Create, manipulate, and copy semi-structured data files in the form of xlsx-workbooks and JSON files. For interactive reading and executing code blocks  and find xml.ipynb, or install Python and JupyterLab locally.
and find xml.ipynb, or install Python and JupyterLab locally.
Ce chapitre commence par des informations générales sur le XML et ce que le XML a à voir avec les cahiers de travail, et JSON: XML est une abréviation pour Extensible Markup Language qui définit les règles pour l’encodage des documents. XML a été conçu pour une utilisation simple sur Internet et nous rencontrons des documents XML tout le temps, sur des sites Web (p. ex., XHTML), sous la forme de documents de bureau (p. ex., Office Open XML comme docx, pptx ou xlsx), ou de podcasts (p. ex., RSS). La force du format XML est sa caractéristique d’être à la fois lisible par machine (c.-à-d., un ordinateur peut traiter des fichiers XML) et lisible par l’homme (c.-à-d., nous pouvons le lire comme un journal). Par exemple, l’entrée de formules dans un classeur xlsx est simultanément lisible par machine et lisible par l’homme, puisque les humains et les ordinateurs peuvent interpréter et évaluer les formules de ce cadre XML. D’autres formats de fichiers tels que JSON (JavaScript Object Notation) ressemblent au XML et Python peuvent extraire des informations des deux formats et les exporter. Dans le domaine de l’ingénierie et de la recherche sur les ressources en eau, par exemple, nous nous intéressons principalement à l’échange d’informations avec les cahiers de travail de bureau (fichiersxlsx), ou avec les fichiers JSON, qui fournissent des conditions limites pour les modèles numériques.
Watch this section as a video
Watch this section as a video on the @Hydro-Morphodynamics channel on YouTube.
Manipulation du cahier de travail (xlsx)¶
Pourquoi voulons-nous communiquer avec les cahiers ? Nous avons déjà vu que Python est beaucoup plus puissant que les programmes de bureau pour l’analyse systématique des données. Cependant, Python exige l’abstraction des données dans notre esprit pour visualiser, par exemple, la structure d’une liste imbriquée. Pour cette raison, les données de et pour le marketing, votre patron, ou les autorités publiques sont souvent nécessaires pour avoir visuellement facile à utiliser des formats de cahiers, qui peuvent être négligés rapidement. Néanmoins, nous voulons tirer parti efficacement du contenu de ces informations de cahier de travail avec Python et nous voulons produire une sortie visuellement simpliste que tout le monde peut lire sans aucune connaissance de Python.
Nous avons déjà vu que pandas fournit des routines faciles pour l’importation et l’exportation de données à partir et vers les cahiers, respectivement (cf. file reading and writing with pandas). Pandas utilise principalement openpyxl selon ce qui est disponible dans l’environnement Python actif. openpyxl est l’une des options les plus puissantes pour gérer les cahiers de travail avec Python (note: cette affirmation est subjective) et cette section introduit openpyxl.
Cette introduction utilise les termes relatifs au cahier de travail suivants:
le carnet de travail est le fichier principal xlsx avec lequel nous travaillons (également appelé spreadsheet);
sheet est le contenu tabulaire d’un cahier et un cahier peut comporter plusieurs feuilles;
les colonnes sont des lignes verticales dans une feuille;
row sont des lignes horizontales dans une feuille;
cell sont des éléments d’une feuille.
Créer un cahier de travail¶
openpyxl possède une classe Workbook qui permet de créer et de remplir des cahiers de travail avec des données. Généralement, une instance de la classe Workbook est appelée wb, et les variables de feuille de travail sont appelées ws.
