Create, manipulate, and copy semi-structured data files in the form of xlsx-workbooks and JSON files. For interactive reading and executing code blocks  and find xml.ipynb, or install Python and JupyterLab locally.
and find xml.ipynb, or install Python and JupyterLab locally.
Dieses Kapitel beginnt mit Hintergrundinformationen über XML und was XML mit Workbooks zu tun hat, und JSON: XML ist eine Abkürzung für Extensible **M*arkup Language, die Regeln für die Kodierung von Dokumenten definiert. XML wurde für eine unkomplizierte Nutzung über das Internet konzipiert und wir begegnen XML-Dokumenten die ganze Zeit, auf Websites (z.B. XHTML), in Form von Office-Dokumenten (z.B. Office Open XML wie docx, pptx oder xlsx), oder Podcasts (z.B. RSS). Die Stärke des XML-Formats ist seine Eigenschaft, sowohl maschinenlesbar zu sein (d.h. ein Computer kann XML-Dateien verarbeiten) als auch menschlesbar (d.h. wir können es wie eine Zeitung lesen). So ist die Eingabe von Formeln in einem xlsx-Arbeitsbuch gleichzeitig maschinenlesbar und menschlesbar, da Menschen und Computer die Formeln in diesem XML-Rahmen interpretieren und auswerten können. Andere Dateiformate wie JSON (JavaScript Object Notation) ähneln XML und Python können Informationen aus und exportieren Informationen in beide Formate. In der Wasserressourcen-Engineering und Forschung, zum Beispiel, sind wir vor allem am Austausch von Informationen mit Büro-Workbooks (xlsx Dateien), oder mit JSON-Dateien, die Randbedingungen für numerische Modelle bieten interessiert.
Watch this section as a video
Watch this section as a video on the @Hydro-Morphodynamics channel on YouTube.
Arbeitsbuch (xlsx)¶
Warum wollen wir überhaupt mit Arbeitsmappen kommunizieren? Wir haben bereits gesehen, dass Python viel mächtiger ist als Büroprogramme für die systematische Analyse von Daten. Python erfordert jedoch die Abstraktion von Daten in unseren Köpfen, um beispielsweise die Struktur einer geschachtelten Liste zu visualisieren. Aus diesem Grund sind Daten von und für das Marketing, Ihr Chef oder Behörden oft erforderlich, um visuell einfach zu bedienende Arbeitsmappenformate zu haben, die schnell übersehen werden können. Dennoch wollen wir mit Python den Inhalt solcher Workbook-Informationen effizient nutzen, und wir wollen visuell vereinfachte Ausgabe produzieren, die jeder ohne Python-Wissen lesen kann.
Wir haben bereits gesehen, dass pandas einfache Routinen für den Import und Export von Daten aus bzw. zu Arbeitsmappen bietet (vgl. file reading and writing with pandas). pandas verwendet in erster Linie openpyxl, je nachdem, was in der aktiven Python-Umgebung verfügbar ist. openpyxl ist eine der leistungsfähigsten Optionen für die Handhabung von Arbeitsmappe mit Python (Anm.: diese Behauptung ist subjektiv) und dieser Abschnitt führt openpyxl ein.
Diese Einführung nutzt die folgenden arbeitsbuchbezogenen Begriffe:
workbook ist die Hauptdatei xlsx, mit der wir zusammenarbeiten (auch Spreadsheet genannt);
sheet ist der tabellarische Inhalt eines Arbeitsbuchs und ein Arbeitsbuch kann mehrere Blätter haben;
** Spalte*** sind vertikale Linien in einem Blatt;
**) sind horizontale Linien in einem Blatt;
Zellen*s sind Elemente eines Blattes.
