Basic (text) file handling, NumPy, pandas, and DateTime. For interactive reading and executing code blocks  and find b06-pynum.ipynb or Python (Installation) locally along with JupyterLab.
and find b06-pynum.ipynb or Python (Installation) locally along with JupyterLab.
Watch this section in video format
Watch this section as a video on the @hydroinformatics channel on YouTube.
Einfache Datendateien laden und schreiben¶
Daten können in vielen verschiedenen (Text-)Dateiformaten wie txt oder csv Dateien gespeichert werden. Python bietet die Funktionen open(file) und write(...), um Daten aus fast jedem Textdateiformat zu lesen und zu schreiben. Darüber hinaus gibt es Pakete wie csv (für csv-Dateien), die die Handhabung bestimmter Dateitypen vereinfachen. Die folgenden Abschnitte illustrieren die Nutzung der Funktionen open(file) und write(...). Das später gezeigte pandas Modul bietet mehr Funktionen zum Import und Export von numerischen Daten zusammen mit Zeilen- und Spaltenkopfzeilen.
Dateidaten laden (Öffnen) Textdatei¶
Der Befehl open lädt Textdateien als Dateiobjekt in Python ein. Die Syntax des Befehls open lautet:
open("file-name", "mode")Wo:
file-nameist die zu öffnende Datei (z.B."data.txt"); wenn die Datei nicht im Skriptverzeichnis ist, muss der filename durch das vollständige Verzeichnis (Pfad) auf die Datendatei (z.B."C:/experiment1/data.txt") erweitert werden.modedefiniert den Zugangstyp und kann folgende Werte annehmen:"r"- read-only (Standardwert, wenn kein"mode"-Wert bereitgestellt wird); die Datei kann nicht geändert oder überschrieben werden."rb"- nur im Binärformat gelesen; das Binärformat ist vorteilhaft, wenn die Datei keine Textdatei ist, sondern Medien wie Bilder oder Videos."r+"- lesen und schreiben."w"- schreiben-only; eine neue Datei wird erstellt, wenn eine Datei mit der bereitgestelltenfile-namenoch nicht existiert."wb"- Nur schriftlich im binären Modus."w+"- erstellen, schreiben und lesen."wb+"- Schreiben und lesen Sie im binären Modus."a"- Neue Daten an eine Datei anhängen; der Schreibpointer wird am Ende der Datei platziert und eine neue Datei erstellt, wenn noch keine Datei mit der bereitgestelltenfile nameexistiert."ab"- Neue Daten im Binärmodus anhängen."a+"- beide anhängen (am Ende schreiben) und lesen."ab+"- Daten im Binärmodus anhängen und lesen.
Wenn "r" oder "w"-Modi verwendet werden, wird der Dateizeiger (d.h. der blinkende Cursor, den Sie beispielsweise in Word-Dokumenten sehen können) zu Beginn der Datei platziert. Für "a"-Modi wird der Dateizeiger am Ende der Datei platziert.
Es ist eine gute Praxis, Daten von und zu einer Datei innerhalb einer with-Anweisung zu lesen und zu schreiben, um Probleme beim Dateischloss zu vermeiden. Beispielsweise erstellt der folgende Codeblock eine neue Textdatei innerhalb einer with-Anweisung:
with open("data/new.csv", mode="w+") as file:
file.write("And yet it moves.")Nur lesen¶
Once the file object is created, we can parse the file and copy the file data content to a desired Python data type (e.g., a list, tuple or dictionary). Parsing the data works with for-loops (other loop types will also work) to iterate on lines and line entries. The lines represent strings and data columns can be separated by using the built-in string function line_as_list = str().split("SEPARATOR"), where "SEPARATOR" can be "," (comma), ";" (semicolon), "\t" (tab), or any other sign. After reading all data from a file, use file_object.close() to avoid that the file is locked by Python and cannot be opened by another program.
Das folgende Beispiel öffnet eine Textdatei namens pure-numbers.txt (download pure-numbers.txt in einen lokalen Unterordner namens data), der float-Nummern zwischen 0,0 und 10.0 enthält. Die Datei verfügt über 17 Datenzeilen (z.B. für 17 Versuchsläufe) und 4 Datenspalten (z.B. für 4 Messungen pro Versuchslauf), die durch einen TAB ("\t" Separator) getrennt werden. Der folgende Codeblock verwendet die eingebaute Funktion readlines(), um die Dateizeilen zu parsieren, die Zeilen über den "\t"-Separator zu spalten und die Zeileneinträge an die Listenvariable data_list nur anzufügen, wenn entry numerisch ist (verifiziert mit der try -except-Anweisung). data_list ist eine geschachtelte Liste, die zu Beginn des Skripts initiiert wird und eine Unterliste (Nebenliste) für jede Dateizeile (Reihe) angehängt wird.
file_object = open("data/pure-numbers.txt") # read file with default "mode"="r"
data_list = [] # this will be a nested list with 17 sub-lists (rows) containing 4 entries (columns)=
for line in file_object.readlines():
line_as_list = line.split("\t") # converts the line into a list using a tab (\t) separator
data_list.append([]) # append an empty sub-list for every file line (17 rows)
for entry in line_as_list:
try:
# try to append the entry as floating point number to the last sub-list, which is pointed at using [-1]
data_list[-1].append(float(entry))
except ValueError:
# if entry is not numeric, append 0.0 to the sub-list and print a warning message
print("Warning: %s is not a number. Replacing value with 0.0." % str(entry))
# verify that data_list contains the 17 rows (sub-lists) with the built-in list function __len__()
print("Number of rows: %d" % len(data_list))
# verify that the first sub-list has four entries (number of columns)
print("Number of columns: %d" % len(data_list[0]))
file_object.close() # close file (otherwise it will be locked as long as Python is still running!) alternative: use with-statement
print(data_list) # print the dataNumber of rows: 17
Number of columns: 4
[[2.202, 3.658, 0.201, 1.651], [0.904, 0.643, 1.094, 1.859], [2.104, 2.786, 2.212, 3.489], [1.181, 4.415, 0.331, 3.418], [2.203, 2.882, 0.874, 1.151], [4.044, 4.848, 1.704, 3.523], [4.407, 4.494, 0.608, 0.387], [1.015, 4.415, 0.672, 2.221], [4.798, 2.759, 3.521, 1.714], [3.495, 4.206, 0.288, 3.801], [4.947, 3.791, 1.546, 3.989], [0.695, 2.35, 4.561, 1.609], [1.581, 0.824, 0.293, 3.458], [1.216, 1.475, 2.56, 0.456], [2.956, 0.904, 3.029, 3.559], [0.691, 2.187, 3.533, 2.188], [0.44, 2.772, 3.386, 2.671]]
Erstellen und Schreiben von Dateien¶
Eine Datei wird mit den "w" oder "a"Modi erstellt (z.B. open(file_name, mode="a")).
Stellen Sie sich vor, dass die oben geladene data_list Messungen in mm darstellen und wir wissen, dass die Präzision des Messgerätes 1,0 mm beträgt. Somit liegen alle Daten kleiner als 1,0 innerhalb der Gerätefehlermarge, die wir durch Überschreiben solcher Werte mit *nan (not-a-number) von weiteren Analysen ausschließen wollen. Dazu erstellen wir zunächst eine neue Listenvariable new_data_list, wo wir nan-Werte anhängen, wenn data_list[i, j] <= 1.0 und sonst erhalten wir den ursprünglichen Zahlenwert von data_list.
