Basic (text) file handling, NumPy, pandas, and DateTime. For interactive reading and executing code blocks  and find b06-pynum.ipynb or Python (Installation) locally along with JupyterLab.
and find b06-pynum.ipynb or Python (Installation) locally along with JupyterLab.
Watch this section in video format
Watch this section as a video on the @hydroinformatics channel on YouTube.
Charger et écrire des fichiers de données de base¶
Les données peuvent être stockées dans de nombreux formats de fichiers (texte) différents tels que txt ou csv. Python fournit les fonctions open(file) et write(...) pour lire et écrire les données de presque chaque format de fichier texte. En outre, il existe des paquets tels que csv (pour les fichiers csv), qui simplifient le traitement de types de fichiers spécifiques. Les sections suivantes illustrent l’utilisation des fonctions open(file) et write(...). Le module pandas montré plus tard fournit plus de fonctions pour importer et exporter des données numériques ainsi que des en-têtes de lignes et de colonnes.
Charger les données du fichier texte (ouvrir)¶
La commande open charge des fichiers texte comme objet de fichier dans Python. La syntaxe de la commande open est :
open("file-name", "mode")où:
file-nameest le fichier à ouvrir (par exemple,"data.txt"); si le fichier n’est pas dans le répertoire de script, le filename doit être étendu par le répertoire complet (chemin) au fichier de données (par exemple,"C:/experiment1/data.txt").modedéfinit le type d’accès et peut prendre les valeurs suivantes:"r"- en lecture seule (valeur par défaut si la valeur"mode"est fournie); le fichier ne peut être ni modifié ni écrasé."rb"- en lecture seule au format binaire; le format binaire est avantageux si le fichier n’est pas un fichier texte mais des médias tels que des images ou des vidéos."r+"- lire et écrire."w"- écrire seulement; un nouveau fichier est créé si un fichier avec lefile-namefourni n’existe pas encore."wb"- écrire seulement en mode binaire."w+"- créer, écrire et lire."wb+"- écrire et lire en mode binaire."a"- ajouter de nouvelles données à un fichier; le pointeur est placé à la fin du fichier et un nouveau fichier est créé si un fichier avec lefile namefourni n’existe pas encore."ab"- ajouter de nouvelles données en mode binaire."a+"- les deux appendices (écrire à la fin) et lire."ab+"- ajouter et lire les données en mode binaire.
Lorsque des modes "r" ou "w" sont utilisés, le pointeur du fichier (c.-à-d. le curseur clignotant que vous pouvez voir, par exemple, dans les documents Word) est placé au début du fichier. Pour les modes "a", le pointeur de fichier est placé à la fin du fichier.
Il est pratique de lire et d’écrire des données à partir d’un fichier dans une déclaration with pour éviter les problèmes de verrouillage de fichiers. Par exemple, le bloc de code suivant crée un nouveau fichier texte dans une déclaration with :
with open("data/new.csv", mode="w+") as file:
file.write("And yet it moves.")En lecture seule¶
Une fois l’objet de fichier créé, nous pouvons analyser le fichier et copier le contenu de données de fichier à un Python data type (par exemple, une liste, un tuple ou un dictionnaire). L’analyse des données fonctionne avec for-loops (d’autres types de boucles fonctionneront également) pour itérer sur les lignes et les entrées de ligne. Les lignes représentent strings et les colonnes de données peuvent être séparées en utilisant la fonction string intégrée line_as_list = str().split("SEPARATOR"), où "SEPARATOR" peut être "," (comma), ";" (semicolon), "\t" (tab), ou tout autre signe. Après avoir lu toutes les données d’un fichier, utilisez file_object.close() pour éviter que le fichier soit verrouillé par Python et ne puisse être ouvert par un autre programme.
L’exemple suivant ouvre un fichier texte appelé pure-numbers.txt (télécharger pur-numbers.txt dans un sous-dossier local appelé data) qui contient des numéros float entre 0,0 et 10,0. Le fichier comprend 17 lignes de données (p. ex., pour 17 essais expérimentaux) et 4 colonnes de données (p. ex., pour 4 mesures par essai expérimental), qui sont séparées par un TAB ("\t" séparateur). Le bloc de code ci-dessous utilise la fonction intégrée readlines() pour analyser les lignes de fichiers, divise les lignes en utilisant le séparateur "\t" et les boucles sur les entrées de ligne pour les ajouter à la variable de liste data_list seulement si entry est numérique (vérifié avec l’énoncé try - except). data_list est une liste imbriquée qui est lancée au début du script et une sous-liste (liste nested) est annexée pour chaque ligne de fichier (ligne).
file_object = open("data/pure-numbers.txt") # read file with default "mode"="r"
data_list = [] # this will be a nested list with 17 sub-lists (rows) containing 4 entries (columns)=
for line in file_object.readlines():
line_as_list = line.split("\t") # converts the line into a list using a tab (\t) separator
data_list.append([]) # append an empty sub-list for every file line (17 rows)
for entry in line_as_list:
try:
# try to append the entry as floating point number to the last sub-list, which is pointed at using [-1]
data_list[-1].append(float(entry))
except ValueError:
# if entry is not numeric, append 0.0 to the sub-list and print a warning message
print("Warning: %s is not a number. Replacing value with 0.0." % str(entry))
# verify that data_list contains the 17 rows (sub-lists) with the built-in list function __len__()
print("Number of rows: %d" % len(data_list))
# verify that the first sub-list has four entries (number of columns)
print("Number of columns: %d" % len(data_list[0]))
file_object.close() # close file (otherwise it will be locked as long as Python is still running!) alternative: use with-statement
print(data_list) # print the dataNumber of rows: 17
Number of columns: 4
[[2.202, 3.658, 0.201, 1.651], [0.904, 0.643, 1.094, 1.859], [2.104, 2.786, 2.212, 3.489], [1.181, 4.415, 0.331, 3.418], [2.203, 2.882, 0.874, 1.151], [4.044, 4.848, 1.704, 3.523], [4.407, 4.494, 0.608, 0.387], [1.015, 4.415, 0.672, 2.221], [4.798, 2.759, 3.521, 1.714], [3.495, 4.206, 0.288, 3.801], [4.947, 3.791, 1.546, 3.989], [0.695, 2.35, 4.561, 1.609], [1.581, 0.824, 0.293, 3.458], [1.216, 1.475, 2.56, 0.456], [2.956, 0.904, 3.029, 3.559], [0.691, 2.187, 3.533, 2.188], [0.44, 2.772, 3.386, 2.671]]
Créer et écrire des fichiers¶
Un fichier est créé avec les modes "w" ou "a" (par exemple, open(file_name, mode="a")).
Imaginez que le data_list ci-dessus représente les mesures en mm et nous savons que la précision du dispositif de mesure était de 1,0 mm. Ainsi, toutes les données inférieures à 1,0 se trouvent dans la marge d’erreur de l’appareil, que nous voulons exclure des analyses ultérieures en écraseant de telles valeurs avec nan (pas-a-number). À cette fin, nous créons d’abord une nouvelle variable de liste new_data_list, où nous ajoutons nan valeurs si data_list[i, j] <= 1.0 et sinon nous conservons la valeur numérique originale de data_list.