import numpy as np
import openpyxl as oxl
wb = oxl.Workbook() # create a Workbook instance
ws = wb.active # activate worksheet
ws.title = "Gaussian 2D" # name worksheet
ws["A1"] = "Gaussian sample data" # write to cell A1
# generate some data
x, y = np.meshgrid(np.linspace(-1, 1, 20), np.linspace(-1, 1, 20))
dis = np.sqrt(x * x + y * y)
sigma, mu = 1.0, 0.0
gaussian = np.exp(-((dis - mu) ** 2 / (2.0 * sigma ** 2)))
# write data to worksheet
m, n = gaussian.shape
for i in range(1, m):
for j in range(1, n):
_ = ws.cell(row=i+1, column=j, value=gaussian[i-1, j-1])
print("Workbook data in cell A2: "+ str(ws["A2"].value))
print("Corresponds to np.array value: " + str(gaussian[0, 0]))
# save and close (destruct object) workbook
wb.save(filename="data/python_workbook.xlsx")
wb.close()Workbook data in cell A2: 0.3678794411714422
Corresponds to np.array value: 0.3678794411714422
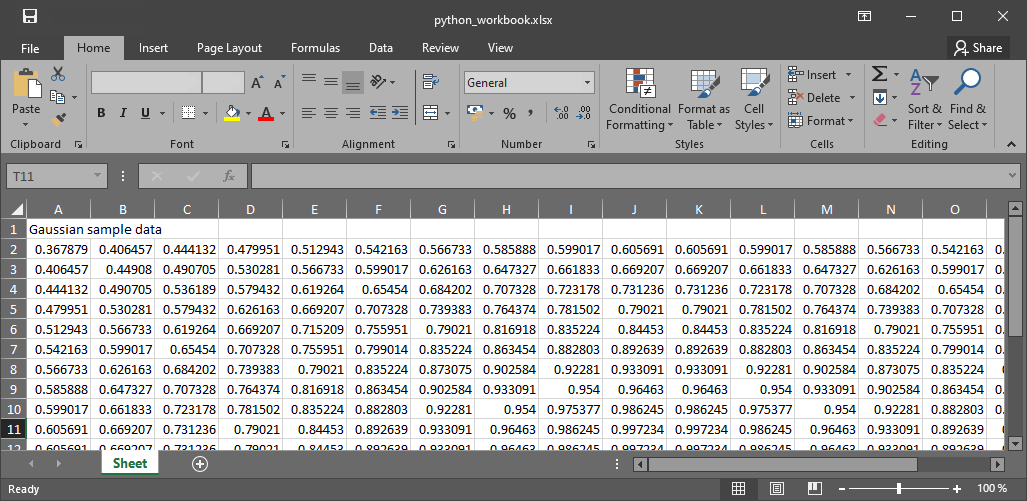
Figure 1:Le cahier qui en résulte.
Lire et manipuler un manuel existant¶
openpyxl lit les cahiers de travail existants avec openpyxl.load_workbook(filename=str()). Cette fonction accepte les paramètres optionnels comme :
read_only=BOOLEANdécide si un classeur est ouvert en mode lecture seule. Un cahier de travail ne peut être manipulé que siread_only=False(c’est l’option par défaut, qui peut être utile pour gérer les grands fichiers ou pour s’assurer que les objets graphiques ne sont pas perdus).write_only=BOOLEANdécide si un classeur est ouvert en mode write seulement. Siwrite_only=True(la valeur par défaut estFalse), aucune donnée ne peut être lue à partir d’un cahier de cours, mais l’écriture des données est beaucoup plus rapide (c.-à-d., cette option est utile pour écrire de gros ensembles de données).data_only=BOOLEANdétermine si les formules cellulaires ou les données cellulaires seront lues. Par exemple, lorsque le contenu d’une cellule est=PI(),data_only=False(c’est l’option par défaut) lit la valeur de la cellule comme=PI()etdata_only=Truelit la valeur de la cellule comme3.14159265359.keep_vba=BOOLEANcontrôle si les éléments de base visuelle* (macros) sont conservés ou non. La valeur par défaut estkeep_vba=False(i.e., aucune conservation), etkeep_vba=Truene permettra toujours pas de modifier les éléments de base visuels.
