Bereiten Sie sich durch Klonen des Übungs-Repository:
git clone https://github.com/Ecohydraulics/Exercise-SequentPeak.git
Figure 1:New Bullards Bar Dam in Kalifornien, USA (Quelle: Sebastian Schwindt 2017).
Theorie¶
Die saisonalen Lagerstätten halten Wasser während der nassen Monate (z.B. Monsun oder Regenwinters im mediterranen Klima) fest, um in trockenen Monaten ausreichend Trinkwasser und landwirtschaftliche Versorgung zu gewährleisten. Dazu sind enorme Speichervolumen erforderlich, die oft 1.000.000 m.
Das notwendige Speichervolumen wird aus historischen Zuflussmessungen und Zielentladungsvolumen (z.B. Landwirtschaft, Trinkwasser, Wasserkraft oder ökologische Restwassermengen) bestimmt. Der sequent Peak-Algorithmus Potter, 1977 basierend auf Rippl (1883) ist ein jahrzehntelanges Verfahren zur Bestimmung des notwendigen saisonalen Speichervolumens basierend auf einer Speichervolumenkurve (SD-Kurve****). Die folgende Abbildung zeigt eine beispielhafte -Kurve mit Volumenspitzen (lokale Maxima) etwa alle 6 Monate und lokale Volumenminima zwischen den Spitzen. Das Volumen zwischen dem letzten lokalen Maximum und dem niedrigsten nach dem lokalen Minimum bestimmt das erforderliche Speichervolumen (siehe die hellblaue Linie in der Figur).
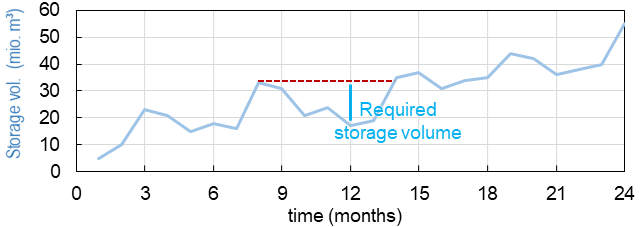
Figure 2:Schema des sequent Peak-Algorithmus.
Der sequent Peak-Algorithmus wiederholt diese Berechnung über mehrere Jahre und das höchste beobachtete Volumen bestimmt das erforderliche Volumen.
In dieser Übung verwenden wir tägliche Durchflussmessungen von Vanilla River (in Vanille-arid Land mit Monsun-Perioden) und Ziel-Abflussmengen, um Landwirte und die Bevölkerung von Vanille-arid Land mit ausreichend Wasser in den Trockenzeiten zu versorgen. Diese Übung führt Sie durch das Laden der täglichen Entladungsdaten, die Erstellung der monatlichen (Speicher) Kurve und die Berechnung des erforderlichen Speichervolumens.
Vorverarbeitung von Durchflussdaten¶
Die Tagesflussdaten des Flusses Vanilla sind von 1979 bis 2001 in Form von .csv-Dateien erhältlich (flowsfold).
Schreiben Sie eine Funktion zum Lesen von Flussdaten¶
Die Funktion wird über die csv-Dateinamen schleifen und die Dateiinhalte an ein Wörterbuch von numpy-Arrays anhängen. Achten Sie auf import numpy as np, import os und import glob.
Wählen Sie einen Funktionsnamen (z.B.
def read_data(args):) und verwenden Sie die folgenden Eingabeargumente:directory: String eines Pfades zu Dateienfn_prefix: String der Datei prefix, um Dikt-Tasten aus einem Dateinamen zu entfernenfn_suffix: string von Datei-Suffix, um Dikt-Tasten von einem Dateinamen abzustreifenftype: string von Dateiendungendelimiter: String des Spaltenabscheiders
In the function, test if the provided directory ends on
"/"or"\\"with
directory.endswith("/") or directory.endswith("\\")
and read all files that end withftype(we will useftype="csv"here) with thegloblibrary:if True:get the the csv (ftype) file list as
file_list = glob.glob(directory + "*." + ftype.strip(".").if False:get the the csv (ftype) file list as
file_list = glob.glob(directory + "/*." + ftype.strip(".")(the difference is only one powerful"/"sign).
Erstellen Sie das Leerwörterbuch, das die Dateiinhalte als numpy-Arrays enthält:
file_content_dict = {}Über alle Dateien in der Dateiliste mit
for file in file_list:Erstellen Sie einen Schlüssel für
file_content_dict:Ermitteln Sie den Dateinamen von der
file(Regie + Dateiname + Datei endenftype) mitraw_file_name = file.split("/")[-1].split("\\")[-1].split(".csv")[0]Stripieren Sie den benutzerdefinierten
fn_prefixundfn_suffixstrings aus dem Rohdateinamen und verwenden Sie einetry:-Anweisung, um die restlichen Zeichen in einen numerischen Wert umzuwandeln:int(raw_file_name.strip(fn_prefix).strip(fn_suffix)*Anmerkung: Wir verwenden später unter
fn_prefix="daily_flows_undfn_suffix="", um das in den csv-Dateinamen enthaltene Jahr an den Schlüssel infile_content_dictzu wenden.Use
except ValueError:in the case that the remaining string cannot be converted toint:dict_key = raw_file_name.strip(fn_prefix).strip(fn_suffix)(if everything is well coded, the script will not need to jump into this exception statement later).
Öffnen Sie das
file(Vollverzeichnis) als Datei:with open(file, mode="r") as f:Lesen Sie den Dateiinhalt mit
f_content = f.read(). Die string Variablef_contentwird ähnlich aussehen wie";0;0;0;0;0;0;0;0;0;2.1;0;0\n;0...".