Avec open("data/modified-data.csv", mode="w+"), nous créons un nouveau fichier csv (valeurs séparées par des virgules) dans le sous-dossier data. Un for-loop iternise sur les sous listes de new_data_list et les rejoint avec un séparateur de virgules. Pour rejoindre les éléments de la liste i (i.e., les sous-listes) avec ", ".join(list_of_strings)", toutes les entrées de la liste doivent d’abord être converties en strings, ce qui est réalisé par l’expression [str(e) for e in row]. Le "\n" string doit être concaténé à la fin de chaque ligne pour créer une rupture de ligne ("\n" elle-même ne sera pas visible dans le fichier). La commande new_file.write(new_line) écrit la sous-liste convertie en chaîne au fichier "data/modified-data.csv". Une fois de plus, new_file.close() est nécessaire pour éviter que le nouveau fichier csv soit verrouillé par Python (autrement: utilisez un espace de nom dans une déclaration with).
# create a new list and overwrite all values <= 1.0 with nan
new_data_list = []
for i in data_list:
new_data_list.append([])
for j in i:
if j <= 1.0:
new_data_list[-1].append("nan")
else:
new_data_list[-1].append(j)
print(new_data_list)
# write the modified new_data_list to a new text file
new_file = open("data/modified-data.csv", mode="w+") # lets just use csv: Python does not care about the file ending (could also be file.wayne)
for row in new_data_list:
new_line = ", ".join([str(e) for e in row]) + "\n"
new_file.write(new_line)
new_file.close()
[[2.202, 3.658, 'nan', 1.651], ['nan', 'nan', 1.094, 1.859], [2.104, 2.786, 2.212, 3.489], [1.181, 4.415, 'nan', 3.418], [2.203, 2.882, 'nan', 1.151], [4.044, 4.848, 1.704, 3.523], [4.407, 4.494, 'nan', 'nan'], [1.015, 4.415, 'nan', 2.221], [4.798, 2.759, 3.521, 1.714], [3.495, 4.206, 'nan', 3.801], [4.947, 3.791, 1.546, 3.989], ['nan', 2.35, 4.561, 1.609], [1.581, 'nan', 'nan', 3.458], [1.216, 1.475, 2.56, 'nan'], [2.956, 'nan', 3.029, 3.559], ['nan', 2.187, 3.533, 2.188], ['nan', 2.772, 3.386, 2.671]]
Modifier les fichiers existants¶
Les fichiers texte existants peuvent être ouverts et modifiés soit à mode="r+" (en prétendant que l’information doit être lue avant qu’elle ne soit modifiée) soit à mode="a+". Rappelons que "r+" place le pointeur au début du fichier et "a+" place le pointeur à la fin du fichier. Ainsi, si nous voulons modifier les lignes ou les entrées d’un fichier existant, "r+" est le bon choix et si nous voulons ajouter des données à la fin du fichier, "a" est le bon choix (+ n’est pas strictement nécessaire dans le cas de "a"). Cette section présente deux exemples : 1) modification des données existantes dans un fichier en utilisant "r+", et 2) ajout de données à un fichier existant en utilisant "a".
- Exemple 1 - Remplacer les données dans un fichier existant par
"r+" Dans le bloc de code précédent, nous avons éliminé toutes les mesures inférieures à 1 mm en raison de la précision du dispositif de mesure. Cependant, nous avons conservé toutes les autres valeurs avec une précision à deux chiffres - une précision qui n’est pas donnée. Par conséquent, toutes les décimales des mesures doivent également être éliminées. Pour ce faire, nous devons arrondir toutes les valeurs mesurées avec la fonction ronde intégrée de Python (
round(number, n-digits)) à zéro décimale (i.e.,n-digits = 0). Dans cet exemple (qui figure dans le bloc de code ci-dessous), une exceptionIOErrorest soulevée lorsque le fichier"data/modified-data.csv"n’existe pas (ou s’il est verrouillé par un autre logiciel). Une déclarationifgarantit que l’arrondissement des données n’est tenté que si le fichier existe. La procédure d’écrasement lit d’abord toutes les lignes du fichier dans la variablelines. Après avoir lu toutes les lignes, le pointeur se trouve à la fin du fichier, etfile.seek(0)remet le pointeur à la position 0 (c’est-à-dire au début du fichier).file.truncate()purge le fichier. Ainsi, le fichier original est vide un instant et tout le contenu du fichier est stocké dans la variablelines. L’arrondi des données se produit dans un for-loop qui :Divise la ligne séparée par des virgules chaîne (produite
lines_as_list).Crée la liste temporaire
_numeric_line_, où les valeurs numériques arrondies sont stockées (la variable est écrasée dans chaque itération).Loops sur les entrées de ligne (
line_as_list), où une mention d’exception s’ajoute arrondie (à zéro chiffre), valeurs numériques et annexes"nan"lorsqu’une entrée n’est pas numérique.Écrire la ligne modifiée au fichier
"data/modified-data.csv"csv.
Enfin, le csv est fermé par modified_file.close().
try:
modified_file = open("data/modified-data.csv", mode="r+") # re-open the above data file in read-write
except IOError:
print("The file does not exist.")
if modified_file:
# go here only if the file exists
lines = modified_file.readlines() # read lines > pointer moves to file end
modified_file.seek(0) # return pointer to file beginning
modified_file.truncate() # clear file content
for line in lines:
line_as_list = line.split(", ") # converts the line into a list using comma separator
_numeric_line_ = []
for e in line_as_list:
try:
_numeric_line_.append(round(float(e), 0)) # try to convert line entry to float and round to 0 digits
except ValueError:
_numeric_line_.append(e) # for nan values
# write rounded values
modified_file.write(", ".join([str(e) for e in _numeric_line_]) + "\n")
print("Processed file." )
modified_file.close()
Processed file.
Théoriquement, l’extrait de code ci-dessus peut être réécrit comme une fonction pour modifier toutes les données dans un fichier. De plus, d’autres valeurs seuils ou des plages de données particulières peuvent être filtrées à l’aide d’instructions if - else.
- Exemple 2 - Ajouter les données à un fichier existant avec
"a+" - Par coïncidence, vous trouvez un protocole de mesure manuscrit qui a des données d’un 18ème essai, qui n’est pas dans le fichier de données de mesure électronique en raison d’une erreur de transmission de données. Maintenant, vous voulez ajouter les données au fichier csv ci-dessus produit. L’entrée des données ne prend pas beaucoup de travail, car seulement 4 mesures ont été effectuées par essai et le bloc de code ci-dessous contient les données manuscrites dans une variable de liste appelée
forgotten_data. Cet exemple utilise le moduleos(rappel Paquets, modules et bibliothèques) pour vérifier si le fichier de données existe avecos.path.isfile()(l’énoncéos.getcwd()est un gadget ici). Le bloc de code comporte l’utilisation d’une déclarationwith(i.e., unwith- gestionnaire de contexte ou espace de noms).