Mit open("data/modified-data.csv", mode="w+") erstellen wir im Unterordner data eine neue csv (komma-separierte Werte). Ein for-loop iteriert auf den sub lists von new_data_list und schließt sie mit einem Komma-Separator an. Um den Listenelementen von i (d.h. den Sublisten) mit ", ".join(list_of_strings)" beizutreten, müssen alle Listeneinträge zuerst in strings umgerechnet werden, was durch den Ausdruck [str(e) for e in row] erreicht wird. Die "\n" string muss am Ende jeder Zeile konfektioniert werden, um eine Zeilenumbruch zu erstellen ("\n" selbst wird in der Datei nicht sichtbar sein). Der Befehl new_file.write(new_line) schreibt den unter-list-converted-to-string an die Datei "data/modified-data.csv". Wieder einmal wird new_file.close() benötigt, um zu vermeiden, dass die neue csv-Datei von Python gesperrt wird (alternativ: Verwenden Sie einen Namensraum innerhalb einer with-Anweisung).
# create a new list and overwrite all values <= 1.0 with nan
new_data_list = []
for i in data_list:
new_data_list.append([])
for j in i:
if j <= 1.0:
new_data_list[-1].append("nan")
else:
new_data_list[-1].append(j)
print(new_data_list)
# write the modified new_data_list to a new text file
new_file = open("data/modified-data.csv", mode="w+") # lets just use csv: Python does not care about the file ending (could also be file.wayne)
for row in new_data_list:
new_line = ", ".join([str(e) for e in row]) + "\n"
new_file.write(new_line)
new_file.close()
[[2.202, 3.658, 'nan', 1.651], ['nan', 'nan', 1.094, 1.859], [2.104, 2.786, 2.212, 3.489], [1.181, 4.415, 'nan', 3.418], [2.203, 2.882, 'nan', 1.151], [4.044, 4.848, 1.704, 3.523], [4.407, 4.494, 'nan', 'nan'], [1.015, 4.415, 'nan', 2.221], [4.798, 2.759, 3.521, 1.714], [3.495, 4.206, 'nan', 3.801], [4.947, 3.791, 1.546, 3.989], ['nan', 2.35, 4.561, 1.609], [1.581, 'nan', 'nan', 3.458], [1.216, 1.475, 2.56, 'nan'], [2.956, 'nan', 3.029, 3.559], ['nan', 2.187, 3.533, 2.188], ['nan', 2.772, 3.386, 2.671]]
Bestehende Dateien ändern¶
Vorhandene Textdateien können entweder mode="r+" geöffnet und geändert werden (sofern die Informationen vor der Änderung gelesen werden müssen) oder mode="a+". Rufen Sie an, dass "r+" den Pointer am Anfang der Datei platziert und "a+" den Pointer am Ende der Datei platziert. Wenn wir also Zeilen oder Einträge einer vorhandenen Datei ändern wollen, ist "r+" die gute Wahl und wenn wir Daten am Ende der Datei anhängen möchten, ist "a" die gute Wahl (+ ist im Fall von "a" nicht unbedingt erforderlich). Dieser Abschnitt zeigt zwei Beispiele: (1) Änderung bestehender Daten in einer Datei mit "r+" und (2) Anwenden von Daten an eine bestehende Datei mit "a".
- Beispiel 1 - Ersetzen Sie Daten in einer vorhandenen Datei mit
"r+" Im vorherigen Codeblock eliminieren wir alle Messungen, die wegen der Präzision des Messgerätes kleiner als 1 * mm* waren. Wir haben jedoch alle anderen Werte mit zweistelliger Genauigkeit beibehalten - eine nicht gegebene Genauigkeit. Folglich müssen auch alle Dezimalstellen in den Messungen eliminiert werden. Um dies zu erreichen, müssen wir alle Messwerte mit Pythons integrierter Rundfunktion (
round(number, n-digits)) an Nulldezimalstellen (d.h.n-digits = 0) abrunden. In diesem Beispiel wird eine AusnahmeIOErrorangehoben, wenn die Datei"data/modified-data.csv"nicht existiert (oder wenn sie von einer anderen Software gesperrt wird). Eineif-Anweisung stellt sicher, dass eine Rundung der Daten nur versucht wird, wenn die Datei existiert. Das Überschreibensverfahren liest zunächst alle Zeilen der Datei in die Variablelines. Nach dem Lesen aller Zeilen ist der Zeiger am Ende der Datei, undfile.seek(0)setzt den Zeiger wieder auf Position 0 (d.h. am Anfang der Datei).file.truncate()reinigt die Datei. So ist die Originaldatei für einen Moment leer und alle Dateiinhalte werden in der Variablelinesgespeichert. Die Abrundung der Daten erfolgt innerhalb eines for-loop, das:Teilt die komma-separierte Linie string (produziert
lines_as_list).Erstellt die temporäre Liste
_numeric_line_, wo abgerundete numerische Werte gespeichert werden (die Variable ist in jeder Iteration überschrieben).Loops über die Zeileneinträge (
line_as_list), bei denen eine Ausnahmeerklärung gerundet (auf Nullstellen), numerische Werte und bei Nicht-Numerisierung eines Eintrags"nan"angibt.Schreibt die geänderte Zeile an die Datei
"data/modified-data.csv"csv.
Schließlich wird der csv mit modified_file.close() geschlossen.
try:
modified_file = open("data/modified-data.csv", mode="r+") # re-open the above data file in read-write
except IOError:
print("The file does not exist.")
if modified_file:
# go here only if the file exists
lines = modified_file.readlines() # read lines > pointer moves to file end
modified_file.seek(0) # return pointer to file beginning
modified_file.truncate() # clear file content
for line in lines:
line_as_list = line.split(", ") # converts the line into a list using comma separator
_numeric_line_ = []
for e in line_as_list:
try:
_numeric_line_.append(round(float(e), 0)) # try to convert line entry to float and round to 0 digits
except ValueError:
_numeric_line_.append(e) # for nan values
# write rounded values
modified_file.write(", ".join([str(e) for e in _numeric_line_]) + "\n")
print("Processed file." )
modified_file.close()
Processed file.
Theoretisch kann der obige Code-Snippet als Funktion neu geschrieben werden, um alle Daten in einer Datei zu ändern. Darüber hinaus können andere Schwellenwerte oder bestimmte Datenbereiche mit if - else-Anweisungen gefiltert werden.
- Beispiel 2 - Daten an eine bestehende Datei mit
"a+" - Durch Zufall finden Sie ein handschriftliches Messprotokoll, das Daten eines 18. Versuchslaufs aufweist, der aufgrund eines Datenübertragungsfehlers nicht in der elektronischen Messdatendatei liegt. Jetzt möchten Sie die Daten in die oben erzeugte csv-Datei einfügen. Die Eingabe der Daten erfordert nicht viel Arbeit, da nur 4 Messungen pro Versuchslauf durchgeführt wurden und der untere Codeblock die handschriftlichen Daten in einer Listenvariable
forgotten_dataenthält. Dieses Beispiel verwendet das Modulos(recall Pakete, Module und Bibliotheken) um zu überprüfen, ob die Datendatei mitos.path.isfile()existiert (dieos.getcwd()-Anweisung ist hier ein Gadget). Der Codeblock enthält die Nutzung einerwith-Anweisung (d.h. eineswith- Kontextmanagers oder Namensraums).
