Bereiten Sie sich durch Klonen des Übungs-Repository:
git clone https://github.com/Ecohydraulics/Exercise-SedimentTransport.git
Figure 1:Der Arbogne River in der Schweiz (Quelle: Sebastian Schwindt 2013).
Theorie¶
1d Querschnitt Durchschnittliche Hydrodynamik¶
Aus der State-Decharge (Manning-Strickler-Formel) Bewegung wenden wir uns an die Formel, um die Beziehung zwischen Wassertiefe (in den Hydraulikradius ) und Fließgeschwindigkeit zu berechnen:
wenn
ist der Manning Koeffizient in fictional Einheiten von (s/m.
ist die hypothetische Energieneigung (m/m) und entspricht der Kanalneigung für stetige, gleichmäßige Strömungsbedingungen (nicht vorhanden in natürlichen Flüssen).
Hydraulikradius , wo (für einen trapezförmigen Querschnitt):
die benetzte (trapezoidale) Querschnittsfläche ist ;
der benetzte Umfang eines Trapezes ist ;
(Kanal-Basisbreite) und (Bankflanke) sind in der folgenden Abbildung dargestellt, um die tiefenabhängige Wasseroberflächenbreite zu berechnen.
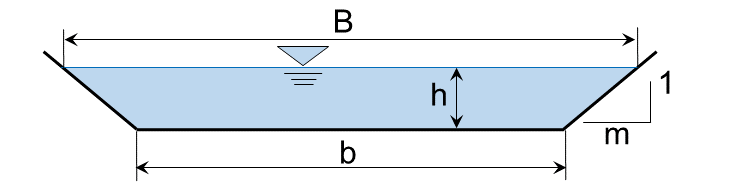
This exercise uses one-dimensional (1d) cross-section averaged hydraulic data produced with the US Army Corps of Engineers HEC-RAS software U.S. Army Corps of Engineeers, 2016, which solves the Manning-Strickler formula numerically for any flow cross-section shape. In this exercise, HEC-RAS provides the hydraulic data needed to determine the sediment transport capacity of a channel cross-section, although no explanations for creating, running, and exporting data from HEC-RAS models are given.
Sediment Transport¶
Fluvial Sediment transport kann in zwei Modi unterschieden werden: (1) suspended load und (2) bedload (sieheFig. 3). Finer-Partikel mit einem Gewicht, das von der Flüssigkeit (Wasser) getragen werden kann, werden als suspended load transportiert. Coarser-Partikel rollen, gleiten und springen auf dem Kanalbett werden als bedload transportiert. Es gibt eine andere Art von Transport, die sogenannte Waschlast, die feiner ist als die grobe bedload, aber zu schwer (groß) in Suspension zu transportierenEinstein, 1950.

Figure 3:Zwei Arten des Sedimenttransports (Quelle: Schwindt, 2017).
Im Folgenden werden wir uns den Transportmodus bedload anschauen. In diesem Fall wird ein im oder am Flussbett befindliches Sedimentpartikel durch Scherkräfte des Wassers mobilisiert, sobald sie einen kritischen Wert überschreiten (siehe Abbildung unten). In der Flusshydraulik wird oft der sogenannte dimensionslose Bettscherbeanspruchung oder Shields stressShields, 1936 als Schwellenwert für die Mobilisierung von Sediment aus dem Flussbett verwendet (siehe Fig. 4). Diese Übung verwendet eine der dimensionslosen Bettscherbeanspruchungen und der nächste Abschnitt gibt mehr Erläuterungen.
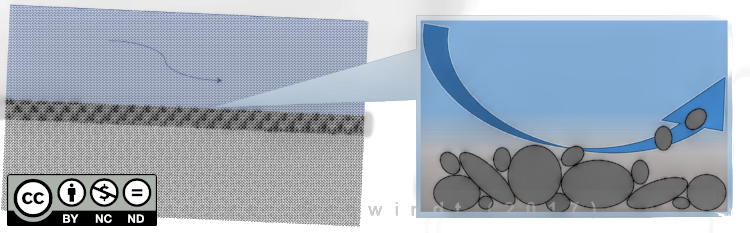
Figure 4:Das Prinzip der Sedimentmobilisierung.