La partie essentielle du code qui écrit la ligne au fichier de données est file.write(line), où line correspond à l’introduction ci-dessus ", ".join(list-of-strings) + "\n" string.
import os
print(os.getcwd())
forgotten_data = [4.0, 3.0, "nan", 8.0]
if os.path.isfile("data/modified-data.csv"):
with open("data/modified-data.csv", mode="a") as file_object:
file_object.write(", ".join([str(e) for e in forgotten_data]) + "\n")
print("Data appended.")
else:
print("The file does not exist.")/home/schwindt/github/hyhome-v2/jupyter
Data appended.
NombrePy¶
NumPy fournit des fonctions mathématiques de haut niveau pour l’algèbre linéaire, y compris des opérations sur des matrices et des matrices multidimensionnelles. La bibliothèque open-source NumPy (pour Python numérique) est écrite en Python et [C](C (programming language)], et est accompagnée d’une documentation complète (télécharger la dernière version sur le site Web du développeur ou lire le tutoriel en ligne du développeur).
Watch the NumPy section in video format
Watch this section as a video on the @hydroinformatics channel on YouTube.
Installation¶
NumPy peut être installé via Anaconda (recall instructions) et les développeurs recommandent d’utiliser une distribution Python scientifique (Anaconda) avec SciPy Stack.
Anaconda environment.yml (flussenv) comprend déjà NumPy (plus d’information dans la section installation). De même, les utilisateurs de Linux auront NumPy installé dans un environnement virtuel (par exemple vflussenv) avec pip (rappel pip-installing flusstools). Sinon, pour installer NumPy dans tout autre environnement conda, ouvrez Anaconda Prompt (Start > type Anaconda Prompt) et tapez:
conda activate ENVIRONMENT-NAME
conda install numpyPour pip-installer NumPy dans tout autre clic d’environnement virtuel :
pip install numpyUtilisation¶
La bibliothèque NumPy est généralement importée avec import numpy as np. La manipulation des rayons est le fondement de NumPy et de l’algèbre linéaire, où les tableaux représentent une sorte de liste de données imbriquées. Pour créer un tableau NumPy, utilisez np.array((values)), où values est une séquence de valeurs.
Le bloc de code suivant montre l’utilisation très basique de NumPy (ou: numpy) importé comme np et la création d’un tableau de numpy 2x3. Les parenthèses arrondies indiquent que la séquence de valeur de la np.array représente un tuple pour créer un tableau multidimensionnel.
import numpy as np
an_array = np.array(([2, 3, 1], [4, 5, 6]))
print(an_array)[[2 3 1]
[4 5 6]]
Les tableaux NumPy (type de données : ndarray) ont de nombreuses fonctionnalités intégrées, par exemple pour afficher la taille du tableau :
print(type(an_array))
print("Array dimensions: " + str(an_array.shape))
print("Total number of array elements: " + str(an_array.size))
print("Number of array axes: " + str(an_array.ndim))<class 'numpy.ndarray'>
Array dimensions: (2, 3)
Total number of array elements: 6
Number of array axes: 2
Il existe de nombreux types de np.arrays et de nombreuses façons de les créer:
print(np.array([(2, 3, 1), (4, 5, 6)])) # the same as an_array
print(np.array([[2, 3, 1], [4, 5, 6]], dtype=complex))[[2 3 1]
[4 5 6]]
[[2.+0.j 3.+0.j 1.+0.j]
[4.+0.j 5.+0.j 6.+0.j]]
Des tableaux de zéros, de zéros ou de tableaux vides peuvent être créés avec des types de données integer ou float. Lors de la création de tels tableaux, soyez conscient de l’utilisation de tuples (c.-à-d. des séquences embrassées avec des parenthèses arrondies) pour définir les dimensions du tableau :
print(np.zeros((2,6)))
print(np.ones((2,6), dtype=np.float64)) # other dtypes: int16, np.int16, float, np.float32, np.complex64
print(np.empty((2,6)))
print(np.empty((2,6), dtype=np.int16))[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
[[1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1.]]
[[1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1.]]
[[19880 11437 6 0 0 0]
[ 0 0 0 0 0 0]]
NumPy fournit la fonction arange(start, end, step-size) pour créer des séquences numériques. De telles séquences représentent des tableaux (ndarray) qui peuvent ensuite être remodelés (c.-à-d. réorganisés en colonnes et en lignes).
print("1D array:")
print(np.arange(0, 10, 2)) # 1D array
print("\n2D array:")
print(np.arange(0, 12, 2).reshape(2, 3)) # 2D array
print("\n3D array:")
print(np.arange(1, 13, 1).reshape(2, 2, 3)) # 3D array
print("\n1D Linspace (start, end, number-of-elements):")
print(np.linspace(0, np.pi, 3))1D array:
[0 2 4 6 8]
2D array:
[[ 0 2 4]
[ 6 8 10]]
3D array:
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
1D Linspace (start, end, number-of-elements):
[0. 1.57079633 3.14159265]
Des nombres aléatoires peuvent être générés avec le générateur de nombres aléatoires de NumPy np.random et sa fonction .random(range_tuple).
rand_array = np.random.random((2,4))
print(rand_array)[[0.78599116 0.11777177 0.29913723 0.9290063 ]
[0.70878365 0.5521523 0.81552564 0.17867719]]
Les fonctions de tableau intégrées permettent de trouver des valeurs minimales ou maximales, ou des sommes de tableaux :
print("Sum of 12-elements ones-array: " + str(np.ones((2,6)).sum()))
print("Minimum: " + str(an_array.min()))
print("Maximum: " + str(an_array.max()))Sum of 12-elements ones-array: 12.0
Minimum: 1
Maximum: 6
Tableaux de couleurs¶
Les tableaux peuvent également contenir des informations de couleur, où les couleurs représentent un mélange des trois couleurs de base rouge, vert et bleu (RGB). Ainsi, une couleur peut être définie comme [red-value, green-value, blue-value], et une valeur de 0 signifie qu’une tonalité de couleur n’est pas présente, alors que 255 est sa valeur maximum. Il n’y a pas de couleur lorsque toutes les couleurs sont nulles, ce qui correspond à noir; lorsque toutes les couleurs sont maximales (255), le mélange de couleurs correspond à blanc. De cette façon, les éléments de tableau peuvent être des listes de tons de couleur, et le tracé de tels tableaux produit des images. L’exemple suivant produit un tableau avec 5 éléments de liste de couleurs, qui pourrait être tracé comme une image très basique avec 5 pixels (un noir, rouge, vert, bleu et blanc, respectivement):
color_set = np.array([[0, 0, 0], # black
[255, 0, 0], # red
[0, 255, 0], # green
[0, 0, 255], # blue
[255, 255, 255]]) # whiteOpérations d’array (Matrix)¶
Les calculs d’array (opérations de matrice) suivent les règles de l’algèbre linéaire:
A = np.random.random((2,4))
B = np.random.random((4,2))
print("Subtraction: " + str(A.transpose() - B))
print("Element-wise product: " + str(A.transpose() * B))