Der wesentliche Teil des Codes, der die Zeile an die Datendatei schreibt, ist file.write(line), wobei line den oben vorgestellten ", ".join(list-of-strings) + "\n" string entspricht.
import os
print(os.getcwd())
forgotten_data = [4.0, 3.0, "nan", 8.0]
if os.path.isfile("data/modified-data.csv"):
with open("data/modified-data.csv", mode="a") as file_object:
file_object.write(", ".join([str(e) for e in forgotten_data]) + "\n")
print("Data appended.")
else:
print("The file does not exist.")/home/schwindt/github/hyhome-v2/jupyter
Data appended.
NumP¶
NumPy bietet hochrangige mathematische Funktionen für lineare Algebra einschließlich Operationen auf mehrdimensionalen Arrays und Matrizen. Die Open-Source NumPy (für Numerical Python)-Bibliothek wird in Python und C geschrieben und enthält umfassende Dokumentationen (Download der neuesten Version auf der Website des Entwicklers oder lesen Sie das Online-Tutorial].
Watch the NumPy section in video format
Watch this section as a video on the @hydroinformatics channel on YouTube.
Installation¶
NumPy kann über Anaconda (recall instructions) installiert werden und die Entwickler empfehlen eine wissenschaftliche Python Distribution (Anaconda) mit SciPy Stack.
Anaconda environment.yml (flussenv) umfasst bereits NumPy (weitere Informationen im Abschnitt installation). Ebenso werden Linux-Benutzer NumPy in einer virtuellen Umgebung (z.B. vflussenv) mit pip (Recallpip-installing flusstools) installiert. Ansonsten, um NumPy in jeder anderen conda Umgebung zu installieren, Anaconda Prompt (Start* Typ Anaconda Prompt) und Typ:
conda activate ENVIRONMENT-NAME
conda install numpyUm pip-install NumPy in jeder anderen virtuellen Umgebung tippen Sie auf:
pip install numpyVerwendung¶
Die NumPy Bibliothek wird in der Regel mit import numpy as np importiert. Array Handling ist die Grundlage von NumPy und linearen Algebra, wo Arrays eine Art von geschachtelten Datenlisten darstellen. Um ein NumPy-Array zu erstellen, verwenden Sie np.array((values)), wobei values eine Wertefolge ist.
Der folgende Codeblock zeigt eine sehr grundlegende Verwendung von NumPy (oder: numpy) importiert als np und die Erstellung eines 2x3 numpy Arrays. Die abgerundeten Klammern weisen darauf hin, dass die Wertefolge der np.array ein Tupel zur Erstellung eines mehrdimensionalen Arrays darstellt.
import numpy as np
an_array = np.array(([2, 3, 1], [4, 5, 6]))
print(an_array)[[2 3 1]
[4 5 6]]
NumPy-Arrays (Datentyp: ndarray) haben viele eingebaute Funktionen, zum Beispiel um die Array-Größe auszugeben:
print(type(an_array))
print("Array dimensions: " + str(an_array.shape))
print("Total number of array elements: " + str(an_array.size))
print("Number of array axes: " + str(an_array.ndim))<class 'numpy.ndarray'>
Array dimensions: (2, 3)
Total number of array elements: 6
Number of array axes: 2
Es gibt viele Arten von np.arrays und viele Möglichkeiten, sie zu erstellen:
print(np.array([(2, 3, 1), (4, 5, 6)])) # the same as an_array
print(np.array([[2, 3, 1], [4, 5, 6]], dtype=complex))[[2 3 1]
[4 5 6]]
[[2.+0.j 3.+0.j 1.+0.j]
[4.+0.j 5.+0.j 6.+0.j]]
Arrays von Nullen oder einer oder leeren Arrays können mit integer oder float Datentypen erstellt werden. Wenn Sie solche Arrays erstellen, beachten Sie die Verwendung von Tupeln (d.h. Sequenzen, die mit abgerundeten Klammern umhüllt sind), um Array-Dimensionen zu definieren:
print(np.zeros((2,6)))
print(np.ones((2,6), dtype=np.float64)) # other dtypes: int16, np.int16, float, np.float32, np.complex64
print(np.empty((2,6)))
print(np.empty((2,6), dtype=np.int16))[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
[[1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1.]]
[[1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1.]]
[[19880 11437 6 0 0 0]
[ 0 0 0 0 0 0]]
NumPy bietet die arange(start, end, step-size)-Funktion, um numerische Sequenzen zu erstellen. Solche Sequenzen stellen Arrays (ndarray) dar, die später umgeformt werden können (d.h. in Spalten und Zeilen neu organisiert werden).
print("1D array:")
print(np.arange(0, 10, 2)) # 1D array
print("\n2D array:")
print(np.arange(0, 12, 2).reshape(2, 3)) # 2D array
print("\n3D array:")
print(np.arange(1, 13, 1).reshape(2, 2, 3)) # 3D array
print("\n1D Linspace (start, end, number-of-elements):")
print(np.linspace(0, np.pi, 3))1D array:
[0 2 4 6 8]
2D array:
[[ 0 2 4]
[ 6 8 10]]
3D array:
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
1D Linspace (start, end, number-of-elements):
[0. 1.57079633 3.14159265]
Zufällige Zahlen können mit NumPys Zufallsgenerator np.random und dessen .random(range_tuple)-Funktion generiert werden.
rand_array = np.random.random((2,4))
print(rand_array)[[0.78599116 0.11777177 0.29913723 0.9290063 ]
[0.70878365 0.5521523 0.81552564 0.17867719]]
Integrierte Array-Funktionen ermöglichen das Auffinden von Mindest- oder Maximalwerten oder Summen von Arrays:
print("Sum of 12-elements ones-array: " + str(np.ones((2,6)).sum()))
print("Minimum: " + str(an_array.min()))
print("Maximum: " + str(an_array.max()))Sum of 12-elements ones-array: 12.0
Minimum: 1
Maximum: 6
Farbe Arrays¶
Arrays können auch Farbinformationen enthalten, wobei Farben eine Mischung der drei Grundfarben rot, grün und blau darstellen (*RGB). So kann eine Farbe als [red-value, green-value, blue-value] definiert werden, und ein Wert von 0 bedeutet, dass ein Farbton nicht vorhanden ist, während 255 sein maximum-Wert ist. Es gibt keine Farbe, wenn alle Farbtonwerte Null sind, was schwarz entspricht; wenn alle Farbtöne maximal sind (255), entspricht der Farbmix weiß. Auf diese Weise können Array-Elemente Listen von Farbtönen sein, und das Ploten solcher Arrays erzeugt Bilder. Das folgende Beispiel erzeugt ein Array mit 5 Farblistenelementen, die als sehr grundlegendes Bild mit 5 Pixeln (ein schwarz, rot, grün, blau und weiß) aufgetragen werden können:
color_set = np.array([[0, 0, 0], # black
[255, 0, 0], # red
[0, 255, 0], # green
[0, 0, 255], # blue
[255, 255, 255]]) # whiteArray (Matrix) Operationen¶
Array-Berechnungen (Matrix-Operationen) folgen den Regeln der linearen Algebra:
A = np.random.random((2,4))
B = np.random.random((4,2))
print("Subtraction: " + str(A.transpose() - B))
print("Element-wise product: " + str(A.transpose() * B))
print("Matrix product (option 1): " + str(A @ B))