Si read_only=False, nous pouvons manipuler les valeurs cellulaires et aussi les formats cellulaires, y compris les formats de données (p. ex., date, heure, et plusieurs plus), propriétés de la Font (et beaucoup plus de styles cellulaires), ou les couleurs dans HEX Color Code (trouvez votre couleur préférée ici). L’exemple suivant ouvre le fichier python_workbook.xlsx, ajoute une nouvelle feuille de travail, illustre l’implémentation des styles cellulaires et remplit le cahier de travail avec des mesures de décharge aléatoires.
import datetime
from openpyxl.styles import Font, Alignment, PatternFill
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)
ws = wb.create_sheet(title="Discharge")
# define title styles
title_font = Font(name="Tahoma", size="11", bold=True, italic=True, color="C1D0DE")
title_fill = PatternFill(fill_type="solid", start_color="050505", end_color="073AD4")
title_align = Alignment(horizontal='center', vertical='bottom', text_rotation=0,
wrap_text=False, shrink_to_fit=False, indent=0)
date_time_format = "yyyy-mm-dd hh:mm:ss"
ws["A1"] = "Date-Time (%s)" % date_time_format
title_cell_flow = ws["B1"]
title_cell_flow.value = "Discharge (CMS)"
title_cell_flow.font = title_font
title_cell_flow.fill = title_fill
title_cell_flow.alignment = title_align
# define time period and time delta of 1 hour = 3600 seconds
current_date_time = datetime.datetime(2040, 12, 24, 0, 0)
dt = datetime.timedelta(seconds=3600)
# write random discharges to workbooks
for row in ws.iter_rows(min_row=2, max_row=26, min_col=1, max_col=2):
row[0].value = current_date_time
row[0].number_format = date_time_format
row[1].value = np.random.random_sample(size=None) * 100
row[1].number_format = "0.00"
current_date_time += dt
wb.save("data/python_workbook_reloaded.xlsx")
wb.close()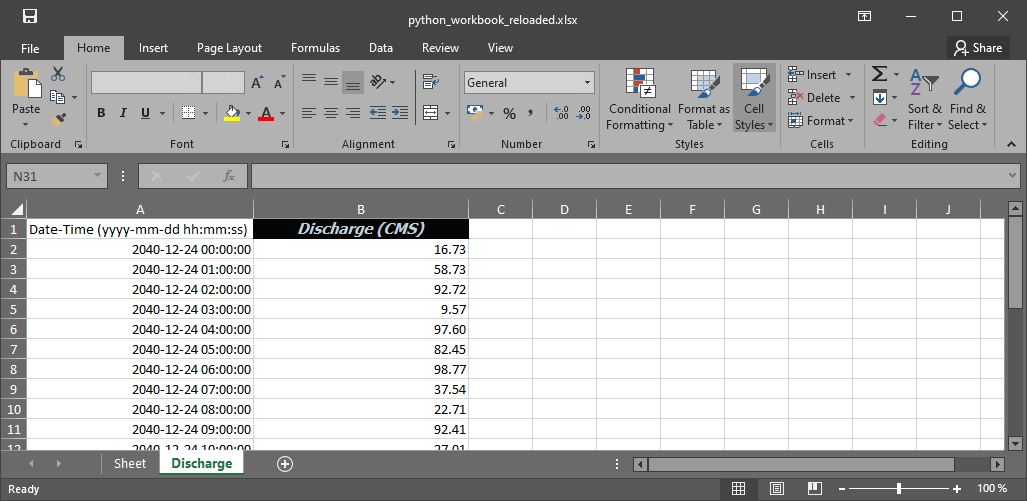
Figure 2:Le cahier mis à jour.