print("Matrix product (option 1): " + str(A @ B))
print("Matrix product (option 2): " + str(A.dot(B)))Subtraction: [[ 0.39513798 0.92256882]
[ 0.34627686 -0.64066838]
[-0.41525172 0.49672182]
[-0.64648598 0.21224637]]
Element-wise product: [[0.02631898 0.05370238]
[0.2312502 0.07207233]
[0.28977301 0.14078519]
[0.10386917 0.18425933]]
Matrix product (option 1): [[0.65121136 0.64929413]
[1.06516605 0.45081924]]
Matrix product (option 2): [[0.65121136 0.64929413]
[1.06516605 0.45081924]]
D’autres calculs par élément incluent exponentielle (**), géométrique (np.sin, np.cos, np.tan, etc.), et opérateurs booléens:
print("A to the power of 3: " + str(A**3))
print("Exponential: " + str(np.exp(A)))
print("Square root: " + str(np.sqrt(A)))
print("Sine of A times 3: " + str(np.sin(A) * 3))
print("Boolean where A is smaller than 0.3: " + str(A < 0.3))A to the power of 3: [[9.30892075e-02 3.20353634e-01 5.03795493e-02 2.36414082e-03]
[9.34027227e-01 9.30307166e-04 3.40544706e-01 1.64838161e-01]]
Exponential: [[1.57335504 1.9822692 1.44676927 1.14249724]
[2.65782184 1.10254456 2.01038396 1.73031119]]
Square root: [[0.67320896 0.82718937 0.60772772 0.36498826]
[0.9886895 0.31244319 0.83565886 0.74047368]]
Sine of A times 3: [[1.313562 1.89625803 1.08298042 0.39846826]
[2.48731829 0.29239731 1.9288087 1.56371481]]
Boolean where A is smaller than 0.3: [[False False False True]
[False True False False]]
Manipulation en forme d’array¶
Parfois, il est nécessaire d’empiler un tableau multidimensionnel dans un vecteur ou de refonder la forme d’un tableau. Au-delà de la fonction reshape(), il y a quelques autres options pour manipuler la forme d’un tableau :
print("Flattened matrix A (into a vector):\n" + str(A.ravel()))
print("\nTranspose matrix A and append B:\n" + str(np.array([A.transpose(), B])))
print("\nTranspose matrix A and append B and cast into a (4x4) array:\n" + str(np.array([A.transpose(), B]).reshape(4,4)))Flattened matrix A (into a vector):
[0.45321031 0.68424225 0.36933298 0.13321643 0.97750693 0.09762075
0.69832573 0.54830127]
Transpose matrix A and append B:
[[[0.45321031 0.97750693]
[0.68424225 0.09762075]
[0.36933298 0.69832573]
[0.13321643 0.54830127]]
[[0.05807233 0.05493811]
[0.33796539 0.73828912]
[0.78458471 0.20160391]
[0.77970241 0.33605491]]]
Transpose matrix A and append B and cast into a (4x4) array:
[[0.45321031 0.97750693 0.68424225 0.09762075]
[0.36933298 0.69832573 0.13321643 0.54830127]
[0.05807233 0.05493811 0.33796539 0.73828912]
[0.78458471 0.20160391 0.77970241 0.33605491]]
NumPy Traitement de fichiers et np.nan¶
Dans les exemples ci-dessus sur le traitement des fichiers, les données de mesure ont été chargées à partir de fichiers texte, manipulées (modifiées) et (ré)écrites. La manipulation des données impliquait l’introduction de valeurs "nan" (not-a-number), qui ont été exclues parce que les mesures <1 mm étaient considérées comme des erreurs. Pourquoi n’avons-nous pas utilisé des zéros ici ? Les zéros sont aussi des nombres et ont un effet significatif sur les statistiques de données (p. ex. pour le calcul des valeurs moyennes). Cependant, la valeur "nan" string peut causer des difficultés dans le traitement des données, en particulier en ce qui concerne la cohérence de la sortie de fonction. NumPy fournit le type de données np.nan une alternative puissante à la fastidieux "nan" string.
NumPy a également une fonction de chargement de fichiers texte appelée np.loadtxt(file-name, *args, **kwargs), qui importe des fichiers texte comme np.arrays de valeurs float. Le type de valeur float par défaut peut être adapté avec le mot clé optionnel dtype. Les autres paramètres optionnels sont :
delimiter=STR(par exemple,delimiter=';'), où la valeur par défaut est"None"usecols=TUPLE(e.g.,usecols=(1, 3)extracts the 2nd and 4th column), where also one integer value is possible to read just on single columnskiprows=INT(par exemple,skiprows=2passe les deux premières lignes), où la valeur par défaut est0d’autres arguments sont disponibles et listés dans la documentation NumPy.
L’exemple suivant charge le fichier csv créé ci-dessus data/modified-data.csv contenant integer et "nan" string, qui sont automatiquement convertis en np.nan.
experiment_data = np.loadtxt("data/modified-data.csv", delimiter=",")
print("This is the data 4th line (row): " + str(experiment_data[3, :]))
print("The data type of the 3rd (%s) entry is: " % str(experiment_data[3, 2]) + str(type(experiment_data[3, 2])))This is the data 4th line (row): [ 1. 4. nan 3.]
The data type of the 3rd (nan) entry is: <class 'numpy.float64'>
En outre, ou comme alternative, la fonction np.load() ramasse les données à partir de fichiers comme .npz, .npy, ou ramassés (objets Python sauvés) sources de données (plus d’informations sont disponibles dans le NumPy docs).
Statistiques¶
Les exemples ci-dessus comprenaient des fonctions de tableau pour évaluer les statistiques de base de tableau telles que le minimum et le maximum. NumPy fournit beaucoup plus de fonctions pour les statistiques de tableau telles que la moyenne, la médiane ou l’écart-type, y compris les fonctions qui comptent pour np.nan valeurs. L’exemple suivant illustre certaines des fonctions statistiques avec les données expérimentales des exemples ci-dessus. Notez l’utilisation de nanmean au lieu de mean et les statistiques le long de l’axe du tableau, où l’argument optionnel axis=0 correspond aux colonnes et axis=1 aux statistiques le long des lignes dans les tableaux à deux dimensions (le numéro d’axe maximal correspond aux dimensions du tableau n moins 1, c’est-à-dire le maximum axis=n-1).
print("Mean value (without nan): " + str(np.mean(experiment_data))) # no applicable result
print("Mean value with np.nan: " + str(np.nanmean(experiment_data)))
print("Mean value along axis 0 (columns): " + str(np.nanmean(experiment_data, axis=0)))
print("Mean value along axis 1 (rows): " + str(np.nanmean(experiment_data, axis=1))) Mean value (without nan): nan
Mean value with np.nan: 3.018181818181818
Mean value along axis 0 (columns): [2.78571429 3.26666667 2.9 3.0625 ]
Mean value along axis 1 (rows): [2.66666667 1.5 2.5 2.66666667 2. 3.75
4. 2.33333333 3.5 3.66666667 3.75 3.
2.5 1.66666667 3.33333333 2.66666667 3. 5. ]
Les paragraphes suivants présentent un tableau des fonctions statistiques dans NumPy (source : NumPy docs). Les fonctions listées ne représentent que la base de référence et NumPy fournit beaucoup plus d’options, qui peuvent être utilisées à l’aide de n’importe quel moteur de recherche avec NumPy et la fonction souhaitée comme mot-clé de recherche.