print("Matrix product (option 2): " + str(A.dot(B)))Subtraction: [[ 0.39513798 0.92256882]
[ 0.34627686 -0.64066838]
[-0.41525172 0.49672182]
[-0.64648598 0.21224637]]
Element-wise product: [[0.02631898 0.05370238]
[0.2312502 0.07207233]
[0.28977301 0.14078519]
[0.10386917 0.18425933]]
Matrix product (option 1): [[0.65121136 0.64929413]
[1.06516605 0.45081924]]
Matrix product (option 2): [[0.65121136 0.64929413]
[1.06516605 0.45081924]]
Weitere elementare Berechnungen umfassen exponentielle (**), geometrische (np.sin, np.cos, np.tan, etc.) und boolesche Operatoren:
print("A to the power of 3: " + str(A**3))
print("Exponential: " + str(np.exp(A)))
print("Square root: " + str(np.sqrt(A)))
print("Sine of A times 3: " + str(np.sin(A) * 3))
print("Boolean where A is smaller than 0.3: " + str(A < 0.3))A to the power of 3: [[9.30892075e-02 3.20353634e-01 5.03795493e-02 2.36414082e-03]
[9.34027227e-01 9.30307166e-04 3.40544706e-01 1.64838161e-01]]
Exponential: [[1.57335504 1.9822692 1.44676927 1.14249724]
[2.65782184 1.10254456 2.01038396 1.73031119]]
Square root: [[0.67320896 0.82718937 0.60772772 0.36498826]
[0.9886895 0.31244319 0.83565886 0.74047368]]
Sine of A times 3: [[1.313562 1.89625803 1.08298042 0.39846826]
[2.48731829 0.29239731 1.9288087 1.56371481]]
Boolean where A is smaller than 0.3: [[False False False True]
[False True False False]]
Array Shape Manipulation¶
Manchmal ist es notwendig, ein mehrdimensionales Array in einen Vektor zu stapeln oder die Form eines Arrays neu zu gestalten. Über die reshape()-Funktion hinaus gibt es ein paar andere Optionen, um die Form eines Arrays zu manipulieren:
print("Flattened matrix A (into a vector):\n" + str(A.ravel()))
print("\nTranspose matrix A and append B:\n" + str(np.array([A.transpose(), B])))
print("\nTranspose matrix A and append B and cast into a (4x4) array:\n" + str(np.array([A.transpose(), B]).reshape(4,4)))Flattened matrix A (into a vector):
[0.45321031 0.68424225 0.36933298 0.13321643 0.97750693 0.09762075
0.69832573 0.54830127]
Transpose matrix A and append B:
[[[0.45321031 0.97750693]
[0.68424225 0.09762075]
[0.36933298 0.69832573]
[0.13321643 0.54830127]]
[[0.05807233 0.05493811]
[0.33796539 0.73828912]
[0.78458471 0.20160391]
[0.77970241 0.33605491]]]
Transpose matrix A and append B and cast into a (4x4) array:
[[0.45321031 0.97750693 0.68424225 0.09762075]
[0.36933298 0.69832573 0.13321643 0.54830127]
[0.05807233 0.05493811 0.33796539 0.73828912]
[0.78458471 0.20160391 0.77970241 0.33605491]]
NumPy Datei Handling und np.nan¶
In den obigen Beispielen zum Dateihandling wurden Messdaten aus Textdateien geladen, manipuliert (modifiziert) und (re-)geschrieben. Bei der Datenmanipulation handelte es sich um die Einführung von "nan" (not-a-number)-Werten, die nicht berücksichtigt wurden, weil die Messungen <1 mm als Fehler angesehen wurden. Warum haben wir hier keine Nullen benutzt? Nullen sind auch Zahlen und haben einen erheblichen Einfluss auf die Datenstatistik (z.B. zur Berechnung von Mittelwerten). Der "nan" string-Wert kann jedoch Schwierigkeiten bei der Datenverarbeitung verursachen, insbesondere hinsichtlich der Konsistenz der Funktionsausgabe. NumPy bietet dem Datentyp np.nan eine leistungsstarke Alternative zum mühsamen "nan" string.
NumPy hat auch eine Textdatei-Lastfunktion namens np.loadtxt(file-name, *args, **kwargs), die Textdateien als np.arrays von float-Werten importiert. Der Standardwert float kann mit dem optionalen Schlüsselwort dtype angepasst werden. Weitere optionale Stichwortargumente sind:
delimiter=STR(z.B.delimiter=';'), wobei die Standardeinstellung"None"usecols=TUPLE(z.B.usecols=(1, 3)extrahiert den 2and und 4thSpalte), wobei auch ein integer-Wert nur auf einer einzigen Spalte gelesen werden kann.skiprows=INT(z.B.skiprows=2überspringt die ersten beiden Zeilen), wobei die Standardeinstellung0Weitere Argumente sind verfügbar und in der NumPy-Dokumentation.
Das folgende Beispiel lädt die oben erstellte csv-Datei data/modified-data.csv mit integer und "nan"string*-Werten, die automatisch auf np.nan umgerechnet werden.
experiment_data = np.loadtxt("data/modified-data.csv", delimiter=",")
print("This is the data 4th line (row): " + str(experiment_data[3, :]))
print("The data type of the 3rd (%s) entry is: " % str(experiment_data[3, 2]) + str(type(experiment_data[3, 2])))This is the data 4th line (row): [ 1. 4. nan 3.]
The data type of the 3rd (nan) entry is: <class 'numpy.float64'>
Die Funktion np.load() holt zusätzlich oder alternativ Daten aus datenähnlichen .npz, .npy oder kommissionierten (gespeicherten Python-Objekten) Datenquellen ab (mehr Informationen finden Sie in der NumPy docs).
Statistik¶
Die obigen Beispiele zeigten Array-Funktionen, um grundlegende Array-Statistiken wie das Minimum und Maximum zu bewerten. NumPy bietet viele weitere Funktionen für Array-Statistiken wie die mittlere, mediane oder Standardabweichung, einschließlich Funktionen, die np.nan-Werte berücksichtigen. Das folgende Beispiel veranschaulicht einige der statistischen Funktionen mit den Versuchsdaten aus den obigen Beispielen. Beachten Sie die Nutzung von nanmean anstelle von mean und Statistiken entlang der Array-Achse, wobei das optionale Keyword-Argument axis=0 den Spalten und axis=1 zu den Statistiken entlang der Zeilen in 2-dimensionalen Arrays entspricht (maximale Achsnummer entspricht den Array-Dimensionen n minus 1, d.h. maximal axis=n-1).
print("Mean value (without nan): " + str(np.mean(experiment_data))) # no applicable result
print("Mean value with np.nan: " + str(np.nanmean(experiment_data)))
print("Mean value along axis 0 (columns): " + str(np.nanmean(experiment_data, axis=0)))
print("Mean value along axis 1 (rows): " + str(np.nanmean(experiment_data, axis=1))) Mean value (without nan): nan
Mean value with np.nan: 3.018181818181818
Mean value along axis 0 (columns): [2.78571429 3.26666667 2.9 3.0625 ]
Mean value along axis 1 (rows): [2.66666667 1.5 2.5 2.66666667 2. 3.75
4. 2.33333333 3.5 3.66666667 3.75 3.
2.5 1.66666667 3.33333333 2.66666667 3. 5. ]
Die folgenden Absätze zeigen einen tabellarischen Überblick über statistische Funktionen in NumPy (Quelle: NumPy docs). Die gelisteten Funktionen stellen nur die Basislinie dar und NumPy bietet viele weitere Optionen, die mit einer beliebigen Suchmaschine mit NumPy und der gewünschten Funktion als Suchbegriff genutzt werden können.