Ein Workbook erstellen¶
openpyxl hat eine Workbook-Klasse, die es ermöglicht, Arbeitsmappen mit Daten zu erstellen und zu füllen. Typischerweise wird eine Instanz der Workbook-Klasse wb genannt und Arbeitsblattvariablen werden ws genannt.
import numpy as np
import openpyxl as oxl
wb = oxl.Workbook() # create a Workbook instance
ws = wb.active # activate worksheet
ws.title = "Gaussian 2D" # name worksheet
ws["A1"] = "Gaussian sample data" # write to cell A1
# generate some data
x, y = np.meshgrid(np.linspace(-1, 1, 20), np.linspace(-1, 1, 20))
dis = np.sqrt(x * x + y * y)
sigma, mu = 1.0, 0.0
gaussian = np.exp(-((dis - mu) ** 2 / (2.0 * sigma ** 2)))
# write data to worksheet
m, n = gaussian.shape
for i in range(1, m):
for j in range(1, n):
_ = ws.cell(row=i+1, column=j, value=gaussian[i-1, j-1])
print("Workbook data in cell A2: "+ str(ws["A2"].value))
print("Corresponds to np.array value: " + str(gaussian[0, 0]))
# save and close (destruct object) workbook
wb.save(filename="data/python_workbook.xlsx")
wb.close()Workbook data in cell A2: 0.3678794411714422
Corresponds to np.array value: 0.3678794411714422
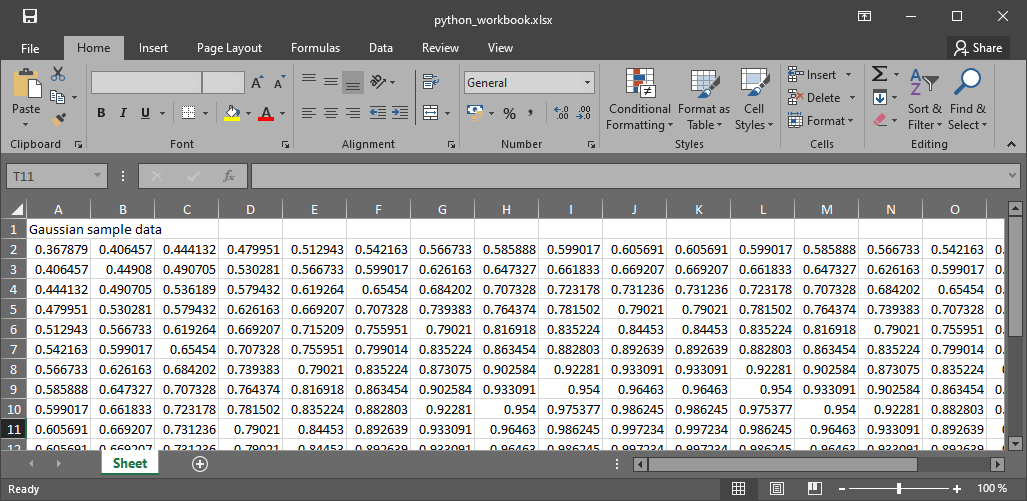
Figure 1:Das daraus resultierende Arbeitsbuch.
Lesen und Manipulate eines vorhandenen Arbeitsbuches¶
openpyxl liest bestehende Arbeitsbücher mit openpyxl.load_workbook(filename=str()). Diese Funktion akzeptiert optionale Keyword-Argumente, wie:
read_only=BOOLEANentscheidet, ob ein Arbeitsbuch im read-only Modus geöffnet wird. Ein Arbeitsbuch kann nur manipuliert werden, wennread_only=False(dies ist die Standardoption, die nützlich sein kann, um große Dateien zu handhaben oder sicherzustellen, dass grafische Objekte nicht verloren gehen).write_only=BOOLEANentscheidet, ob ein Arbeitsbuch im write only Modus geöffnet wird. Wennwrite_only=True(die Standardeinstellung istFalse) keine Daten aus einem Arbeitsbuch gelesen werden können, aber die Schreibdaten sind deutlich schneller (d.h. diese Option ist für das Schreiben großer Datensätze nützlich).data_only=BOOLEANbestimmt, ob Zellformeln oder Zelldaten gelesen werden. Wenn z.B. der Inhalt einer Workbook-Zelle=PI(),data_only=False(dies ist die Standardoption) den Zellwert als=PI()unddata_only=Truelautet, lautet der Zellwert als3.14159265359.keep_vba=BOOLEANkontrolliert, ob Visual Basic-Elemente (Makros) aufbewahrt werden oder nicht. Die Standardeinstellung istkeep_vba=False(d.h. keine Konservierung) undkeep_vba=Truewird immer noch keine Änderung von Visual Basic-Elementen ermöglichen.