Fonctions statistiques de base
| Function | Description |
|---|---|
nanmin(a[, axis, out, keepdims]) | Minimum of an array or along an axis, ignoring np.nan. |
nanmax(a[, axis, out, keepdims]) | Maximum of an array or along an axis, ignoring np.nan. |
ptp(a[, axis, out]) | Range of values (max - min) along an axis. |
percentile(a, q[, axis, out, ...]) | q-th percentile of data along a specified axis. |
nanpercentile(a, q[, axis, out, ...]) | q-th percentile of data along a specified axis, ignoring np.nan. |
Moyenne (moyenne), écart type et variances
| Function | Description |
|---|---|
median(a[, axis, out, overwrite_input, keepdims]) | Median along an (optional) axis. |
average(a[, axis, weights, returned]) | Weighted average along an (optional) axis. |
mean(a[, axis, dtype, out, keepdims]) | Arithmetic mean along an (optional) axis. |
std(a[, axis, dtype, out, ddof, keepdims]) | Standard deviation along an (optional) axis. |
var(a[, axis, dtype, out, ddof, keepdims]) | Variance along an (optional) axis. |
nanmedian(a[, axis, out, overwrite_input, ...]) | Median along an (optional) axis, ignoring np.nan. |
nanmean(a[, axis, dtype, out, keepdims]) | Arithmetic mean along an (optional) axis, ignoring np.nan. |
nanstd(a[, axis, dtype, out, ddof, keepdims]) | Standard deviation along an (optional) axis, while ignoring np.nan. |
Données corrélatives
| Function | Description |
|---|---|
corrcoef(x[, y, rowvar, bias, ddof]) | Pearson (product-moment) correlation coefficients. |
correlate(a, v[, mode]) | Cross-correlation of two 1-dimensional sequences. |
cov(m[, y, rowvar, bias, ddof, fweights, ...]) | Estimate covariance matrix, based on data and weights. |
Générer et tracer des histogrammes
| Function | Description |
|---|---|
histogram(a[, bins, range, normed, weights, ...]) | Histogram of a set of data. |
histogram2d(x, y[, bins, range, normed, weights]) | Bi-dimensional histogram of two data samples. |
histogramdd(sample[, bins, range, normed, ...]) | Multidimensional histogram of some data. |
bincount(x[, weights, minlength]) | Count number of occurrences of each value in array of non-negative ints. |
digitize(x, bins[, right]) | Indices of the bins to which each value in input array belongs. |
Est-ce que NumPy peut faire MATLAB®?¶
Envisagez-vous de passer à Python après avoir commencé doucement dans la programmation avec MATLAB®-like software? Il y a de nombreuses raisons d’améliorer les analyses de données avec Python et voici quelques facilitateurs pour les utilisateurs précédents MATLAB® :
MATLAB® matrices can be loaded and saved with
scipy.io.loadmat(matrix-file-name)(useimport scipy).NumPy
np.arrayremplace MATLAB® notation matricielle (même s’il y a le type de données historique et obsolète NumPynp.matrix).Importez de nombreuses fonctions MATLAB® à partir de
np.matlib(p. ex.,from numpy.matlib import rand, zeros, ones, empty, eye)ou plus généralementimport numpy.matlib as M).Trouvez l’équivalent NumPy de beaucoup MATLAB® dans la fonction NumPy documentation.
Pour imiter MATLAB® les fonctions de l’intrigue utilisent le paquet
pylabet l’importent commefrom pylab import *.
⚠ Ceci écrase toutes les autres définitions (standard) de la fonctionplot()etarray()objets. Cette utilisation est donc obsolète. Lire la section de tracé pour des instructions complètes de tracé avec Python.
MATLAB® est une marque déposée de The MathWorks.
Pandas¶
pandas est une puissante bibliothèque d’analyse et de manipulation de données avec Python. Il peut gérer les tableaux NumPy et les deux paquets représentent conjointement un puissant moteur de traitement de données. La puissance de pandas réside dans le traitement des cadres de données, l’étiquetage des données (p. ex., noms de colonnes ressemblant à des cahiers) et les fonctions de traitement de fichiers flexibles (p. ex., la fonction intégrée read_csv(csv-file)). Alors que les tableaux NumPy permettent des calculs avec des tableaux multidimensionnels (au-delà des tables à 2 dimensions) et une faible consommation de mémoire, pandas DataFrames traite efficacement et étiquette les données tabulaires avec plus de ~100 000 lignes. En raison de sa capacité d’étiquetage, pandas trouve également une large application dans l’apprentissage automatique. En résumé, la fonctionnalité de pandas s’appuie sur celle de NumPy et les deux bibliothèques sont maintenues par la communauté SciPy (Outils de calcul scientifiques pour Python) qui produit également matplotlib (voir plotting section) et IPython (Le noyau Python de Jupyter).
Watch the pandas section on YouTube
Watch this section as a video on the @hydroinformatics channel on YouTube.
Installation¶
Pandas peut être installé par l’intermédiaire de Anaconda (recall instructions) et les développeurs recommandent d’utiliser une distribution Python scientifique (Anaconda) avec SciPy Stack.
Anaconda environment.yml (flussenv) comprend déjà pandas (plus d’information dans la section installation). De même, les utilisateurs de Linux auront pandas installé dans un environnement virtuel (par exemple vflussenv) avec pip (rappel pip-installing flusstools). Sinon, pour installer pandas dans tout autre environnement conda, ouvrez Anaconda Prompt (Start > type Anaconda Prompt) et tapez:
conda activate ENVIRONMENT-NAME
conda install pandasPour pip-installer pandas dans n’importe quel autre bouton d’environnement virtuel :
pip install pandasUtilisation¶
*Le pseudonyme standard d’importation est pd: import pandas as pd. Les sections suivantes donnent un aperçu des fonctions de base de pandas et beaucoup d’autres fonctionnalités sont documentées dans le documents du développeur.
Cadres et séries de données¶
Le bloc de code ci-dessous illustre une façon de créer un cadre de données pandas (pd.DataFrame), l’un des objets de base pandas. Noter la différence entre une série 1-dimensionnelle pd.Series (correspond à un cadre de données d’une colonne) et un cadre de données n-dimensionnel avec row (=index) et des noms de colonnes. Les lignes de noms de lignes par défaut commençant par 0 (contrairement au logiciel Office qui commence à la ligne no 1), sans noms de colonnes. Les noms de colonnes peuvent être initialement définis comme un list et remplacés par un dictionary qui cartographie les entrées initiales de la liste vers de nouveaux noms.