Grundlegende Statistikfunktionen
| Function | Description |
|---|---|
nanmin(a[, axis, out, keepdims]) | Minimum of an array or along an axis, ignoring np.nan. |
nanmax(a[, axis, out, keepdims]) | Maximum of an array or along an axis, ignoring np.nan. |
ptp(a[, axis, out]) | Range of values (max - min) along an axis. |
percentile(a, q[, axis, out, ...]) | q-th percentile of data along a specified axis. |
nanpercentile(a, q[, axis, out, ...]) | q-th percentile of data along a specified axis, ignoring np.nan. |
Mittel (Mittel), Standardabweichung und Varianzen
| Function | Description |
|---|---|
median(a[, axis, out, overwrite_input, keepdims]) | Median along an (optional) axis. |
average(a[, axis, weights, returned]) | Weighted average along an (optional) axis. |
mean(a[, axis, dtype, out, keepdims]) | Arithmetic mean along an (optional) axis. |
std(a[, axis, dtype, out, ddof, keepdims]) | Standard deviation along an (optional) axis. |
var(a[, axis, dtype, out, ddof, keepdims]) | Variance along an (optional) axis. |
nanmedian(a[, axis, out, overwrite_input, ...]) | Median along an (optional) axis, ignoring np.nan. |
nanmean(a[, axis, dtype, out, keepdims]) | Arithmetic mean along an (optional) axis, ignoring np.nan. |
nanstd(a[, axis, dtype, out, ddof, keepdims]) | Standard deviation along an (optional) axis, while ignoring np.nan. |
Korrelierende Daten (Arrays)
| Function | Description |
|---|---|
corrcoef(x[, y, rowvar, bias, ddof]) | Pearson (product-moment) correlation coefficients. |
correlate(a, v[, mode]) | Cross-correlation of two 1-dimensional sequences. |
cov(m[, y, rowvar, bias, ddof, fweights, ...]) | Estimate covariance matrix, based on data and weights. |
Erzeugen und Plot Histogramme
| Function | Description |
|---|---|
histogram(a[, bins, range, normed, weights, ...]) | Histogram of a set of data. |
histogram2d(x, y[, bins, range, normed, weights]) | Bi-dimensional histogram of two data samples. |
histogramdd(sample[, bins, range, normed, ...]) | Multidimensional histogram of some data. |
bincount(x[, weights, minlength]) | Count number of occurrences of each value in array of non-negative ints. |
digitize(x, bins[, right]) | Indices of the bins to which each value in input array belongs. |
Kann NumPy MATLAB® tun?¶
Denken Sie daran, nach Python zu wechseln, nachdem Sie mit MATLAB®-ähnliche Software in die Programmierung gestartet haben? Es gibt viele Gründe für die Verbesserung der Datenanalysen mit Python und hier sind einige Moderatoren für frühere MATLAB® Anwender:
MATLAB® matrices can be loaded and saved with
scipy.io.loadmat(matrix-file-name)(useimport scipy).NumPy’s
np.arrayersetzt MATLAB®’s Matrix Notation (auch wenn es den historischen, deprecierten NumPy Datentypnp.matrixgibt).Viele MATLAB® importieren; Merkmale von
np.matlib(z.B.from numpy.matlib import rand, zeros, ones, empty, eye)oder allgemeinimport numpy.matlib as M).Finden Sie das NumPy Äquivalent vieler MATLAB® Funktion in der NumPy Dokumentation.
To emulate MATLAB®’s plot functions use the
pylabpackage and import it asfrom pylab import *.
⚠ This overwrites all other (standard) definitions of theplot()function andarray()objects. So this usage is deprecated. Read the plotting section for comprehensive plotting instructions with Python.
MATLAB® ist eine eingetragene Marke von The MathWorks.
Pandas¶
pandas ist eine leistungsstarke Bibliothek für Datenanalysen und Manipulationen mit Python. Es kann mit NumPy Arrays umgehen, und beide Pakete stellen gemeinsam eine leistungsstarke Datenverarbeitungsmaschine dar. Die Leistung von pandas liegt in der Verarbeitung von Datenrahmen, Datenmarkierung (z.B. arbeitsbuchähnliche Spaltennamen) und flexiblen Datei-Handling-Funktionen (z.B. die integrierte read_csv(csv-file)-Funktion). Während NumPy-Arrays Berechnungen mit mehrdimensionalen Arrays (über 2dimensionale Tabellen) und niedrigem Speicherverbrauch ermöglichen, pandas DataFrames effizient verarbeiten und markieren tabellarische Daten mit mehr als ~100.000 Zeilen. pandas findet aufgrund seiner Beschriftungskapazität auch eine breite Anwendung im maschinellen Lernen. Zusammengefasst baut pandas’ Funktionalität auf NumPy und beide Bibliotheken werden von der SciPy (Wissenschaftliche Rechenwerkzeuge für Python)-Community gepflegt, die auch matplotlib (siehe plotting section) und IPython (Jupyter’s Python kernel) produziert.
Watch the pandas section on YouTube
Watch this section as a video on the @hydroinformatics channel on YouTube.
Installation¶
pandas kann über Anaconda (recall instructions) installiert werden und die Entwickler empfehlen eine wissenschaftliche Python Distribution (Anaconda) mit SciPy Stack.
Anaconda environment.yml (flussenv) umfasst bereits pandas (weitere Informationen im Abschnitt installation). Ebenso werden Linux-Benutzer pandas in einer virtuellen Umgebung (z.B. vflussenv) mit pip (recallpip-installing flusstools) installiert. Ansonsten, um pandas in einer anderen conda Umgebung zu installieren, öffnen Anaconda Prompt (Start** Typ Anaconda Prompt) und geben Sie:
conda activate ENVIRONMENT-NAME
conda install pandasUm pip-install pandas in jeder anderen virtuellen Umgebung tippen Sie auf:
pip install pandasVerwendung¶
pandas Standard-Import-Alias ist pd: import pandas as pd. Die folgenden Abschnitte geben einen Überblick über grundlegende pandas-Funktionen und viele weitere Features sind in der developer’s docs.
Datenrahmen und Serie¶
Der untenstehende Codeblock zeigt eine Möglichkeit, einen pandas Datenrahmen (pd.DataFrame) zu erstellen, eines der pandas Kernobjekte. Beachten Sie den Unterschied zwischen einer 1-dimensionalen Serie pd.Series (entspricht einem einfarbigen Datenrahmen) und einem n-dimensionalen Datenrahmen mit row (= Index) und Spaltennamen. Die Standardzeilennamen Zahlenzeilen ab 0 (im Gegensatz zu Office-Software, die in Zeile Nr. 1) beginnt, ohne Spaltennamen. Stammnamen können zunächst als list definiert werden und durch eine dictionary ersetzt werden, die die ersten Listeneinträge an neue Namen abbildet.