Wenn read_only=False, können wir Zellwerte und auch Zellformate manipulieren, einschließlich Datenformate (z.B. Datum, Uhrzeit und viel mehr), Font-Eigenschaften (und viele weitere Zell-Styles), oder Farben in HEX Color Code (findet Ihre Lieblingsfarbe hier). Das folgende Beispiel öffnet die oben erstellte python_workbook.xlsx, fügt ein neues Arbeitsblatt hinzu, verdeutlicht die Implementierung von Zellstilen und füllt das Arbeitsbuch mit zufälligen Entladungsmessungen.
import datetime
from openpyxl.styles import Font, Alignment, PatternFill
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)
ws = wb.create_sheet(title="Discharge")
# define title styles
title_font = Font(name="Tahoma", size="11", bold=True, italic=True, color="C1D0DE")
title_fill = PatternFill(fill_type="solid", start_color="050505", end_color="073AD4")
title_align = Alignment(horizontal='center', vertical='bottom', text_rotation=0,
wrap_text=False, shrink_to_fit=False, indent=0)
date_time_format = "yyyy-mm-dd hh:mm:ss"
ws["A1"] = "Date-Time (%s)" % date_time_format
title_cell_flow = ws["B1"]
title_cell_flow.value = "Discharge (CMS)"
title_cell_flow.font = title_font
title_cell_flow.fill = title_fill
title_cell_flow.alignment = title_align
# define time period and time delta of 1 hour = 3600 seconds
current_date_time = datetime.datetime(2040, 12, 24, 0, 0)
dt = datetime.timedelta(seconds=3600)
# write random discharges to workbooks
for row in ws.iter_rows(min_row=2, max_row=26, min_col=1, max_col=2):
row[0].value = current_date_time
row[0].number_format = date_time_format
row[1].value = np.random.random_sample(size=None) * 100
row[1].number_format = "0.00"
current_date_time += dt
wb.save("data/python_workbook_reloaded.xlsx")
wb.close()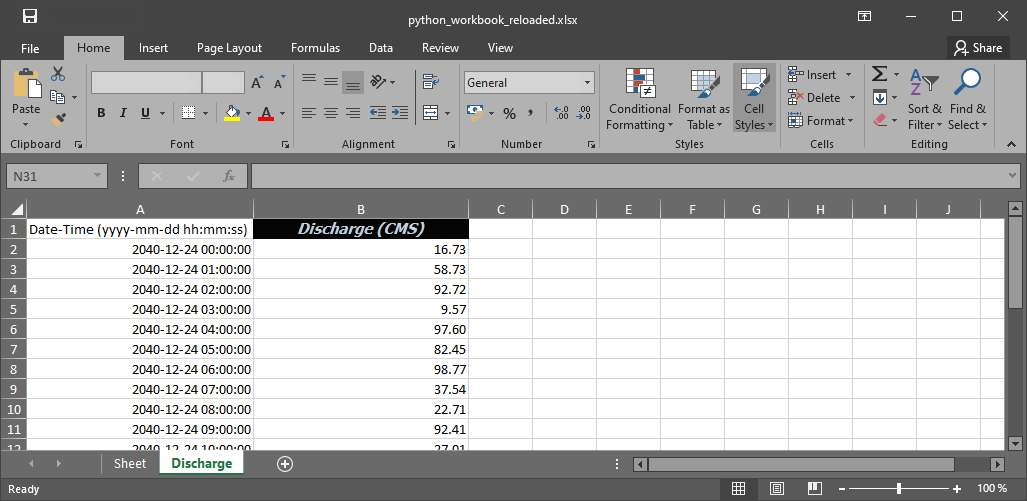
Figure 2:Das aktualisierte Arbeitsbuch.