import pandas as pd
print("A 1-column pd.DataFrame:\n"+ str(pd.Series([3, 4, np.nan]))) # a simple pandas data frame with one column
row_names = np.arange(1, 4, 1)
wb_like_df = pd.DataFrame(np.random.randn(len(row_names), 3),
index=row_names, columns=['A', 'B', 'C'])
print("\nThis is a workbook-like (row and column names) data frame:\n" + str(wb_like_df))
print("\nRename column names with dictionary:\n" + str(wb_like_df.rename(
columns={'A': 'Series 1', 'B': 'Series 2', 'C': 'Series 3'})))
print("\nTranspose the data frame:\n" + str(wb_like_df.T))A 1-column pd.DataFrame:
0 3.0
1 4.0
2 NaN
dtype: float64
This is a workbook-like (row and column names) data frame:
A B C
1 -0.374896 1.510560 0.164615
2 0.171686 -0.668994 -1.850155
3 -0.521211 1.688967 -0.653523
Rename column names with dictionary:
Series 1 Series 2 Series 3
1 -0.374896 1.510560 0.164615
2 0.171686 -0.668994 -1.850155
3 -0.521211 1.688967 -0.653523
Transpose the data frame:
1 2 3
A -0.374896 0.171686 -0.521211
B 1.510560 -0.668994 1.688967
C 0.164615 -1.850155 -0.653523
Un objet pandas DataFrame peut également être créé à partir d’un objet dictionary, où les clés du dictionnaire définissent les noms de colonnes et les valeurs du dictionnaire constituent les données de chaque colonne:
df = pd.DataFrame({'Flow depth': pd.Series(np.random.uniform(low=0.1, high=0.3, size=(4,)), dtype='float32'),
'Sediment': ["yes", "no", "yes", "no"],
'Flow regime': pd.Categorical(["fluvial", "fluvial", "supercritical", "critical"]),
'Water': "Always there"})
print("A dictionary-built data frame:\n" + str(df))
print("\nFrame data types:\n" + str(df.dtypes))A dictionary-built data frame:
Flow depth Sediment Flow regime Water
0 0.236444 yes fluvial Always there
1 0.212434 no fluvial Always there
2 0.121081 yes supercritical Always there
3 0.290556 no critical Always there
Frame data types:
Flow depth float32
Sediment str
Flow regime category
Water str
dtype: object
Les attributs et les méthodes intégrés d’un pandas DataFrame permettent d’accéder facilement au haut (en tête) et au bas d’un cadre de données et beaucoup d’autres caractéristiques de l’objet (appelez : utilisez dir(dict_df) ou lisez le docs du développeur) :
print("Head of the dictionary-based dataframe (first two rows):\n" + str(df.head(2)))
print("\nEnd (tail) of the dictionary-based dataframe (last row):\n" + str(df.tail(1)))Head of the dictionary-based dataframe (first two rows):
Flow depth Sediment Flow regime Water
0 0.236444 yes fluvial Always there
1 0.212434 no fluvial Always there
End (tail) of the dictionary-based dataframe (last row):
Flow depth Sediment Flow regime Water
3 0.290556 no critical Always there
Exemple : Créer un pandas.DataFrame des numéros Froude¶
Dans l’hydraulique, le Froude number caractérise le régime de débit comme “fluvial” (Fr<1), “critique” (Fr=1), ou “supercritique” (Fr>1). La précision des dispositifs de mesure dans les expériences de flume physique fait de la détermination exacte du moment critique un défi et force les chercheurs à appliquer un intervalle autour de 1, plutôt que la valeur exacte de 1.0:
*Contrôle de l’écoulement quasi critique (lent)
pd.DataFrame( ... ) les objets sont un moyen pratique de classer et stocker les données d’expérience de flume:
Fr_dict = {0.925: "fluvial", 0.975: "near-critical (slow)", 1.0: "critical", 1.025: "near-critical (fast)", 1.075: "super-critical"}
Fr_measured = np.random.uniform(low=0.01, high=2.00, size=(10,))
Fr_classified = [Fr_dict[min(Fr_dict.keys(), key=lambda x:abs(x-m))] for m in Fr_measured]
obs_df = pd.DataFrame({"measured": Fr_measured, "flow regime": Fr_classified})
print(obs_df) measured flow regime
0 0.722820 fluvial
1 1.099443 super-critical
2 0.886570 fluvial
3 0.849089 fluvial
4 1.175042 super-critical
5 0.086024 fluvial
6 1.157518 super-critical
7 1.606757 super-critical
8 1.541139 super-critical
9 0.189163 fluvial
Ajouter les données à un pandas.DataFrame¶
Les méthodes at, loc, concat et append de pandas offrent des options directes pour insérer des lignes ou des colonnes dans un pd.DataFrame. Cependant, ces méthodes intégrées sont approximativement un ordre de grandeur plus lent que de prendre le détour via un dictionnaire. Ceci s’applique en particulier aux cadres de données contenant plus de 10 000 éléments. Cela signifie que la méthode la plus rapide pour insérer des données dans un pd.DataFrame est:
Convertissez un objet existant
pd.DataFrameen dictionnaire avecpd.DataFrame.to_dict()(par exemple,dict_of_df = df.to_dict()).Mettre à jour le dictionnaire* avec les nouvelles données
Ajouter des lignes avec
dict_of_df.update({"existing-column-name": {"new-row-name": NEW_DATA}})Ajouter des colonnes avec
dict_of_df.update({"new-column-name": {"existing-row-name": NEW_DATA}})
Reconvertir le dictionnaire* à
pd.DataFrameavecdf = pd.DataFrame.from_dict(dict_of_df)
Le bloc de code suivant illustre à la fois l’ajout d’une ligne et d’une colonne à un cadre de données pandas existant.
import random
# convert data frame to dictionary
dict_of_obs_df = obs_df.to_dict()
# append new row
new_row_index = max(dict_of_obs_df["measured"]) + 1
dict_of_obs_df["measured"].update({new_row_index: 0.996})
dict_of_obs_df["flow regime"].update({new_row_index: "near-critical (slow)"})
# append column
dict_of_obs_df.update({"with sediment": {}})
for k in dict_of_obs_df["measured"].keys():
dict_of_obs_df["with sediment"].update({k: bool(random.getrandbits(1))})
# re-build data frame
obs_df = pd.DataFrame.from_dict(dict_of_obs_df)
print(obs_df.tail(3)) measured flow regime with sediment
8 1.541139 super-critical True
9 0.189163 fluvial False
10 0.996000 near-critical (slow) False
Tableaux et cadres de données¶
Une différence majeure entre un NumPy array et un pandas DataFrame est que les tableaux NumPy ne peuvent avoir qu’un seul type de données (dtype), tandis qu’un pandas DataFrame peut avoir différents types de données (un dtype par colonne). C’est pourquoi un NumPy array peut être facilement converti en pandas DataFrame, mais la conversion inverse peut causer un coût de calcul élevé: pandas est livré avec une fonction intégrée pour convertir un pandas DataFrame en NumPy array, où les variables numériques sont maintenues lorsque possible. Si une colonne du pandas DataFrame n’est pas numérique, la conversion implique la copie de l’objet, ce qui entraîne des coûts de calcul élevés. Notez que les étiquettes index et colonne d’un pandas DataFrame sont perdues dans la conversion de pd.DataFrame à np.ndarray.