import pandas as pd
print("A 1-column pd.DataFrame:\n"+ str(pd.Series([3, 4, np.nan]))) # a simple pandas data frame with one column
row_names = np.arange(1, 4, 1)
wb_like_df = pd.DataFrame(np.random.randn(len(row_names), 3),
index=row_names, columns=['A', 'B', 'C'])
print("\nThis is a workbook-like (row and column names) data frame:\n" + str(wb_like_df))
print("\nRename column names with dictionary:\n" + str(wb_like_df.rename(
columns={'A': 'Series 1', 'B': 'Series 2', 'C': 'Series 3'})))
print("\nTranspose the data frame:\n" + str(wb_like_df.T))A 1-column pd.DataFrame:
0 3.0
1 4.0
2 NaN
dtype: float64
This is a workbook-like (row and column names) data frame:
A B C
1 -0.374896 1.510560 0.164615
2 0.171686 -0.668994 -1.850155
3 -0.521211 1.688967 -0.653523
Rename column names with dictionary:
Series 1 Series 2 Series 3
1 -0.374896 1.510560 0.164615
2 0.171686 -0.668994 -1.850155
3 -0.521211 1.688967 -0.653523
Transpose the data frame:
1 2 3
A -0.374896 0.171686 -0.521211
B 1.510560 -0.668994 1.688967
C 0.164615 -1.850155 -0.653523
Ein pandas DataFrameObjekt kann auch von einem dictionary erstellt werden, wobei die Wörterbuchschlüssel Spaltennamen definieren und die Wörterbuchwerte die Daten jeder Spalte darstellen:
df = pd.DataFrame({'Flow depth': pd.Series(np.random.uniform(low=0.1, high=0.3, size=(4,)), dtype='float32'),
'Sediment': ["yes", "no", "yes", "no"],
'Flow regime': pd.Categorical(["fluvial", "fluvial", "supercritical", "critical"]),
'Water': "Always there"})
print("A dictionary-built data frame:\n" + str(df))
print("\nFrame data types:\n" + str(df.dtypes))A dictionary-built data frame:
Flow depth Sediment Flow regime Water
0 0.236444 yes fluvial Always there
1 0.212434 no fluvial Always there
2 0.121081 yes supercritical Always there
3 0.290556 no critical Always there
Frame data types:
Flow depth float32
Sediment str
Flow regime category
Water str
dtype: object
Eingebaute Attribute und Methoden eines pandas DataFrame ermöglichen einen einfachen Zugriff auf den oberen (Kopf) und den unteren Teil eines Datenrahmens und viele weitere Objekteigenschaften (Recall: Verwenden Sie dir(dict_df) oder lesen Sie die docs des Entwicklers):
print("Head of the dictionary-based dataframe (first two rows):\n" + str(df.head(2)))
print("\nEnd (tail) of the dictionary-based dataframe (last row):\n" + str(df.tail(1)))Head of the dictionary-based dataframe (first two rows):
Flow depth Sediment Flow regime Water
0 0.236444 yes fluvial Always there
1 0.212434 no fluvial Always there
End (tail) of the dictionary-based dataframe (last row):
Flow depth Sediment Flow regime Water
3 0.290556 no critical Always there
Beispiel: Erstellen Sie eine pandas.DataFrame von Froude Numbers¶
In hydraulics, the Froude number characterizes the flow regime as “fluvial” (Fr<1), “critical” (Fr=1), or “super-critical” (Fr>1). The precision of measurement devices in physical flume experiments makes the exact determination of the critical moment a challenge and forces researchers to apply an interval around 1, rather than the exact value of 1.0:
| ******* | (0.00, 0.95( | (0.95, 1.00(1.00 (1.00) | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | | | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00¶
| Flow | fluvial | Near-kritische (langsam) | kritisch | Near-kritische (fast) | superkritische |
pd.DataFrame( ... ) Objekte sind eine bequeme Möglichkeit, Flume-Experimentdaten einzuordnen und zu speichern:
Fr_dict = {0.925: "fluvial", 0.975: "near-critical (slow)", 1.0: "critical", 1.025: "near-critical (fast)", 1.075: "super-critical"}
Fr_measured = np.random.uniform(low=0.01, high=2.00, size=(10,))
Fr_classified = [Fr_dict[min(Fr_dict.keys(), key=lambda x:abs(x-m))] for m in Fr_measured]
obs_df = pd.DataFrame({"measured": Fr_measured, "flow regime": Fr_classified})
print(obs_df) measured flow regime
0 0.722820 fluvial
1 1.099443 super-critical
2 0.886570 fluvial
3 0.849089 fluvial
4 1.175042 super-critical
5 0.086024 fluvial
6 1.157518 super-critical
7 1.606757 super-critical
8 1.541139 super-critical
9 0.189163 fluvial
Daten an eine pandas.DataFrame¶
Die at, loc, concat und append-Methoden von pandas bieten direkte Optionen zum Einfügen von Zeilen oder Spalten in eine pd.DataFrame. Diese eingebauten Verfahren sind jedoch etwa eine Größenordnung langsamer als die Umleitung über ein Wörterbuch. Dies gilt insbesondere für Datenrahmen mit mehr als 10.000 Elementen. Das bedeutet, dass die schnellste Methode, Daten in eine pd.DataFrame einzufügen ist:
Konvertieren Sie ein bestehendes
pd.DataFrame-Objekt zu einem Dictionary mitpd.DataFrame.to_dict()(z.B.dict_of_df = df.to_dict()).Aktualisieren Sie das Dictionary mit den neuen Daten
Zeilen mit
dict_of_df.update({"existing-column-name": {"new-row-name": NEW_DATA}})anhängenSpalten mit
dict_of_df.update({"new-column-name": {"existing-row-name": NEW_DATA}})anhängen
Umwandeln Sie den Dictionary an eine
pd.DataFramemitdf = pd.DataFrame.from_dict(dict_of_df)
Der folgende Codeblock verdeutlicht sowohl das Hinzufügen einer Zeile als auch einer Spalte zu einem vorhandenen pandas Datenrahmen.
import random
# convert data frame to dictionary
dict_of_obs_df = obs_df.to_dict()
# append new row
new_row_index = max(dict_of_obs_df["measured"]) + 1
dict_of_obs_df["measured"].update({new_row_index: 0.996})
dict_of_obs_df["flow regime"].update({new_row_index: "near-critical (slow)"})
# append column
dict_of_obs_df.update({"with sediment": {}})
for k in dict_of_obs_df["measured"].keys():
dict_of_obs_df["with sediment"].update({k: bool(random.getrandbits(1))})
# re-build data frame
obs_df = pd.DataFrame.from_dict(dict_of_obs_df)
print(obs_df.tail(3)) measured flow regime with sediment
8 1.541139 super-critical True
9 0.189163 fluvial False
10 0.996000 near-critical (slow) False
NumPy Arrays und pandas Datenrahmen¶
Ein wesentlicher Unterschied zwischen einem NumPy array und einem pandasDataFrame besteht darin, dass NumPy-Arrays nur einen einzigen Datentyp (dtype) haben können, während ein pandas DataFrame verschiedene Datentypen haben kann (eine dtype pro Spalte). Aus diesem Grund kann ein NumPy array nahtlos in eine pandas DataFrame umgewandelt werden, aber die entgegengesetzte Umwandlung kann hohe Rechenkosten verursachen: pandas kommt mit einer eingebauten Funktion, um eine pandas DataFrame in eine NumPy array umzuwandeln, wo es möglich ist. Ist eine Spalte des pandas DataFrame nicht numerisch, so bedeutet die Umwandlung das Kopieren des Objekts, was dann hohe Rechenkosten verursacht. Beachten Sie, dass die index und column-Etiketten eines pandas DataFrame bei der Umwandlung von pd.DataFrame an np.ndarray verloren gehen.
