tif",
tar_shp_file_name)
# calculate the habitat area (will be written to the attribute table)
calculate_habitat_area(habitat_polygons.GetLayer(), chsi_raster.epsg)
...Pour que la fonction calculate_habitat_area() produise ce que son nom promet, nous devons aussi remplir cette fonction. À cette fin, utilisez l’argument epsg integer pour identifier le système d’unité du fichier de formes.
# calculate_habitat_area.py
...
def calculate_habitat_area(layer, epsg):
# retrieve units
srs = geo.osr.SpatialReference()
srs.ImportFromEPSG(epsg)
area_unit = "square %s" % str(srs.GetLinearUnitsName()
...Pour déterminer la superficie de l’habitat, il faut calculer la superficie de chaque polygone. À cette fin, ajouter un nouveau champ à l’adresse layer dans la table Attribut, le nommer "area", et attribuer un type de données geo.ogr.OFTReal (numérique) (rappeler comment create a field an data types).
Puis, créez un vide Liste appelé poly_size, dans lequel nous écrirons la zone de tous les polygones qui ont une valeur de champ 1. Pour accéder aux polygones individuels (caractéristiques) du layer, itérer à travers toutes les fonctionnalités en utilisant une boucle for, qui:
Extrait le polygone de chaque
featureen utilisantpolygon = feature.GetGeometryRef()Ajoute la taille de la zone de polygone à l’adresse
poly_sizeListe si le champ"value"de l’adressepolygon(à la position 0:feature.GetField(0)) est 1 (True).Écrire la taille de la zone de polygone à la table Attribute avec
feature.SetField("area", polygon.GetArea().Enregistre les changements (zone de calcul) vers le fichier de forme
layeraveclayer.SetFeature(feature).
La dernière information nécessaire après la boucle for est la zone totale de la polygone "value"=1, que nous obtenons en écrivant la sum de la poly_size Liste à la console. Par conséquent, la deuxième et dernière partie de la fonction calculate_habitat_area ressemble à ceci:
# calculate_habitat_area.py
...
def calculate_habitat_area(layer, epsg):
... (extract unit system information)
# add area field
layer.CreateField(geo.ogr.FieldDefn("area", geo.ogr.OFTReal)
# create list to store polygon sizes
poly_size = []
# iterate through geometries (polygon features) of the layer
for feature in layer:
# retrieve polygon geometry
polygon = feature.GetGeometryRef()
# add polygon size if field "value" is one (determined by chsi_treshold)
if int(feature.GetField(0):
poly_size.append(polygon.GetArea()
# write area to area field
feature.SetField("area", polygon.GetArea()
# add the feature modifications to the layer
layer.SetFeature(feature)
# calculate and print habitat area
print("The total habitat area is {0} {1}.".format(str(sum(poly_size), area_unit)
...Exécuter le code de calcul de l’habitat utilisable¶
Une exécution réussie du script calculate_habitat_area.py devrait ressembler à ceci (en PyCharm):
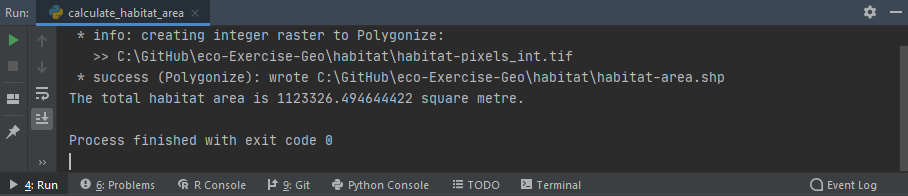
Figure 5:Exécution réussie du script calculer habitat area.py.