Der folgende Codeblock bietet die kurze Helper-Funktion read_columns, um nur eine oder mehrere Spalten in eine (nässte) list zu lesen ( liest bis die maximale Anzahl der Zeilen, die von ws.rows definiert sind, in einem Arbeitsbuch erreicht ist). Eine ähnliche Funktion kann zum Lesen von Zeilen geschrieben werden.
def read_columns(ws, start_row=0, columns="ABC"):
return [ws["{}{}".format(column, row)].value for row in range(start_row, ws.max_row + 1) for column in columns]
# example usage:
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)
ws = wb.active
col_D = read_columns(ws, start_row=2, columns="D")
col_F = read_columns(ws, start_row=2, columns="F")
wb.close()Challenge: Add a random test set to modified-data-wb.xlsx
Die pandas file handling section bietet die Erstellung eines Arbeitsbuchs mit 4 Spalten von Testdaten (downloaden Sie modifiziert-data-wb.xlsx). Für einen Zufallstest-Vergleich möchten Sie eine Spalte mit Zufallswerten hinzufügen. Dazu:
modified-data-wb.xlsx mit openpyxl
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)Aktives Arbeitsblatt erhalten
ws = wb.activeEinen neuen Spaltennamen in Spalte hinzufügen *F:
ws["F1"].value = "Random values"Erstellen Sie eine Liste (d.h. ein 1d-Array) von Zufallszahlen mit numpy (vergesst nicht
import numpy as np)rnd_data = np.random.random(18)Iterate über das Zufallsdatenfeld und schreibe die Werte in die *F Spalte
Starten Sie die Iteration mit
for row, val in enumerate(rnd_data):In every iteration add the next random value of
rnd_datawithws["F" + str(row + 2)].value = val
Note the usage ofrow + 2(one header column and different absolutes of Python and the workbook)
Speichern und schließen Sie das Arbeitsbuch
wb.save(os.getcwd() + "/data/re-modified-data-wb.xlsx"(vergesst nichtimport os)wb.close()Alternativ nutzen Sie einen Namensraum für die Workbook-Manipulation!
Formeln in Arbeitsbüchern¶
Das optionale Keyword-Argument data_only=False ermöglicht das Lesen von Workbook-Formeln anstelle von Zellwerten. Allerdings werden nicht alle Workbook-Formeln durch openpyxl erkannt und im Zweifelsfall ist ein schmutziger Try-and-Eror-Ansatz das einzige Mittel. Ändern Sie im folgenden Beispiel SQRT an die betreffende Formel.
from openpyxl.utils import FORMULAE
print("SQRT" in FORMULAE)True
(Un)merge Cells¶
Zusammenführende und nicht-verschmelzende Zellen ist eine beliebte Bürofunktion für Stilzwecke und openpyxl bietet auch Funktionen zur Durchführung von Zusammenführungen:
ws.merge_cells(start_row=1, end_row=3, start_column=1, end_column=2)
ws.unmerge_cells(start_row=1, end_row=3, start_column=1, end_column=2)Diagramme (Plots)¶
Im unwahrscheinlichen Fall, dass Sie Grundstücke direkt in Arbeitsbücher mit Python einfügen möchten (matplotlib ist sowieso leistungsfähiger), openpyxl bietet hierzu auch Features. Um die Erstellung eines Flächendiagramms zu illustrieren, verwendet der nachfolgende Codeblock die erste Spalte von Zufallswerten in der oben erstellten python_workbook.xlsx.