print(obs_df.to_numpy())[[0.7228199423430681 'fluvial' True]
[1.0994432843154105 'super-critical' True]
[0.8865704358418128 'fluvial' False]
[0.8490886765821513 'fluvial' True]
[1.1750423214539258 'super-critical' True]
[0.086024140985809 'fluvial' True]
[1.1575177959070637 'super-critical' True]
[1.6067571441117197 'super-critical' False]
[1.5411388862372846 'super-critical' True]
[0.18916310404617928 'fluvial' False]
[0.996 'near-critical (slow)' False]]
Zugriff auf Datenrahmen Einträge¶
Elemente der Datenrahmen sind durch das Spalten- und Zeilenlabel (df.loc[index=row, column-label]) oder Nummer (df.iloc) zugänglich:
print("Label localization results in: " + str(df.loc[2, "Flow depth"]))
print("Same result with integer grid location: " + str(df.iloc[2, 0]))Label localization results in: 0.12108062
Same result with integer grid location: 0.12108062
Reshape Datenrahmen¶
Einzel- oder Mehrfachzeilen (Indizes) und Spalten können aus neuen oder bestehenden DataFrame Objekten extrahiert und kombiniert werden:
print(pd.DataFrame([df["Flow depth"], df["Sediment"]])) 0 1 2 3
Flow depth 0.236444 0.212434 0.121081 0.290556
Sediment yes no yes no
Die Methode df.stack() schwenkt die Spalten eines Datenrahmens an, das ein leistungsfähiges Werkzeug ist, um Daten zu klassifizieren, die unterschiedliche Dimensionen annehmen können (z.B. Volumen und Gewicht von 1 m3wasser - Lesen Sie mehr über die Stack-Methode).
print(df.stack()[0])
df.unstack() # unstack data frameFlow depth 0.236444
Sediment yes
Flow regime fluvial
Water Always there
dtype: object
Flow depth 0 0.236444
1 0.212434
2 0.121081
3 0.290556
Sediment 0 yes
1 no
2 yes
3 no
Flow regime 0 fluvial
1 fluvial
2 supercritical
3 critical
Water 0 Always there
1 Always there
2 Always there
3 Always there
dtype: objectBig Datasets enthalten oft große Datenmengen mit vielen Labels, aber wir sind oft nur an einer kleinen Teilmenge der Daten interessiert. Zu diesem Zweck können Datenrahmen-Subsets mit df.pivot(index, columns, **values) erstellt werden (Pivot method):
print("Pivot table for \'Flow regime\':\n" + str(df.pivot(index="Sediment", columns="Flow depth")["Flow regime"]))
print("\nPivot table for \'Water\':\n" + str(df.pivot(index="Sediment", columns="Flow depth")["Water"]))Pivot table for 'Flow regime':
Flow depth 0.121081 0.212434 0.236444 0.290556
Sediment
no NaN fluvial NaN critical
yes supercritical NaN fluvial NaN
Pivot table for 'Water':
Flow depth 0.121081 0.212434 0.236444 0.290556
Sediment
no NaN Always there NaN Always there
yes Always there NaN Always there NaN
Darüber hinaus ermöglicht df.pivot_table(index, columns, values, aggfunc) (Pivot
print("\'mean\' for \'Flow depth\':\n" + str(df.pivot_table(index="Sediment", columns="Flow regime", values="Flow depth", aggfunc=np.mean)))'mean' for 'Flow depth':
Flow regime critical fluvial supercritical
Sediment
no 0.290556 0.212434 NaN
yes NaN 0.236444 0.121081
Lesen Sie mehr über das Umformen und Verschwenken von Datenrahmen in der developer’s docs.
File Handling (csv, Workbooks und mehr)¶
pandas kann von und zu vielen Datendateitypen lesen und schreiben, was es extrem leistungsstark macht, um Daten zu analysieren. Die folgende Tabelle fasst die wichtigsten Dateitypen für numerische hydraulische, morphodynamische und fluviale Landschaftsanalysen zusammen, und mehr Dateityp-Handler finden Sie unter der developer’s docs.
| File type | pandas read | pandas write | Usage example |
|---|---|---|---|
| CSV | read_csv | to_csv | Reading from data loggers (e.g., discharge, flow depth) |
| Google BigQuery | read_gbq | to_gbq | Analyze social media |
| JSON | read_json | to_json | Manipulate ABSCHNITT model files |
| HTML | read_html | to_html | Process web site data |
| HDF5 Format | read_hdf | to_hdf | Analyze ABSCHNITT or HEC-RAS output files |
| Python Pickle Format | read_pickle | to_pickle | Cache memory dump |
| SQL | read_sql | to_sql | Retrieve and write data to SQL data bases |
| Workbooks (Excel / Open doc) | read_excel | to_excel | Interface with non-programmers (Open only works in read mode) |
Der folgende Codeblock zeigt, wie die oben erzeugte data/modified-data.csv-Datei geladen und in ein Arbeitsbuch mit pandas gespeichert werden kann. pandas verwendet standardmäßig openpyxl4@@@, aber diese Nutzung variiert je nach Dateityp des Arbeitsbuchs (z.B..ods, .xls und xlsb) auf anderen Paketen - weitere Informationen zu den enginekeyword].
measurement_data = pd.read_csv("data/modified-data.csv", sep=",", header=None, names=["Test 1", "Test 2", "Test 3", "Test 4"])
print("Header of data/modified-data.csv:\n" + str(measurement_data.head(3)))
measurement_data.to_excel("data/modified-data-wb.xlsx", sheet_name="2025-01-01 Tests")Header of data/modified-data.csv:
Test 1 Test 2 Test 3 Test 4
0 2.0 4.0 nan 2.0
1 NaN nan 1.0 2.0
2 2.0 3.0 2.0 3.0
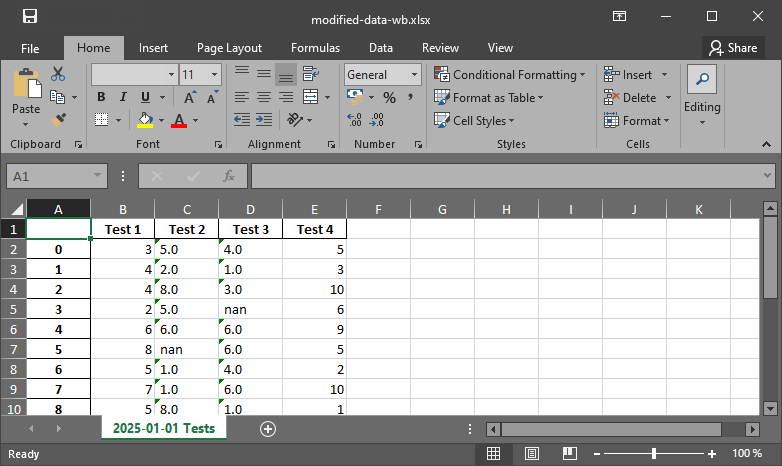
Figure 1:Die xlsx Ausgabedatei mit pandas.
Ein pandas ExcelWriter Objekt kann erstellt werden, um mehrere pd.DataFrameObjekte an ein Arbeitsbuch zu schreiben, auf einem oder mehreren Blättern. Hier ist ein Beispiel, bei dem die nicht-numerischen "nan" Strings in measurement_data mit np.nan ersetzt werden, um einen rein numerischen Datenrahmen in zwei Schritten zu erhalten (# (1) und # (2)):
measurement_data = measurement_data.replace("nan", np.nan, regex=True) # (1) replace "nan" with np.nan
measurement_data = measurement_data.apply(pd.to_numeric) # (2) convert all data to numeric
# write workbook with pd ExcelWriter object
with pd.ExcelWriter("data/modified-data-wb-EW.xlsx") as writer:
measurement_data.to_excel(writer, sheet_name="2025-01-01 Tests")
df.to_excel(writer, sheet_name="pandas example")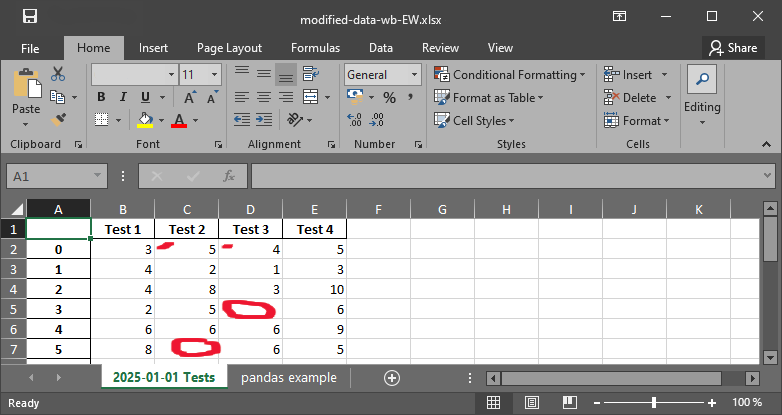
Figure 2:Die xlsx-Datei mit nan strings.