Die Meyer-Peter und Müller (1948) Formel¶
Die Meyer-Peter & Müller (1948) Formel für die Schätzung bedloadTransport wurde von Schweizer Forschern Eugen Meyer-Peter (Gründer des Laboratoriums für Hydraulik, Hydrologie und Glaciologie (VAW) und Robert Müller) veröffentlicht. Ihre Studie begann ein Jahr nach der Gründung der VAW 1931, als Robert Müller zum Assistenten von Eugen Meyer-Peter ernannt wurde. Die beiden Wissenschaftler arbeiteten in Zusammenarbeit mit Henry Favre und Albert Einsteins Sohn Hans Albert. Im Jahr 1934 veröffentlichte das Labor erstmals eine Formel für die Berechnung von bedloadTransport und dessen grundlegende Beziehung zwischen beobachteten und kritischen dimensionslosen Bettscherspannungen bis heute. Die dimensionslose bedload Transportrate laut Meyer-Peter & Müller (1948) ist:
Die anderen Parameter sind:
2.68, the dimensionless ratio of sediment grain density ( 2680 kg/m³) and water density ( 1000 kg/m³);
, die charakteristische Korngröße in (m). Es kann davon ausgegangen werden, dass (d.h. der Korndurchmesser, dessen 84% eines Sedimentgemisches kleiner ist) entsprechend der wissenschaftlichen Literatur (z.B. Rickenmann & Recking (2011)) entspricht.
Die Meyer-Peter & Müller-Formel gilt (wie jede andere Sediment transport-Formel) nur für bestimmte Flüsse, die folgende Eigenschaften haben (Validitätsbereich):
10m@m < 28,610m
10 m 639 ( denotes the dimensionless Froude number)
0,00040,02
0,0002 m/(s m) 2.0 m/(sm) ( ist die Einheitsentladung, d.h.)
0,25 3.2
The dimensionless expression for bedload was used to enable information transfer between different channels across scales by preserving geometric, kinematic, and dynamic similarity. The set of dimensionless parameters used results from Buckingham’s theorem Buckingham, 1915. Therefore, to add dimensions to , it needs to be multiplied with the same set of parameters used for deriving the dimensionless expression from Meyer-Peter & Müller. Their set of parameters involves the characteristic grain size , the grain density , and the gravitational acceleration . Thus, the dimensional unit bedload is (in kg/s and meter width, i.e., kg/(sm):
The cross-section averaged bedload (kg/s) is then:
wobei die hydraulisch aktive Kanalbreite des Strömungsquerschnitts ist (z.B. für einen Trapezoid ).
Code¶
Setzen Sie den Rahmen¶
Der objektorientierte Code verwendet benutzerdefinierte Klassen, die wir in einem *main.py Script anrufen. Erstellen Sie die folgenden zusätzlichen Skripte, die die benutzerdefinierten Klassen und Funktionen enthalten, um das Protokoll zu steuern.
fun.pyenthält Protokollfunktionen.hec.pywird eineHecSet-Klasse enthalten, um hydraulische Ausgangsdaten von HEC-RAS als strukturierte Objekte zu lesen.grains.pywird eineGrainReader-Klasse enthalten, um Informationen zur Korngrößenklasse als strukturierte Objekte zu lesen.bedload.pyenthält die KlasseBedCoremit den Grundelementen, die die meisten bedload Formeln gemeinsam haben.mpm.pyenthält die KlasseMPM, die vonBedCorevererbt wird und wie oben beschrieben bedload berechnet (Meyer-Peter & Müller 1948).