from openpyxl.chart import AreaChart, Reference, Series
wb = oxl.load_workbook(filename="data/python_workbook.xlsx", read_only=False)
ws = wb.active
chart = AreaChart()
chart.title = "Random Gaussian"
chart.style = 10
chart.x_axis.title = "Cell row"
chart.y_axis.title = "Random value (-)"
col_D = Reference(ws, min_col=4, min_row=2, max_row=20)
col_F = Reference(ws, min_col=6, min_row=2, max_row=20)
chart.add_data(col_F, titles_from_data=False)
chart.add_data(col_D, titles_from_data=False)
ws.add_chart(chart, "B2")
wb.save("data/python_workbook_chart.xlsx")
wb.close()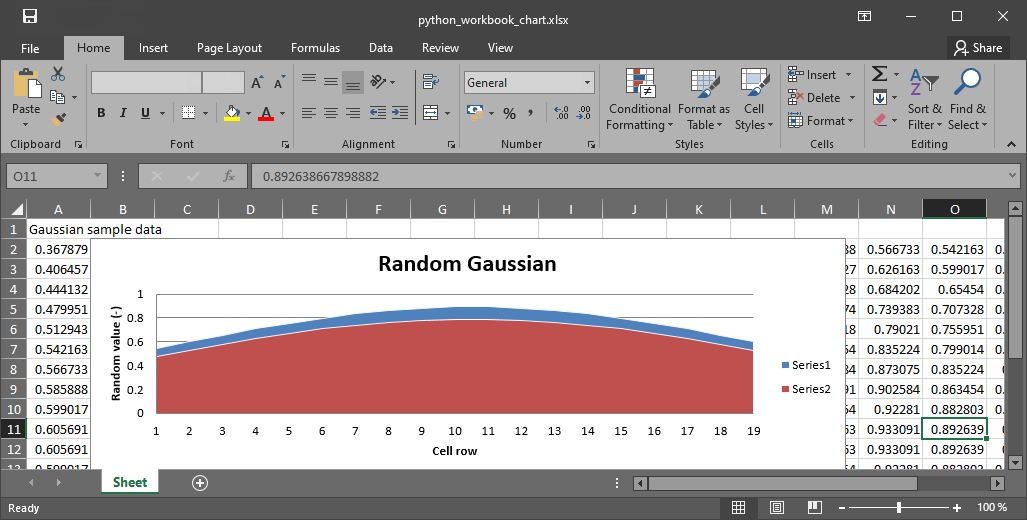
Figure 3:Das Arbeitsbuch mit dem in Python erstellten Grundstück.
Andere Arbeitsmappen sind verfügbar und ihre Umsetzung (noch: warum würden Sie?) wird in der openpyxl docs erklärt.
Workbook Manipulation anpassen¶
Es gibt viele Möglichkeiten, Arbeitsmappen zu modifizieren und openpyxl bietet nah an “shovel-ready” Methoden, um ein Arbeitsbuch zu manipulieren. Um jedoch zu vermeiden, diese Lektion jedes Mal neu zu lesen, wenn Sie ein Arbeitsbuch manipulieren möchten, ist es bequemer, Ihre eigenen Arbeitsmappe Manipulationsklassen bereit zu arbeiten. Zu diesem Zweck definiert der folgende Codeblock benutzerdefinierte Read und Write-Klassen, wobei Read die Elternklasse der Write-Klasse ist (Recall the Section on inheritance of classes). Die Read-Klasse kann maßgeschneiderte Funktionen zum Lesen bestimmter Spalten, Zeilen oder Arrays enthalten. Der folgende Codeblock nutzt auch die oben definierte read_columns-Funktion, die als Methode der Read-Klasse implementiert wird.
import openpyxl as oxl
class Read:
def __init__(self, workbook_name="", *args, **kwargs):
read_only = kwargs.get("read_only")
data_only = kwargs.get("data_only")
sheet_name = kwargs.get("sheet_name")
self.wb = oxl.load_workbook(filename=workbook_name, read_only=read_only, data_only=data_only)
if sheet_name:
self.ws = self.wb[sheet_name]
else:
self.ws = self.wb[self.wb.sheetnames[0]]
def read_columns(self, start_row=0, columns="ABC"):
return [self.ws["{}{}".format(column, row)].value for row in range(start_row, self.ws.max_row + 1) for column
in columns]
def __call__(self):
print(dir(self))
class Write(Read):
def __init__(self, workbook_name="", *args, **kwargs):
data_only = kwargs.get("data_only")
sheet_name = kwargs.get("sheet_name")
Read.__init__(self, workbook_name=workbook_name, read_only=False, data_only=data_only, sheet_name=sheet_name)
Ein erweitertes Beispiel-Skript mit komplexer Read und WriteKlassen kann von der course repository heruntergeladen werden.
Ein Beispiel für Wasserressourcentechnik und Forschung¶
Die ökologische Sanierung oder Verbesserung der Flüsse erfordert unter anderem Informationen über bevorzugte Wassertiefen und Strömungsgeschwindigkeiten von Zielfischarten. Diese Informationen werden von Biologen erstellt und dann oft in Form von sogenannten habitat Eignungsindex (HSI)Kurven in Arbeitsmappenformaten bereitgestellt. Typischerweise produzieren wir geospatial explizite Daten über Wassertiefe und Strömungsgeschwindigkeit mit numerischen Modellen. Die Ausgabe von zwei oder dreidimensionalen numerischen Modellen ist viel zu groß, um mit Büroanwendungen zu handhaben. Wir brauchen also ein fortschrittliches Tool, wie Python, um die geospatial expliziten Daten zu verarbeiten und HSI-Kurven von Arbeitsmappen zu lesen und zu interpolieren. Wie sieht das technisch aus? Die exercises on geospatial Python lässt Sie in den aquatischen Lebensraum (Bewertungen) eintauchen.