Kategorisierte Daten¶
String Variablen, die statistisch relevante Kategorien darstellen, sind die Basis für die Datenklassifizierung und -statistik. pandas bietet den speziellen Datentyp von dtype="category", um statistische Analysen zu erleichtern.
In der obigen Froude-number example haben wir fünf Kategorien verwendet, um das Ablaufregime in Abhängigkeit von der Froude-Nummer zu klassifizieren, die als Kategorien dienen kann. Dies ist z.B. nützlich, wenn kein Wasser fließt oder wenn ein Sensor in einem Experiment brach und wir unsere Messungen kategorisieren möchten, um gültige Tests nur zu filtern:
flow_regimes = ["fluvial", "near-critical (slow)", "critical", "near-critical (fast)", "super-critical"]
observation_examples = ["fluvial", "dry", "critical", "near-critical (slow)", "measurement error"]
Fr_cat = pd.Categorical(observation_examples, categories=flow_regimes, ordered=False)
print(pd.Series(Fr_cat))0 fluvial
1 NaN
2 critical
3 near-critical (slow)
4 NaN
dtype: category
Categories (5, str): ['fluvial', 'near-critical (slow)', 'critical', 'near-critical (fast)', 'super-critical']
/tmp/ipykernel_16649/2029032689.py:3: Pandas4Warning: Constructing a Categorical with a dtype and values containing non-null entries not in that dtype's categories is deprecated and will raise in a future version.
Fr_cat = pd.Categorical(observation_examples, categories=flow_regimes, ordered=False)
Datenrahmenstatistik¶
pandas has efficient routines to perform workbook-like row or column sorting (e.g., df.sort_index() or df.sort_values()), and enables the fast calculation of data frame statistics with df.describe(), where 25%, 50%, and 75% represent the i-th percentiles:
measurement_data.describe()Statistische pandas Datenrahmenmethoden überschneiden sich mit NumPy Methoden und umfassen:
df.abs()berechnet absolute Wertedf.cumprod()berechnet das kumulative Produktdf.cumsum()berechnet die kumulative Summedf.count()zählt die Anzahl der Nicht-Null-Beobachtungendf.max()berechnet den Maximalwertdf.mean()berechnet den Mittelwertdf.min()berechnet den Mindestwertdf.mode()berechnet den Modusdf.prod()berechnet das Produktdf.std()berechnet die Standardabweichungdf.sum()berechnet die Summe
print("Mean:\n" + str(measurement_data.mean()))
print("Median:\n" + str(measurement_data.median()))
print("Standard deviation:\n" + str(measurement_data.std()))Mean:
Test 1 2.785714
Test 2 3.266667
Test 3 2.900000
Test 4 3.062500
dtype: float64
Median:
Test 1 2.5
Test 2 3.0
Test 3 3.0
Test 4 3.0
dtype: float64
Standard deviation:
Test 1 1.423893
Test 2 1.032796
Test 3 1.197219
Test 4 1.611159
dtype: float64
Benutzerdefinierte (Own) Funktionen auf Datenrahmen anwenden¶
pandas Datenrahmen haben eine integrierte apply(fun)Methode, die es ermöglicht, eine benutzerdefinierte Funktion an ein pd.DataFrame Objekt zu übertragen. Folgende Code-Block-Anleihen aus der feet_to_meter-Funktion aus dem functions-Kapitel (Download
from fun.converter import feet_to_meter
# create data frame with random integers
df = pd.DataFrame({"Feet": np.random.randint(0, 100, size=6),
"Meters": np.ones(6) * np.nan})
# apply feet_to_meter to the Meters columns of the data frame
df["Meters"] = df["Feet"].apply(feet_to_meter)
print(df) Feet Meters
0 18 5.4864
1 62 18.8976
2 53 16.1544
3 95 28.9560
4 61 18.5928
5 59 17.9832
Termine und Uhrzeit¶
pandas involves methods for calculations and labeling with date and time values through pd.Timestamp, which converts date-time-like strings into timestamps or creates timestamps from keyword arguments:
print(pd.Timestamp('2025-01-01T12'))
print(pd.Timestamp(year=2025, month=1, day=1, hour=12))
print(pd.Timestamp(2025, 1, 1, 12))2025-01-01 12:00:00
2025-01-01 12:00:00
2025-01-01 12:00:00
Der Ausdruck pd.Timestamp(2025, 1, 1, 12) mimiert die leistungsfähige datetime.datetime API (Application Programming Interface) der datetime Python-Bibliothek, die anspruchsvolle Methoden zum Umgang mit zeitabhängigen Werten bietet. Während die eingebauten Zeitstempel von pandas für die Erstellung von Zeitreihen innerhalb von pd.DataFrameObjekten und arbeitsbuchähnlichen Tabellen günstig sind, ist datetime eine der besten Lösungen für zeitabhängige Berechnungen in Python. datetime ist standardmäßig verfügbar (d.h. es darf nicht conda oder pip-installiert sein) und ist z.B. effizient auf Daten anwendbar, die über mehrere Jahre einschließlich der Sprungjahre gesammelt wurden. Das datetime Paket kommt mit vielen Attributen und Methoden, die im Detail in der Python docs.
Die Standardnutzung ist:
import datetime as dt
start_date = dt.datetime(2024, 2, 25, 22, 30, 0)
end_date = dt.datetime(year=2024, month=3, day=2, hour=2, minute=15, second=30)
print("Datetime variables can be subtracted:\n" + str(end_date - start_date))
print("The result is a %s object." % type(end_date - start_date))Datetime variables can be subtracted:
5 days, 3:45:30
The result is a <class 'datetime.timedelta'> object.
dt.timedelta Objekte können auch separat definiert werden:
time_diff = dt.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=23, weeks=0)
act_time = start_date
print("Iterate from start to end date with stepsize=time_diff:")
while act_time <= end_date:
print(act_time.strftime("%Y-%m(%h)-%d, %H:%M:%S"))
act_time += time_diffIterate from start to end date with stepsize=time_diff:
2024-02(Feb)-25, 22:30:00
2024-02(Feb)-26, 21:30:00
2024-02(Feb)-27, 20:30:00
2024-02(Feb)-28, 19:30:00
2024-02(Feb)-29, 18:30:00
2024-03(Mar)-01, 17:30:00
Das ist alles für die Einführung in die Daten- und Dateiverwaltung. Obwohl es viel mehr zur Datenverarbeitung als in diesem Kapitel gezeigt, und die nächsten anderen Kapitel dieses eBooks werden gelegentlich mehr Werkzeuge.