Wir erstellen die Klassen und Funktionen in den angegebenen Skripten nach dem folgenden Flussdiagramm:
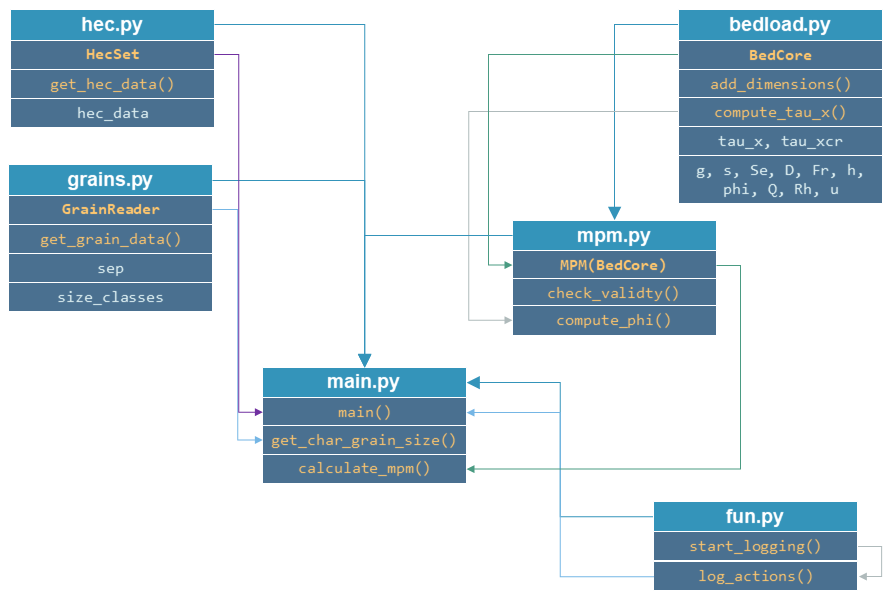
Um mit dem main.pyScript zu beginnen, fügen Sie eine main-Funktion sowie eine get_char_grain_size und eine calculate_mpm-Funktion hinzu. Außerdem machen Sie das Skript stand-alone ausführbar:
# This is main.py
import os
def get_char_grain_size(file_name, D_char):
return None
def calculate_mpm(hec_df, D_char):
return None
def main():
pass
if __name__ == '__main__':
main()
Logging Funktionen¶
Das fun.pyScript enthält zwei Funktionen:
start_logging, um Logging-Formate und einen Log-Dateinamen wie im Abschnitt unter logging beschrieben, undlog_actions, das ist ein Funktions-Wrapper für diemain()(main.py) Funktionen, um Skriptausführungsnachrichten zu protokollieren.
Die start_logging-Funktion sollte so aussehen (gegebenenfalls den Log-Dateinamen ändern):
import logging
def start_logging():
logging.basicConfig(filename="logfile.log", format="[%(asctime)s] %(message)s",
filemode="w", level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler()
Die log_actionsWrapper-Funktion folgt den Anweisungen des functions theory section:
def log_actions(fun):
def wrapper(*args, **kwargs):
start_logging()
fun(*args, **kwargs)
logging.shutdown()
return wrapperUm den log_actionspackper im gesamten Programm zu nutzen, setzen wir ihn auf höchstem Niveau um, das ist die main()-Funktion inmain.py:
# main.py
from fun import *
...
@log_actions
def main():
logging.info("This is a test message (do not keep in the function).")
if __name__ == '__main__':
main()
Nun können wir Meldungen auf verschiedenen Ebenen (Info, Warnung, Fehler oder andere) in allen Funktionen, die unter main() aufgerufen werden, unter Verwendung von z.B. logging.info("Message"), logging.warning("Message") oder logging.error("Message") anstelle der print()-Funktion anmelden.
Korngrößendaten lesen¶
Sediment grain size classes (ranging from to ) are provided in the file grains.csv (delimiter=",") and can be customized.
Schreiben Sie eine GrainReader-Klasse, die die read_csv-Methode von Pandas verwendet, um die Korngrößenverteilung von grains.csv zu lesen. Schreiben Sie die Klasse in einem separaten Python-Skript (z.B. grains.py, wie in der obigen Abbildung angegeben):
class GrainReader:
def __init__(self, csv_file_name="grains.csv", delimiter=","):
self.sep = delimiter
self.size_classes = pd.DataFrame
self.get_grain_data(csv_file_name)Die get_grain_data-Methode sollte so aussehen, um die bereitgestellten Korngrößenklassen zu lesen:
def get_grain_data(self, csv_file_name):
self.size_classes = pd.read_csv(csv_file_name,
names=["classes", "size"],
skiprows=[0],
sep=self.sep,
index_col=["classes"])Ergänzen Sie die Instantiation eines GrainReaderObjekts im main.pyScript in der get_char_grain_size Funktion. Die Funktion sollte die string-Argumente file_name (hier:"grains.csv") und D_char (d.h. die charakteristische Korngröße von grains.csv) erhalten. Die main()-Funktion ruft die get_char_grain_size-Funktion mit den Argumenten file_name=os.path.abspath("..") + "\\grains.csv" und D_char="D84" auf (entspricht der ersten Spalte unter grains.csv).