Le bloc de code ci-dessous fournit la fonction d’aide courte read_columns pour lire seulement une ou plusieurs colonnes dans une list (lise jusqu’à ce que le nombre maximum de lignes, défini par ws.rows, dans un cahier de travail soit atteint). Une fonction similaire peut être écrite pour la lecture des lignes.
def read_columns(ws, start_row=0, columns="ABC"):
return [ws["{}{}".format(column, row)].value for row in range(start_row, ws.max_row + 1) for column in columns]
# example usage:
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)
ws = wb.active
col_D = read_columns(ws, start_row=2, columns="D")
col_F = read_columns(ws, start_row=2, columns="F")
wb.close()Challenge: Add a random test set to modified-data-wb.xlsx
Le pandas file handling section propose la création d’un cahier de travail contenant 4 colonnes de données de test (télécharger modified-data-wb.xlsx). Pour une comparaison aléatoire, vous voulez ajouter une colonne de valeurs aléatoires. À cette fin:
Ouvrir modifié-data-wb.xlsx avec openpyxl
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)Obtenez la feuille de travail active
ws = wb.activeAjouter un nouveau nom dans la colonne F:
ws["F1"].value = "Random values"Créer une liste (c.-à-d. un tableau 1d) de nombres aléatoires avec numpy (n’oubliez pas
import numpy as np)rnd_data = np.random.random(18)Itérer sur le tableau de données aléatoires et écrire les valeurs à la colonne F du cahier de travail
Commencez l’itération par
for row, val in enumerate(rnd_data):In every iteration add the next random value of
rnd_datawithws["F" + str(row + 2)].value = val
Note the usage ofrow + 2(one header column and different absolutes of Python and the workbook)
Enregistrer et fermer le cahier
wb.save(os.getcwd() + "/data/re-modified-data-wb.xlsx"(n’oubliez pasimport os)wb.close()Alternativement, utilisez un espace de noms pour la manipulation du cahier!
Formules dans les cahiers de travail¶
L’argument optionnel de mot-clé data_only=False permet de lire les formules du cahier au lieu des valeurs cellulaires. Cependant, toutes les formules du cahier de travail ne sont pas reconnues par openpyxl et, en cas de doute, une mauvaise approche d’essai et d’erreur est le seul remède. Par exemple, changez SQRT dans l’exemple ci-dessous pour la formule en question.
from openpyxl.utils import FORMULAE
print("SQRT" in FORMULAE)True
Cellules de fusion¶
Les cellules de fusion et de désintégration sont une fonction de bureau populaire à des fins de style et openpyxl fournit également des fonctions pour effectuer des opérations de fusion:
ws.merge_cells(start_row=1, end_row=3, start_column=1, end_column=2)
ws.unmerge_cells(start_row=1, end_row=3, start_column=1, end_column=2)Graphiques (lots)¶
Dans le cas peu probable où vous souhaitez insérer des tracés directement dans les cahiers de travail avec Python (matplotlib est de toute façon plus puissant), openpyxl fournit également des fonctionnalités à cet effet. Pour illustrer la création d’un graphique régional, le bloc de code ci-dessous réutilise la première colonne de valeurs aléatoires dans le python_workbook.xlsx.
from openpyxl.chart import AreaChart, Reference, Series
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)
ws = wb.active
chart = AreaChart()
chart.title = "Random Gaussian"
chart.style = 10
chart.x_axis.title = "Cell row"
chart.y_axis.title = "Random value (-)"