JSON¶
JavaScript Object Notation (JSON) Dateien haben eine ähnliche Struktur wie XML und ermöglichen die strukturierte Speicherung von (menschlesbaren) Daten. Zum Beispiel verwendet der Zahlencode BASEMENT v.3.x (read more in the numerical modeling chapter) eine model.json und eine simulation.json-Datei, um Modell-Setup-Parameter wie Materialeigenschaften zu speichern. So beinhaltet die Automatisierung von numerischen Modelleinstellungen mit Python die Änderung von Modellparametern, die in json-Dateien gespeichert sind. Hier geht Python mit dem JSON Paket und pandas’ JSON Modulen ein.
JSON Dateistruktur¶
Eine JSON-Datei besteht aus zwei Arten von Datenstrukturen, die diktionäre Objekte und arrays in Form von Listen von Werten sind. Die dictionary-Objekte in einer JSON-Datei entsprechen dem gleichen Format, das wir bereits in Python kennen: Paare von keys (Namen) und Werte, die von Curly Brackets (braces) {"name": value} umfasst sind. Die value kann ein string, numeric, eine komma-separierte list[] (array) von Daten oder ein anderes Dictionary sein.
Das folgende Beispiel zeigt eine JSON-Datei namens river_struct.json mit einer RIVER-Taste, die ein geschachteltes Wörterbuch als Wert hat. Der Wert-Dictionary enthält drei Schlüssel (NAME,GEOMETRY und HYDRAULICS).
{
"RIVER": {
"NAME": "Vanilla Flow",
"GEOMETRY": {
"REGIONS": [
{
"type": "wet",
"name": "riverbed"
},
{
"type": "dry",
"name": "floodplain"
}
],
"FLOWBOUNDARIES": [
{
"name": "Inflow",
"nodes": [1, 3, 7, 31]
},
{
"name": "Outflow",
"nodes": [89, 90, 76, 69, 95]
}
]
},
"HYDRAULICS": {
"BOUNDARY": [
{
"discharge_file": "/simulation/directory/Inflow.txt",
"name": "Inflow",
"slope": 0.005,
"type": "hydrograph"
},
{
"name": "Outflow",
"type": "zero_gradient"
}
],
"FRICTION": {
"cobble": 20.0,
"gravel": 26.0,
"sand": 41
}
},
"LOCATION": [48.744079, 9.103928]
}
}{'RIVER': {'NAME': 'Vanilla Flow',
'GEOMETRY': {'REGIONS': [{'type': 'wet', 'name': 'riverbed'},
{'type': 'dry', 'name': 'floodplain'}],
'FLOWBOUNDARIES': [{'name': 'Inflow', 'nodes': [1, 3, 7, 31]},
{'name': 'Outflow', 'nodes': [89, 90, 76, 69, 95]}]},
'HYDRAULICS': {'BOUNDARY': [{'discharge_file': '/simulation/directory/Inflow.txt',
'name': 'Inflow',
'slope': 0.005,
'type': 'hydrograph'},
{'name': 'Outflow', 'type': 'zero_gradient'}],
'FRICTION': {'cobble': 20.0, 'gravel': 26.0, 'sand': 41}},
'LOCATION': [48.744079, 9.103928]}}Lesen (Decode) und Schreiben (Encode) JSON-Dateien mit der json Bibliothek¶
JSON-Dateien können in vielen Programmiersprachen implementiert werden, einschließlich HTML und Python. Deshalb können Jupyter Notebooks (wie in diesem eBook verwendet) auch in Python ausgeführt und als Webseite angezeigt werden. Python verfügt über eine integrierte json Bibliothek, die JSON-Dekodierung und Codierung ermöglicht. Die json Bibliothek bietet eine json.dumps(DATA) Methode an “dump” (d.h. encode) Daten im JSON-Format. Die json.load()-Funktion liest Daten aus JSON-Dateien. Das folgende Beispiel veranschaulicht die Kodierung und Dekodierung eines willkürlich geschachtelten Datensatzes mit der json Bibliothek.