# main.py
import os
from grains import GrainReader
def get_char_grain_size(file_name=str, D_char=str):
grain_info = GrainReader(file_name)
return grain_info.size_classes["size"][D_char]
...
@log_actions
def main():
# get characteristic grain size = D84
D_char = get_char_grain_size(file_name=os.path.abspath("..") + "\\grains.csv",
D_char="D84")HEC-RAS Eingabedaten lesen¶
The provided HEC-RAS dataset is stored in the xlsx workbook HEC-RAS/output.xlsx and contains the following output:
| **Col.No.**Alphabetic Col.Variable Typ/Unit Beschreibung |
|---|
| Col. 01 |
| Col. 02 |
| Col. 03 |
| Col. 04 |
| Col. 05 |
| Col. 06 |
| Col. 07 |
| Col. 08 |
| Col. 09 |
| Col. 10 |
| Col. 11 |
| Col. 12 |
Um HEC-RAS Ausgabedaten zu laden, schreiben Sie eine benutzerdefinierte Klasse (in einem separaten Skript namens hec.py), das den Dateinamen als Eingabeargument nimmt und die HEC-RAS-Datei als pandas Datenrahmen liest:
class HecSet:
def __init__(self, xlsx_file_name="output.xlsx"):
self.hec_data = pd.DataFrame
self.get_hec_data(xlsx_file_name)Die get_hec_data Methode sollte so aussehen (etwas):
def get_hec_data(self, xlsx_file_name):
self.hec_data = pd.read_excel(xlsx_file_name,
skiprows=[1],
header=[0])Um ein HecSet-Objekt in der main() (main.py)-Funktion zu erstellen, müssen wir es z.B. als hec = HecSet(file_name) importieren und umgehen. Darüber hinaus können wir bereits die pd.DataFrame der HEC-RAS-Daten an die calculate_mpm-Funktion (auch unter main.py) weitergeben, die wir später abschließen werden.
# main.py
import os
from ...
from hec import HecSet
...
@log_actions
def main():
D_char = ...
hec_file = os.path.abspath("..") + "{0}HEC-RAS{0}output.xlsx".format(os.sep)
hec = HecSet(hec_file)Erstellen Sie eine Geschiebetransport Core Class¶
Eine im bedload.py-Skript geschriebene BedCore-Klasse liefert Variablen und Methoden, die für viele bedload und Sediment transportBerechnungsformeln relevant sind, wie z.B. die Parker-Wong-Korrektur Wong & Parker, 2006 oder die Smart & Jaeggi (1983) (direct download ]. Darüber hinaus enthält die BedCore-Klasse Konstanten wie die Gravitationsbeschleunigung (d.h.self.g=9.81), das Verhältnis von Sedimentkorn und Wasserdichte (d.h. self.s=2.68) und den kritischen dimensionslosen Bettscherstress (d.h.self.tau_xcr=0.047, die von den Nutzern neu definiert werden kann). Der Header der BedCore-Klasse sollte so aussehen (ähnlich):
from fun import *
import numpy as np
class BedCore:
def __init__(self):
self.tau_x = np.nan
self.tau_xcr = 0.047
self.g = 9.81
self.s = 2.68
self.rho_s = 2680.0 # kg/m3 sediment grain density
self.Se = np.nan # energy slope (m/m)
self.D = np.nan # characteristic grain size
self.Fr = np.nan # Froude number
self.h = np.nan # water depth (m)
self.phi = np.nan # dimensionless bedload
self.Q = np.nan # discharge (m3/s)
self.Rh = np.nan # hydraulic radius (m)
self.u = np.nan # flow velocity (m/s)Fügen Sie eine Methode hinzu, um den dimensionslosen bedload transport in einen Maßwert umzuwandeln (kg/s). Neben den Variablen, die in der __init__-Methode definiert sind, benötigt die add_dimensions-Methode die effektive Kanalbreite (recall the above calculus):
def add_dimensions(self, b):
try:
return self.phi * b * np.sqrt((self.s - 1) * self.g * self.D ** 3) * self.rho_s
except ValueError:
logging.warning("Non-numeric data. Returning Qb=NaN.")