col_D = Reference(ws, min_col=4, min_row=2, max_row=20)
col_F = Reference(ws, min_col=6, min_row=2, max_row=20)
chart.add_data(col_F, titles_from_data=False)
chart.add_data(col_D, titles_from_data=False)
ws.add_chart(chart, "B2")
wb.save("data/python_workbook_chart.xlsx")
wb.close()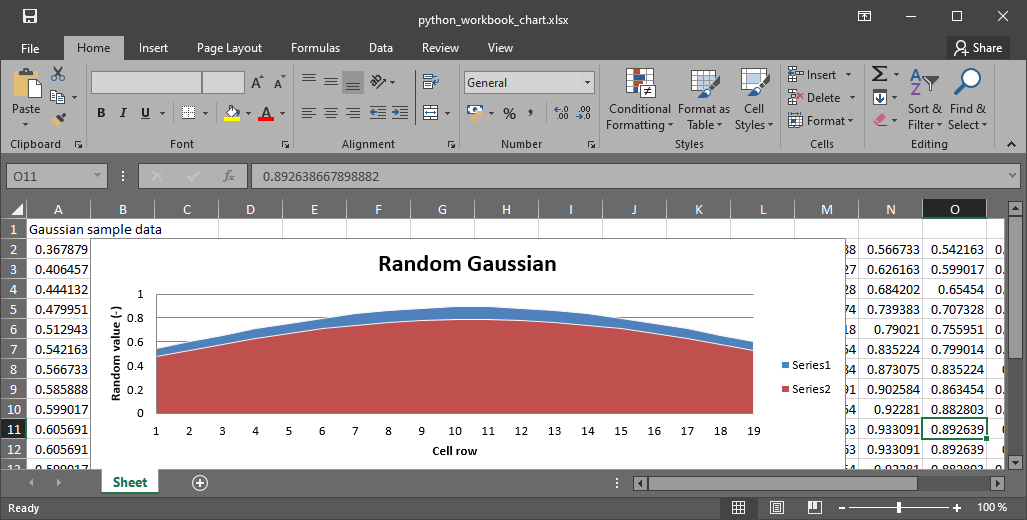
Figure 3:Le cahier avec l’intrigue créée en Python.
D’autres diagrammes de cahiers sont disponibles et leur mise en œuvre (toujours: pourquoi le feriez-vous?) est expliquée dans le openpyxl docs.
Personnaliser la manipulation des cahiers de travail¶
Il existe de nombreuses façons de modifier les cahiers de travail et openpyxl fournit des méthodes proches de celles qui sont prêtes pour manipuler un cahier de travail. Néanmoins, pour éviter de relire cette leçon chaque fois que vous voulez manipuler un cahier, il est plus pratique d’avoir vos propres classes de manipulation de cahiers prêts à travailler. À cette fin, le bloc de code suivant définit les classes Read et Write, où Read est la classe mère de la classe Write (appelez la section sur inheritance of classes). La classe Read peut contenir des fonctions sur mesure pour lire des colonnes, des lignes ou des tableaux spécifiques. Le bloc de code ci-dessous utilise également la fonction read_columns définie ci-dessus, mise en œuvre comme méthode de la classe Read.
import openpyxl as oxl
class Read:
def __init__(self, workbook_name="", *args, **kwargs):
read_only = kwargs.get("read_only")
data_only = kwargs.get("data_only")
sheet_name = kwargs.get("sheet_name")
self.wb = oxl.load_workbook(filename=workbook_name, read_only=read_only, data_only=data_only)
if sheet_name:
self.ws = self.wb[sheet_name]
else:
self.ws = self.wb[self.wb.sheetnames[0]]
def read_columns(self, start_row=0, columns="ABC"):
return [self.ws["{}{}".format(column, row)].value for row in range(start_row, self.ws.max_row + 1) for column
in columns]
def __call__(self):
print(dir(self))
class Write(Read):
def __init__(self, workbook_name="", *args, **kwargs):
data_only = kwargs.get("data_only")
sheet_name = kwargs.get("sheet_name")
Read.__init__(self, workbook_name=workbook_name, read_only=False, data_only=data_only, sheet_name=sheet_name)
Un script d’exemple étendu avec des classes plus complexes Read et Write peut être téléchargé à partir du course depositary.
Un exemple de l’ingénierie des ressources en eau et de la recherche¶
La restauration ou l’amélioration écologique des rivières nécessite, entre autres, des données sur les profondeurs d’eau et les vitesses d’écoulement préférées des espèces de poissons ciblées. Cette information est établie par des biologistes, puis souvent fournie sous la forme de ce que l’on appelle indice d’aptitude à l’habitat (HSI) courbes en format de classeur. Généralement, nous produisons des données géospatiales explicites sur la profondeur de l’eau et la vitesse du débit avec des modèles numériques. La production de modèles numériques à deux ou trois dimensions est beaucoup trop grande pour être traitée avec des applications de bureau. Nous avons donc besoin d’un outil avancé, comme Python, pour gérer les données géospatialement explicites, et lire et interpoler les courbes HSI à partir des cahiers de travail. A quoi ça ressemble techniquement ? Le exercises on geospatial Python vous permettra de plonger dans l’habitat aquatique (évaluations).