print(obs_df.to_numpy())[[0.7228199423430681 'fluvial' True]
[1.0994432843154105 'super-critical' True]
[0.8865704358418128 'fluvial' False]
[0.8490886765821513 'fluvial' True]
[1.1750423214539258 'super-critical' True]
[0.086024140985809 'fluvial' True]
[1.1575177959070637 'super-critical' True]
[1.6067571441117197 'super-critical' False]
[1.5411388862372846 'super-critical' True]
[0.18916310404617928 'fluvial' False]
[0.996 'near-critical (slow)' False]]
Accès aux bases de données¶
Les éléments des cadres de données sont accessibles par l’étiquette de la colonne et de la ligne (df.loc[index=row, column-label]) ou par le numéro (df.iloc):
print("Label localization results in: " + str(df.loc[2, "Flow depth"]))
print("Same result with integer grid location: " + str(df.iloc[2, 0]))Label localization results in: 0.12108062
Same result with integer grid location: 0.12108062
Remodeler les cadres de données¶
Des lignes simples ou multiples (indices) et des colonnes peuvent être extraites et combinées en objets nouveaux ou existants DataFrame:
print(pd.DataFrame([df["Flow depth"], df["Sediment"]])) 0 1 2 3
Flow depth 0.236444 0.212434 0.121081 0.290556
Sediment yes no yes no
The df.stack() method pivots the columns of a data frame, which is a powerful tool to classify data that can take different dimensions (e.g., the volume and weight of 1 m3 water - read more about the stack method).
print(df.stack()[0])
df.unstack() # unstack data frameFlow depth 0.236444
Sediment yes
Flow regime fluvial
Water Always there
dtype: object
Flow depth 0 0.236444
1 0.212434
2 0.121081
3 0.290556
Sediment 0 yes
1 no
2 yes
3 no
Flow regime 0 fluvial
1 fluvial
2 supercritical
3 critical
Water 0 Always there
1 Always there
2 Always there
3 Always there
dtype: objectLes ensembles de données volumineuses contiennent souvent de grandes quantités de données avec de nombreuses étiquettes, mais nous ne sommes souvent intéressés que par un petit sous-ensemble de données. À cette fin, des sous-ensembles de données peuvent être créés avec df.pivot(index, columns, **values) (Méthode Pivot):
print("Pivot table for \'Flow regime\':\n" + str(df.pivot(index="Sediment", columns="Flow depth")["Flow regime"]))
print("\nPivot table for \'Water\':\n" + str(df.pivot(index="Sediment", columns="Flow depth")["Water"]))Pivot table for 'Flow regime':
Flow depth 0.121081 0.212434 0.236444 0.290556
Sediment
no NaN fluvial NaN critical
yes supercritical NaN fluvial NaN
Pivot table for 'Water':
Flow depth 0.121081 0.212434 0.236444 0.290556
Sediment
no NaN Always there NaN Always there
yes Always there NaN Always there NaN
En outre, df.pivot_table(index, columns, values, aggfunc) (Pivot table function) permet une application de fonction en ligne de type Office à une ou plusieurs lignes et/ou colonnes.
print("\'mean\' for \'Flow depth\':\n" + str(df.pivot_table(index="Sediment", columns="Flow regime", values="Flow depth", aggfunc=np.mean)))'mean' for 'Flow depth':
Flow regime critical fluvial supercritical
Sediment
no 0.290556 0.212434 NaN
yes NaN 0.236444 0.121081
En savoir plus sur le remaniement et le pivotement des cadres de données dans le docs du développeur.
Traitement des dossiers (csv, cahiers de travail et plus)¶
pandas peut lire et écrire de nombreux types de fichiers de données, ce qui le rend extrêmement puissant pour analyser toutes les données. Le tableau suivant résume les types de fichiers les plus importants pour l’analyse des paysages numériques hydrauliques, morphodynamiques et fluviaux, et d’autres gestionnaires de types de fichiers peuvent être trouvés au developer’s docs.
| File type | pandas read | pandas write | Usage example |
|---|---|---|---|
| CSV | read_csv | to_csv | Reading from data loggers (e.g., discharge, flow depth) |
| Google BigQuery | read_gbq | to_gbq | Analyze social media |
| JSON | read_json | to_json | Manipulate BASE model files |
| HTML | read_html | to_html | Process web site data |
| HDF5 Format | read_hdf | to_hdf | Analyze BASE or HEC-RAS output files |
| Python Pickle Format | read_pickle | to_pickle | Cache memory dump |
| SQL | read_sql | to_sql | Retrieve and write data to SQL data bases |
| Workbooks (Excel / Open doc) | read_excel | to_excel | Interface with non-programmers (Open only works in read mode) |
The following code block illustrates how the above produced data/modified-data.csv file can be loaded and saved to a workbook with pandas. pandas uses openpyxl by default, but this usage varies depending on the workbook file type (e.g., .ods, .xls, and xlsb build on other packages - read more about the engine keyword).
measurement_data = pd.read_csv("data/modified-data.csv", sep=",", header=None, names=["Test 1", "Test 2", "Test 3", "Test 4"])
print("Header of data/modified-data.csv:\n" + str(measurement_data.head(3)))
measurement_data.to_excel("data/modified-data-wb.xlsx", sheet_name="2025-01-01 Tests")Header of data/modified-data.csv:
Test 1 Test 2 Test 3 Test 4
0 2.0 4.0 nan 2.0
1 NaN nan 1.0 2.0
2 2.0 3.0 2.0 3.0
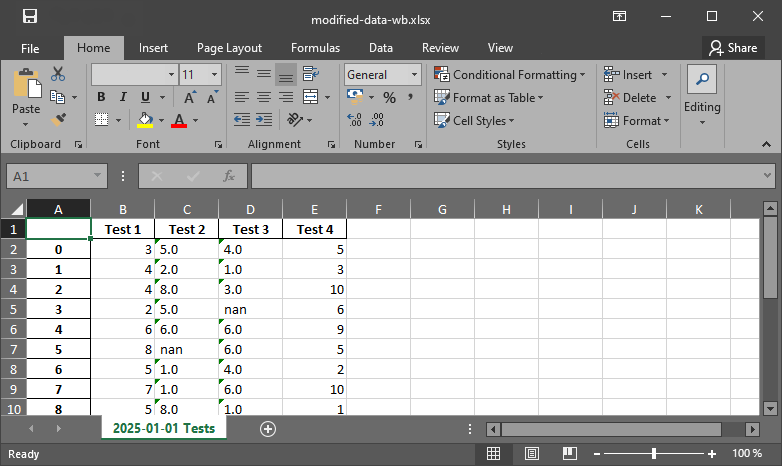
Figure 1:Le fichier de sortie xlsx produit avec pandas.
Un objet pandas ExcelWriter peut être créé pour écrire plusieurs objets pd.DataFrame dans un cahier, sur une ou plusieurs feuilles. Voici un exemple où les chaînes non numériques "nan" sont remplacées à measurement_data par np.nan pour produire une base de données purement numérique en deux étapes (# (1) et # (2)):
measurement_data = measurement_data.replace("nan", np.nan, regex=True) # (1) replace "nan" with np.nan
measurement_data = measurement_data.apply(pd.to_numeric) # (2) convert all data to numeric
# write workbook with pd ExcelWriter object
with pd.ExcelWriter("data/modified-data-wb-EW.xlsx") as writer:
measurement_data.to_excel(writer, sheet_name="2025-01-01 Tests")
df.to_excel(writer, sheet_name="pandas example")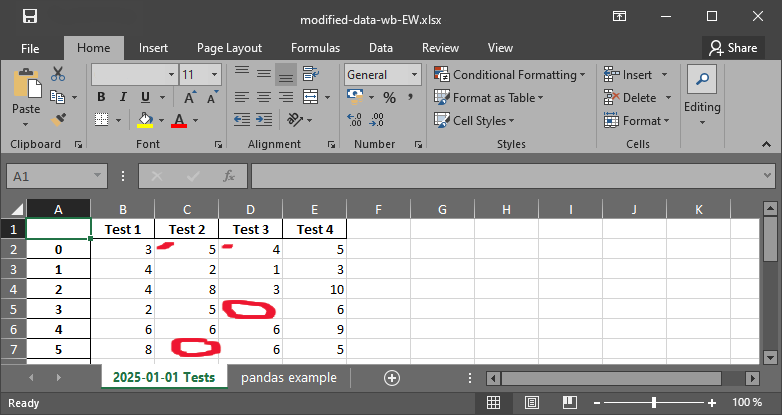
Figure 2:Le fichier xlsx avec nan strings.