return np.nanViele bedload Transportformeln beinhalten die dimensionslose Bettscherbeanspruchung [ (siehe oben definitions) mit einem Satz von durchschnittenen hydraulischen Parametern. Deshalb die Berechnungsmethode compute_tau_x in BedCore:
def compute_tau_x(self):
try:
return self.Se * self.Rh / ((self.s - 1) * self.D)
except ValueError:
logging.warning("Non-numeric data. Returning tau_x=NaN.")
return np.nanSchreibe eine Meyer-Peter & Müller Geschiebetransport Assessment Class¶
Create a new script (e.g., mpm.py) and implement an MPM class (Meyer-Peter & Müller) that inherits from the BedCore class. The __init__ method of MPM should initialize BedCore and overwrite (recall Polymorph) relevant parameters to the calculation of bedload according to Meyer-Peter & Müller (1948). Moreover, the initialization of an MPM object should go along with a check of the validity and the calculation of the dimensionless bedload transport (see above explanations of MPM):
from bedload import *
class MPM(BedCore):
def __init__(self, grain_size, Froude, water_depth,
velocity, Q, hydraulic_radius, slope):
# initialize parent class
BedCore.__init__(self)
# assign parameters from arguments
self.D = grain_size
self.h = water_depth
self.Q = Q
self.Se = slope
self.Rh = hydraulic_radius
self.u = velocity
self.check_validity(Froude)
self.compute_phi()Fügen Sie die check_validity-Methode hinzu, um zu überprüfen, ob die bereitgestellten Querschnittseigenschaften in den Gültigkeitsbereich der Meyer-Peter & Müller-Formel fallen (d.h. Steigung, Korngröße, Austritts- und Wassertiefe und Froude number):
def check_validity(self, Fr):
if (self.Se < 0.0004) or (self.Se > 0.02):
logging.warning('Warning: Slope out of validity range.')
if (self.D < 0.0004) or (self.D > 0.0286):
logging.warning('Warning: Grain size out of validity range.')
if ((self.u * self.h) < 0.002) or ((self.u * self.h) > 2.0):
logging.warning('Warning: Discharge out of validity range.')
if (self.s < 0.25) or (self.s > 3.2):
logging.warning('Warning: Relative grain density (s) out of validity range.')
if (Fr < 0.0001) or (Fr > 639):
logging.warning('Warning: Froude number out of validity range.')Um dimensionslose bedload transport nach Meyer-Peter & Müller zu berechnen, implementieren Sie eine compute_phi Methode, die die compute_tau_x Methode von BedCore verwendet:
def compute_phi(self):
tau_x = self.compute_tau_x()
try:
if tau_x > self.tau_xcr:
self.phi = 8 * (0.85 * tau_x - self.tau_xcr) ** (3 / 2)
else:
self.phi = 0.0
except TypeError:
logging.warning("Could not calculate PHI (result=%s)." % str(tau_x)
self.phi = np.nanMit der definierten MPM-Klasse können wir nun die calculate_mpm-Funktion im main.py-Skript ausfüllen. Die Funktion sollte einen pandas-Datenrahmen mit spalten von dimensionslosen bedload transport und dimensionalbedload transport erstellen, der mit einem Kanalprofil ("River Sta") und einem Flow-Szenario ("Profile" > "Scenario") verbunden ist.