JSON¶
Les fichiers JavaScript Object Notation (JSON) ont une structure similaire au XML et permettent le stockage structuré des données (à lire humaine). Par exemple, le code numérique BASEMENT v.3.x (read more in the numerical modeling chapter) utilise un fichier model.json et un fichier simulation.json pour stocker les paramètres de configuration du modèle tels que les propriétés matérielles. Ainsi, automatiser les configurations de modèles numériques avec Python implique la modification des paramètres de modèles stockés dans les fichiers json. C’est là que Python entre en jeu avec les modules JSON et pandas’ JSON.
Structure du fichier JSON¶
Un fichier JSON se compose de deux types de structures de données, qui sont des objets dictionnaires et array sous forme de listes de valeurs. Les objets dictionnaire dans un fichier JSON correspondent au format que nous connaissons déjà en Python : Paires de keys (noms) et values embrassées par des crochets bouclés (braces) {"name": value}. Le value peut être un string, numérique, une list séparée par des virgules* [] (array) de données, ou un autre dictionnaire.
L’exemple suivant montre un fichier JSON appelé river_struct.json avec une clé RIVER qui a un dictionnaire imbriqué comme valeur. La valeur-dictionnaire contient trois clés (NAME, GEOMETRY et HYDRAULICS).
{
"RIVER": {
"NAME": "Vanilla Flow",
"GEOMETRY": {
"REGIONS": [
{
"type": "wet",
"name": "riverbed"
},
{
"type": "dry",
"name": "floodplain"
}
],
"FLOWBOUNDARIES": [
{
"name": "Inflow",
"nodes": [1, 3, 7, 31]
},
{
"name": "Outflow",
"nodes": [89, 90, 76, 69, 95]
}
]
},
"HYDRAULICS": {
"BOUNDARY": [
{
"discharge_file": "/simulation/directory/Inflow.txt",
"name": "Inflow",
"slope": 0.005,
"type": "hydrograph"
},
{
"name": "Outflow",
"type": "zero_gradient"
}
],
"FRICTION": {
"cobble": 20.0,
"gravel": 26.0,
"sand": 41
}
},
"LOCATION": [48.744079, 9.103928]
}
}{'RIVER': {'NAME': 'Vanilla Flow',
'GEOMETRY': {'REGIONS': [{'type': 'wet', 'name': 'riverbed'},
{'type': 'dry', 'name': 'floodplain'}],
'FLOWBOUNDARIES': [{'name': 'Inflow', 'nodes': [1, 3, 7, 31]},
{'name': 'Outflow', 'nodes': [89, 90, 76, 69, 95]}]},
'HYDRAULICS': {'BOUNDARY': [{'discharge_file': '/simulation/directory/Inflow.txt',
'name': 'Inflow',
'slope': 0.005,
'type': 'hydrograph'},
{'name': 'Outflow', 'type': 'zero_gradient'}],
'FRICTION': {'cobble': 20.0, 'gravel': 26.0, 'sand': 41}},
'LOCATION': [48.744079, 9.103928]}}Lire (Décoder) et écrire (Encoder) les fichiers JSON avec la bibliothèque json¶
Les fichiers JSON peuvent être implémentés dans de nombreux langages de programmation, y compris HTML et Python. C’est pourquoi les carnets Jupyter (comme utilisé dans ce livre électronique) peuvent être lancés en Python et affichés comme une page Web. Python possède une bibliothèque json intégrée qui permet le décodage et l’encodage JSON. La bibliothèque json fournit une méthode json.dumps(DATA) pour “dump” (i.e., encoder) les données au format JSON. Vice versa, la fonction json.load() lit les données des fichiers JSON. L’exemple suivant illustre l’encodage et le décodage d’un ensemble de données niché arbitrairement avec la bibliothèque json.