Données catégoriques¶
Les variables de chaîne qui représentent des catégories statistiquement pertinentes constituent la base de référence pour la classification des données et les statistiques. Pandas fournit le type de données spécial dtype="category" pour faciliter les analyses statistiques.
Dans le Froude-number example ci-dessus, nous avons utilisé cinq catégories pour classer le régime de flux en fonction du nombre de flux*, qui peut servir de catégories. Ceci est utile, par exemple, quand aucune eau ne coulait ou quand un capteur s’est cassé dans une expérience et que nous voulons catégoriser nos mesures pour filtrer les tests valides seulement:
flow_regimes = ["fluvial", "near-critical (slow)", "critical", "near-critical (fast)", "super-critical"]
observation_examples = ["fluvial", "dry", "critical", "near-critical (slow)", "measurement error"]
Fr_cat = pd.Categorical(observation_examples, categories=flow_regimes, ordered=False)
print(pd.Series(Fr_cat))0 fluvial
1 NaN
2 critical
3 near-critical (slow)
4 NaN
dtype: category
Categories (5, str): ['fluvial', 'near-critical (slow)', 'critical', 'near-critical (fast)', 'super-critical']
/tmp/ipykernel_16649/2029032689.py:3: Pandas4Warning: Constructing a Categorical with a dtype and values containing non-null entries not in that dtype's categories is deprecated and will raise in a future version.
Fr_cat = pd.Categorical(observation_examples, categories=flow_regimes, ordered=False)
Statistiques du cadre de données¶
pandas has efficient routines to perform workbook-like row or column sorting (e.g., df.sort_index() or df.sort_values()), and enables the fast calculation of data frame statistics with df.describe(), where 25%, 50%, and 75% represent the i-th percentiles:
measurement_data.describe()Les méthodes de base de données statistiques pandas chevauchent les méthodes NumPy et comprennent :
df.abs()calcule les valeurs absoluesdf.cumprod()calcule le produit cumulatifdf.cumsum()calcule la somme cumuléedf.count()compte le nombre d’observations non-nulldf.max()calcule la valeur maximaledf.mean()calcule la moyenne (moyenne)df.min()calcule la valeur minimaledf.mode()calcule le modedf.prod()calcule le produitdf.std()calcule l’écart typedf.sum()calcule la somme
print("Mean:\n" + str(measurement_data.mean()))
print("Median:\n" + str(measurement_data.median()))
print("Standard deviation:\n" + str(measurement_data.std()))Mean:
Test 1 2.785714
Test 2 3.266667
Test 3 2.900000
Test 4 3.062500
dtype: float64
Median:
Test 1 2.5
Test 2 3.0
Test 3 3.0
Test 4 3.0
dtype: float64
Standard deviation:
Test 1 1.423893
Test 2 1.032796
Test 3 1.197219
Test 4 1.611159
dtype: float64
Appliquer des fonctions personnalisées aux cadres de données¶
Les cadres de données pandas ont une méthode apply(fun) intégrée qui permet d’appliquer une fonction personnalisée à un objet pd.DataFrame. Le bloc de code suivant emprunte à la fonction feet_to_meter du chapitre functions (télécharger convertisseur.py). Les docs pandas fournissent plus d’informations sur la méthode pandas.apply.
from fun.converter import feet_to_meter
# create data frame with random integers
df = pd.DataFrame({"Feet": np.random.randint(0, 100, size=6),
"Meters": np.ones(6) * np.nan})
# apply feet_to_meter to the Meters columns of the data frame
df["Meters"] = df["Feet"].apply(feet_to_meter)
print(df) Feet Meters
0 18 5.4864
1 62 18.8976
2 53 16.1544
3 95 28.9560
4 61 18.5928
5 59 17.9832
Dates et heure¶
pandas involves methods for calculations and labeling with date and time values through pd.Timestamp, which converts date-time-like strings into timestamps or creates timestamps from keyword arguments:
print(pd.Timestamp('2025-01-01T12'))
print(pd.Timestamp(year=2025, month=1, day=1, hour=12))
print(pd.Timestamp(2025, 1, 1, 12))2025-01-01 12:00:00
2025-01-01 12:00:00
2025-01-01 12:00:00
L’expression pd.Timestamp(2025, 1, 1, 12) imite la puissante datetime.datetime API (Application Programming Interface) de la bibliothèque datetime Python, qui fournit des méthodes sophistiquées pour gérer les valeurs dépendantes du temps. Alors que les horodatages intégrés de pandas sont pratiques pour créer des séries temporelles à l’intérieur des objets pd.DataFrame et des tables de travail, datetime est l’une des meilleures solutions pour les calculs temporels en Python. datetime est disponible par défaut (c’est-à-dire qu’il ne doit pas être installé sur conda ou pip) et est efficacement applicable, par exemple, aux données recueillies sur plusieurs années, y compris les années bissextiles. Le paquet datetime est livré avec de nombreux attributs et méthodes, qui sont documentés en détail dans le Python docs.
L’utilisation standard est:
import datetime as dt
start_date = dt.datetime(2024, 2, 25, 22, 30, 0)
end_date = dt.datetime(year=2024, month=3, day=2, hour=2, minute=15, second=30)
print("Datetime variables can be subtracted:\n" + str(end_date - start_date))
print("The result is a %s object." % type(end_date - start_date))Datetime variables can be subtracted:
5 days, 3:45:30
The result is a <class 'datetime.timedelta'> object.
Les objets dt.timedelta peuvent également être définis séparément :
time_diff = dt.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=23, weeks=0)
act_time = start_date
print("Iterate from start to end date with stepsize=time_diff:")
while act_time <= end_date:
print(act_time.strftime("%Y-%m(%h)-%d, %H:%M:%S"))
act_time += time_diffIterate from start to end date with stepsize=time_diff:
2024-02(Feb)-25, 22:30:00
2024-02(Feb)-26, 21:30:00
2024-02(Feb)-27, 20:30:00
2024-02(Feb)-28, 19:30:00
2024-02(Feb)-29, 18:30:00
2024-03(Mar)-01, 17:30:00
C’est tout pour l’introduction aux données et le traitement des fichiers. Bien qu’il y ait beaucoup plus au traitement des données que ce qui est montré dans ce chapitre et les prochains chapitres de ce livre électronique auront parfois plus d’outils.
Vérification de la réussite en apprentissage¶
Prenez le test de réussite d’apprentissage pour ce carnet Jupyter.
Unfold QR Code