Der folgende Codeblock zeigt ein Beispiel der calculate_mpm-Funktion, die den pandas-Datenrahmen aus einem Wörterbuch (mpm_dict) erstellt. Die illustrative Funktion erstellt das dictionary mit Leerwertlisten, extrahiert hydraulische Daten aus dem HEC-RAS Datenrahmen und Schleifen über die "River Sta"Einträge. Die Schleife überprüft, ob die "River Sta"-Einträge gültig sind (d.h. nicht "Nan"), da leere Zeilen, die HEC-RAS automatisch zwischen Ausgabeprofilen addiert, nicht analysiert werden sollten. Wenn die Prüfung erfolgreich war, fügt die Schleife das Profil, das Szenario und die Entladung direkt an mpm_dict. Der abschnittsweise bedload transport ergibt sich aus MPMObjekten. Nach der Schleife gibt die Funktion mpm_dict als pd.DataFrameobjekt zurück.
# main.py
from ...
from ...
from mpm import *
...
def calculate_mpm(hec_df, D_char):
# create dictionary with relevant information about bedload transport with void lists
mpm_dict = {
"River Sta": [],
"Scenario": [],
"Q (m3/s)": [],
"Phi (-)": [],
"Qb (kg/s)": []
}
# extract relevant hydraulic data from HEC-RAS output file
Froude = hec_df["Froude # Chl"]
h = hec_df["Hydr Depth"]
Q = hec_df["Q Total"]
Rh = hec_df["Hydr Radius"]
Se = hec_df["E.G. Slope"]
u = hec_df["Vel Chnl"]
for i, sta in enumerate(list(hec_df["River Sta"]):
if not str(sta).lower() == "nan":
logging.info("PROCESSING PROFILE {0} FOR SCENARIO {1}".format(str(hec_df["River Sta"][i]), str(hec_df["Profile"][i]))
mpm_dict["River Sta"].append(hec_df["River Sta"][i])
mpm_dict["Scenario"].append(hec_df["Profile"][i])
section_mpm = MPM(grain_size=D_char,
Froude=Froude[i],
water_depth=h[i],
velocity=u[i],
Q=Q[i],
hydraulic_radius=Rh[i],
slope=Se[i])
mpm_dict["Q (m3/s)"].append(Q[i])
mpm_dict["Phi (-)"].append(section_mpm.phi)
b = hec_df["Flow Area"][i] / h[i]
mpm_dict["Qb (kg/s)"].append(section_mpm.add_dimensions(b)
return pd.DataFrame(mpm_dict)Nach der Definition der calculate_mpm()-Funktion sollte der Anruf an diese Funktion aus der main()-Funktion nun einen Pandas-Datenrahmen an die mpm_results-Variable vergeben. Um das Skript abzuschließen, schreiben Sie mpm_results an ein Arbeitsbuch (z.B. "bed_load_mpm.xlsx") in der main()-Funktion:
# main.py
import os
from ...
...
def calculate_mpm(hec_df, D_char):
...
@log_actions
def main():
...
mpm_results = calculate_mpm(hec.hec_data, D_char)
mpm_results.to_excel(os.path.abspath("..") + os.sep + "bed_load_mpm.xlsx")Start und Debug¶
In your IDE, run the script (e.g., in PyCharm, right-click in the main.py script and click > Run 'main'). If the script crashes or raises error messages, trace them back, and fix the issues. Add try - except statements where necessary and recall the debugging instructions.
Ein erfolgreicher Lauf von main.py erzeugt eine bed_load_mpm.xlsx-Datei, die so aussieht:
| | River Sta | Scenario | Q (m3/s) | Phi (-) | Qb (kg/s) |¶
| 0 | 1970.1 | Q bedeuten | 1 | | | | | 1 | 1970.1 | HQ2.33 | 13 | 0.548377243 | 42.72291418 | | 2 | 1970.1 | HQ5 | 17 | 0.682792055 | 54.58338633 | | 3 | 1970.1 | HQ10 | 19 | 0.765834516 | 62.560105 | | 4 | 1970.1 | HQ100 | 25 | 0.905542967 | 77.92848176 | | 5 | 1893.37 | Q mean | 1 | 0.193642263 | 5.075423967 | | 6 | 1893.37 | HQ2.33 | 13 | 0.144406226 | 14.00424884 | | 7 | 1893.37 | HQ5 | 17 | 0.203854633 | 20.40484039 | | 8 | 1893.37 | HQ10 | 19 | 0.229078172 | 23.1352098 | | 9 | 1893.37 | HQ100 | 25 | 0.297767546 | 31.25225316 | ...