Plotté en QGIS, le fichier de forme habitat-area ressemble à ceci (utiliser la symbolique * catégorisé*):
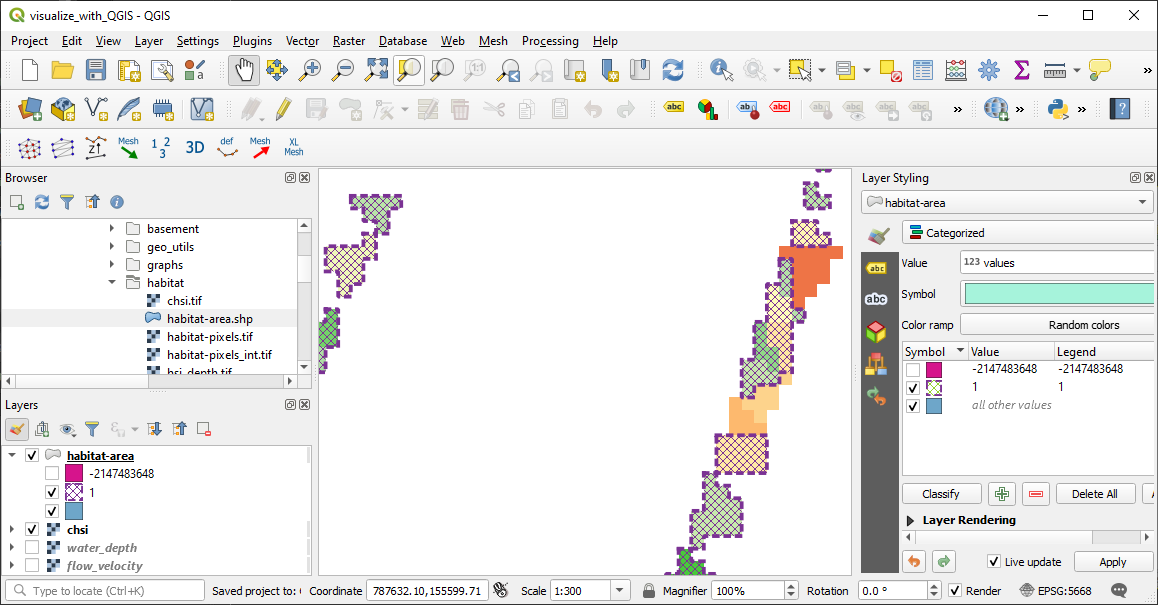
Figure 6:Le fichier de forme de la zone d’habitat tracé dans le SGQG avec la symbolique catégorisée, où la zone d’habitat utilisable ( 0,4) est délimitée par les taches mauves écloses et leurs contours en tirets.
Interprétation des résultats¶
The of the analyzed river section represents a very small share of the total wetted area, which can be interpreted as an ecologically poor status of the river. However, a glance at a map and the simulation files of the Flaz example of BASEMENT suggests that at a discharge of 50 m/s, a flood situation can be assumed. As during floods, there are generally higher flow velocities, which are out-of-favor of juvenile fish, the small usable habitat area is finally not surprising.
- Noack, M., Schneider, M., & Wieprecht, S. (2013). Ecohydraulics: an integrated approach (I. Maddock, A. Harby, P. Kemp, & P. Wood, Eds.; pp. 75–91). Wiley-Blackwell. 10.1002/9781118526576
- Bovee, K. D. (1986). Development and evaluation of Habitat Suitability Criteria for use in the instream flow incremental methodology (Techreport No. 21). National Ecology Center, U.S. Fish. https://pubs.er.usgs.gov/publication/70121265
- Stalnaker, C., Lamb, B. L., Henriksen, J., Bovee, K., & Bartholow, J. (1995). The Instream Flow Incremental Methodology - A Primer for IFIM. National Biological Service, U.S. Department of the Interior, Opler, Paul A. www.dtic.mil/cgi-bin/GetTRDoc?AD=ADA322762
- Yao, W., Bui, M. D., & Rutschmann, P. (2018). Development of eco-hydraulic model for assessing fish habitat and population status in freshwater ecosystems. Ecohydrology, 11(5), 1–17. 10.1002/eco.1961
- Tuhtan, J. A., Noack, M., & Wieprecht, S. (2012). Estimating stranding risk due to hydropeaking for juvenile European grayling considering river morphology. KSCE Journal of Civil Engineering, 16(2), 197–206. 10.1007/s12205-012-0002-5