import json
# create arbitrary nested data (list, dictionary, tuple)
data_for_json = ["list_element1", {"dict_key": ("tuple_element", "text", 1.0, None)}]
# create a json file
json_file = open("data/my-first.json", mode="w+")
# encode the random nested data list in json format and write to file
json_file.write(json.dumps(data_for_json))
# close file
json_file.close()
# re-open the json file to read data
with open("data/my-first.json", mode="r") as re_opened_file:
raw_data = re_opened_file.readline()
# decode json data in a Python variable
data_from_json = json.loads(raw_data)
print(json.dumps(data_from_json))["list_element1", {"dict_key": ["tuple_element", "text", 1.0, null]}]
La Python docs fournit d’autres options et descriptions sur l’utilisation de la bibliothèque json. Cependant, ici, nous allons (une fois de plus) utiliser la bibliothèque pandas, qui offre des fonctionnalités puissantes pour traiter les données de json.
Lire (Décoder) et écrire (Encoder) des fichiers JSON avec pandas¶
pandas (recall data and file handling with pandas) enables reading JSON files into its convenient table format with an embedded usage of the json library. The following code block uses the pandasRIVER sample file (download river_struct.json).
import pandas as pd
river = pd.read_json("data/river_struct.json")
print(river) RIVER
NAME Vanilla Flow
GEOMETRY {'REGIONS': [{'type': 'wet', 'name': 'riverbed...
HYDRAULICS {'BOUNDARY': [{'discharge_file': '/simulation/...
LOCATION [48.744079, 9.103928]
Comme une rivière sans données est comme une glace sans goût, nous ajouterons des données aléatoires sur les caractéristiques du débit à la structure des données. Supposons que nous avons utilisé les données de river_struct.json pour simuler une décharge stationnaire dans un modèle numérique bidimensionnel. En conséquence, nous avons deux grilles régulières (arrays) avec des données sur la vitesse d’écoulement et la profondeur de l’eau. Maintenant, nous voulons ajouter à la fois les réseaux de vitesse d’écoulement et de profondeur d’eau sous la forme d’une structure de résultat (dictionnaire) à river_struct.json et donner un nouveau nom à la rivière.
# create random data
import numpy as np
h = np.random.weibull(np.arange(0,100)).reshape(10, 10)
u = np.random.weibull(np.arange(0,100)).reshape(10, 10)
# append RESULTS row to pandas dataframe
river_dict = river.to_dict()
river_dict["RIVER"].update({"RESULTS": {"water_depth": h, "flow_velocity": u}})
updated_river = pd.DataFrame.from_dict(river_dict)
# re-NAME RIVER
updated_river.loc["NAME", "RIVER"] = "Honey river"
print(updated_river)
# export to JSON
updated_river.to_json("data/river_results.json") RIVER
NAME Honey river
GEOMETRY {'REGIONS': [{'type': 'wet', 'name': 'riverbed...
HYDRAULICS {'BOUNDARY': [{'discharge_file': '/simulation/...
LOCATION [48.744079, 9.103928]
RESULTS {'water_depth': [[0.0, 1.4016850027236283, 0.6...
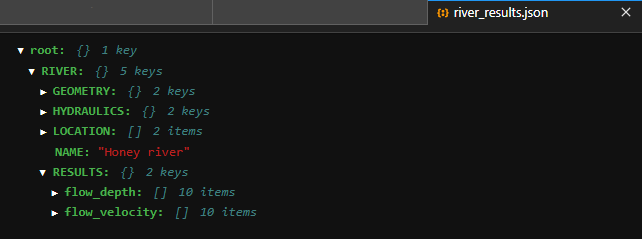
Figure 4:Le cahier qui en résulte.
Vérification de la réussite en apprentissage¶
Prenez le test de réussite d’apprentissage pour ce carnet Jupyter.
Unfold QR Code