import json
# create arbitrary nested data (list, dictionary, tuple)
data_for_json = ["list_element1", {"dict_key": ("tuple_element", "text", 1.0, None)}]
# create a json file
json_file = open("data/my-first.json", mode="w+")
# encode the random nested data list in json format and write to file
json_file.write(json.dumps(data_for_json))
# close file
json_file.close()
# re-open the json file to read data
with open("data/my-first.json", mode="r") as re_opened_file:
raw_data = re_opened_file.readline()
# decode json data in a Python variable
data_from_json = json.loads(raw_data)
print(json.dumps(data_from_json))["list_element1", {"dict_key": ["tuple_element", "text", 1.0, null]}]
Die Python docs bietet weitere Optionen und Beschreibungen über die Bibliothek json. Hier werden wir jedoch (noch einmal) die pandas-Bibliothek nutzen, die leistungsstarke Funktionen für die Handhabung von Json-Daten bietet.
Lesen (Decode) und Schreiben (Encode) JSON-Dateien mit pandas¶
pandas (recalldata and file handling with pandas) ermöglicht das Lesen von JSON-Dateien in sein bequemes Tabellenformat mit eingebetteter Nutzung der jsonBibliothek. Der folgende Codeblock verwendet die pandas.read json(FILE)-Funktion, um die oben dargestellte RIVER-Probendatei zu lesen (download river struct.json).
import pandas as pd
river = pd.read_json("data/river_struct.json")
print(river) RIVER
NAME Vanilla Flow
GEOMETRY {'REGIONS': [{'type': 'wet', 'name': 'riverbed...
HYDRAULICS {'BOUNDARY': [{'discharge_file': '/simulation/...
LOCATION [48.744079, 9.103928]
Da ein Fluss ohne Daten wie Eis ohne Geschmack ist, werden wir der Datenstruktur (random) Daten über Fließeigenschaften hinzufügen. Nehmen wir an, dass wir die Daten von river_struct.json verwendet haben, um eine stationäre Entladung in einem zweidimensionalen numerischen Modell zu simulieren. Als Ergebnis haben wir zwei regelmäßige Gitter (Arrays) mit Daten über Strömungsgeschwindigkeit und Wassertiefe. Nun wollen wir sowohl die Strömungsgeschwindigkeit als auch die Wassertiefe Arrays in Form einer Ergebnisstruktur (diktionär) an river_struct.json anhängen und dem Fluss einen neuen Namen geben.
# create random data
import numpy as np
h = np.random.weibull(np.arange(0,100)).reshape(10, 10)
u = np.random.weibull(np.arange(0,100)).reshape(10, 10)
# append RESULTS row to pandas dataframe
river_dict = river.to_dict()
river_dict["RIVER"].update({"RESULTS": {"water_depth": h, "flow_velocity": u}})
updated_river = pd.DataFrame.from_dict(river_dict)
# re-NAME RIVER
updated_river.loc["NAME", "RIVER"] = "Honey river"
print(updated_river)
# export to JSON
updated_river.to_json("data/river_results.json") RIVER
NAME Honey river
GEOMETRY {'REGIONS': [{'type': 'wet', 'name': 'riverbed...
HYDRAULICS {'BOUNDARY': [{'discharge_file': '/simulation/...
LOCATION [48.744079, 9.103928]
RESULTS {'water_depth': [[0.0, 1.4016850027236283, 0.6...
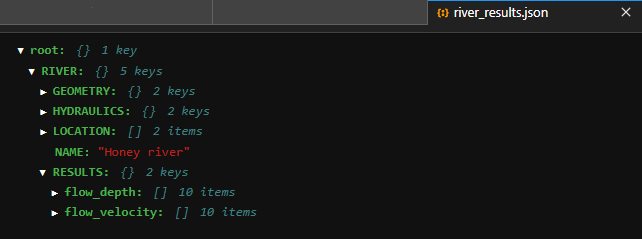
Figure 4:Das daraus resultierende Arbeitsbuch.