Das Logfile sollte so ähnlich aussehen:
[20XX-XX-XX 14:08:22,900] PROCESSING PROFILE 1970.1 FOR SCENARIO Q mean
[20XX-XX-XX 14:08:22,900] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,901] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ2.33
[20XX-XX-XX 14:08:22,901] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,901] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ5
[20XX-XX-XX 14:08:22,902] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,902] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ10
[20XX-XX-XX 14:08:22,902] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,902] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ100
[20XX-XX-XX 14:08:22,903] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,903] PROCESSING PROFILE 1893.37 FOR SCENARIO Q mean
[20XX-XX-XX 14:08:22,903] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,903] PROCESSING PROFILE 1893.37 FOR SCENARIO HQ2.33
[20XX-XX-XX 14:08:22,903] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,904] PROCESSING PROFILE 1893.37 FOR SCENARIO HQ5
[20XX-XX-XX 14:08:22,904] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,904] PROCESSING PROFILE 1893.37 FOR SCENARIO HQ10
[20XX-XX-XX 14:08:22,904] Warning: Discharge out of validity range.
[...]- U.S. Army Corps of Engineeers. (2016). Hydrologic Engineering Centers River Analysis System (HEC-RAS). U.S. Army Corps of Engineeers (USACE). http://www.hec.usace.army.mil/software/hec-ras/
- Einstein, H. A. (1950). The Bed-Load Function for Sediment Transport in Open Channel Flows. Technical Bulletin of the USDA Soil Conservation Service, 1026, 71. 10.22004/ag.econ.156389
- Schwindt, S. (2017). Hydro-morphological processes through permeable sediment traps [Thesis No. 7655, Laboratory of Hydraulic Constructions (LCH), Ecole Polytechnique fédérale de Lausanne (EPFL)]. 10.5075/epfl-thesis-7655
- Shields, A. (1936). Anwendung der Ähnlichkeitsmechanik und der Turbulenzforschung auf die Geschiebebewegung [Application of the similarity in mechanics and turbulence research on the mobility of bed load] (Vol. 26). Preußische Versuchsanstalt für Wasserbau und Schiffbau. http://resolver.tudelft.nl/uuid:61a19716-a994-4942-9906-f680eb9952d6
- Meyer-Peter, E., & Müller, R. (1948). Formulas for Bed-Load transport. IAHSR, Appendix 2, 2nd meeting, 39–65. http://resolver.tudelft.nl/uuid:4fda9b61-be28-4703-ab06-43cdc2a21bd7
- Rickenmann, D., & Recking, A. (2011). Evaluation of flow resistance in gravel-bed rivers through a large field data set. Water Resources Research, 47, W07538. 10.1029/2010WR009793
- Buckingham, E. (1915). Model experiments and the forms of empirical equations. Transactions of the American Society of Mechanical Engineers, 37, 263–296.
- Wong, M., & Parker, G. (2006). Reanalysis and Correction of Bed-Load Relation of Meyer-Peter and Müller Using Their Own Database. Journal of Hydraulic Engineering, 132(11), 1159–1168. 10.1061/(ASCE)0733-9429(2006)132:11(1159)
- Smart, G. M., & Jaeggi, M. N. R. (1983). Sedimenttransport in steilen Gerinnen [Sediment Transport on Steep Slopes]. Mitteilung Nr. 64 der Versuchsanstalt für Wasserbau, Hydrologie und Glaziologie an der Eidgenössischen Technischen Hochschule Zürich. https://ethz.ch/content/dam/ethz/special-interest/baug/vaw/vaw-dam/documents/das-institut/mitteilungen/1980-1989/064.pdf
- Schwindt, S., Negreiros, B., Mudiaga-Ojemu, B. O., & Hassan, M. A. (2023). Meta-Analysis of a Large Bedload Transport Rate Dataset. Geomorphology, 435, 108748. 10.1016/j.geomorph.2023.108748