Um die Anzahl der (gültigen) Zeilen in jeder Datei zu erhalten
rows = f_content.strip("\n").split("\n").__len__()Um die Anzahl der (gültigen) Spalten in jeder Datei zu erhalten
cols = f_content.strip("\n").split("\n")[0].strip(delimiter).split(delimiter).__len__()Jetzt können wir ein leeres numpy-Array der Größe (Form) erstellen, das der Anzahl der gültigen Zeilen und Spalten in jeder Datei entspricht:
data_array = np.empty((rows, cols), dtype=np.float32)Warum verwenden wir nicht direkt
np.empty((31, 12), obwohl die Form aller Dateien gleich ist?
Wir möchten eine allgemein gültige Funktion schreiben und die beiden Zeilen zur Ableitung der gültigen Anzahl von Zeilen und Spalten machen den Verallgemeinerungsauftrag.Next, we need to parse the values of every line and append them to the until now void
data_array. Therefore, we splitf_contentinto its lines withsplit("\n)and use a for loop:for iteration, line in enumerate(f_content.strip("\n").split("\n"):.
Create an empty list to store line dataline_data = [].
In another for loop, strip and split the line by the user-defineddelimiter(recall: we will usedelimiter=";")for e in line.strip(delimiter).split(delimiter):. In the e-for loop,try:to appendeas a float numberline_data.append(np.float32(e)and useexcept ValueError:toline_data.append(np.nan)(i.e., append a not-a-number value that we will need because not all months have 31 days).
End the e-for loop by back-indenting to thefor iteration, line in ...loop and appending theline_datalist as a numpy array todata_array:data_array[iteration] = np.array(line_data)Zurück in der
with open(file, ...-Anweisung (verwenden Sie die korrekte Einrückungsstufe!), aktualisieren Siefile_content_dictmit der oben genanntendict_keyund derdata_arrayderfile as f:file_content_dict.update({dict_key: data_array})Zurück auf der Ebene der Funktion (
def read_data(...):- achten Sie auf die richtige Einbuchtung!),return file_content_dict
Überprüfen Sie, ob die Funktion wie gewünscht funktioniert und folgen Sie der Anleitung im Abschnitt Machen Sie Skript Stand-alone, um eine if __name__ == "__main__":-Anweisung am Ende der Datei zu implementieren. So sollte das Skript ähnlich aussehen wie der folgende Codeblock:
import glob
import os
import numpy as np
def read_data(directory="", fn_prefix="", fn_suffix="", ftype="csv", delimiter=","):
# see above
if __name__ == "__main__":
# LOAD DATA
file_directory = os.path.abspath("") + "\\flows\\"
daily_flow_dict = read_data(directory=file_directory, ftype="csv",
fn_prefix="daily_flows_", fn_suffix="",
delimiter=";")
print(daily_flow_dict[1995])Die Ausführung des Skripts liefert für das Jahr 1995 die numpy.array der täglichen Durchschnittsströme:
[[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 4. 0. 14.2 0. 0. 0. 81.7 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 19.7 0. ]
[ 0. 0. 19.8 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 4.8 0. 0. 0. 77.2 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 10.2 0. 0. 0. 0. 0. 0. 12. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 671.8]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 4.6 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 34.2 0. 0. 0. 0. ]
[ 0. 0. 0. 6.3 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 25.3 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 5. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 98.7 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 22.1 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. nan 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. nan 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. nan 0. nan 0. nan 0. 0. nan 0. nan 0. ]]Tägliche Ströme in monatliche Bände umrechnen¶
Der sequente Spitzenalgorithmus nimmt monatliche Durchflussmengen ein, was der Summe der täglichen durchschnittlichen Entladung multipliziert mit der Dauer eines Tages entspricht (z.B. 11.0 m/s 24 h/d 3600 s/h). Das Lesen der Flussdaten, wie oben gezeigt, führt zu jährlichen Flusstabellen (durchschnittliche Tagesflüsse in m/s) mit den numpy.arrays der Form 31x12-Arrays (Matrizen) für jedes Jahr. Wir möchten die Spaltensummen erhalten und die Summe mit 24 h/d 3600 s/h multiplizieren. Da die monatlichen Volumina in der Größenordnung von Millionen Kubikmetern (CMS) liegen, wird die Aufteilung der monatlichen Summen durch 10**6 die Zahlendarstellung vereinfachen.
Schreiben Sie eine Funktion (z.B. def daily2monthly(daily_flow_series)) zur Umsetzung der Tagesdurchschnittsreihe auf monatliche Volumina in 10m:
Die Funktion sollte für jeden Wörterbucheintrag (Jahr) der Datenreihe aufgerufen werden. Daher sollte das Eingabeargument
daily_flow_serieseinenumpy.arraymit der Form(31, 12)sein.Um spaltenweise (monatlich) Statistiken zu erhalten, transponieren Sie das Eingabefeld:
daily_flow_series = np.transpose(daily_flow_series)Create a void list to store monthly flow values:
monthly_stats = []Loop über die Zeile der (übersetzten)
daily_flow_seriesund fügen Sie die Summe multipliziert mit24 * 3600 / 10**6anmonthly_stats
for daily_flows_per_month in daily_flow_series:
monthly_stats.append(np.nansum(daily_flows_per_month * 24 * 3600) / 10**6)Zurück
monthly_statsalsnumpy.array:
return np.array(monthly_stats)Mit einer Schleife können wir nun die monatlichen Volumina ähnlich den Tagesflüssen in ein Wörterbuch schreiben, das wir bis zu einem Jahr innerhalb der if __name__ == "__main__" Erklärung verlängern:
import ...
def read_data(directory="", fn_prefix="", fn_suffix="", ftype="csv", delimiter=","):
# see above section
def daily2monthly(daily_flow_series):
# see above descriptions
if __name__ == "__main__":
# LOAD DATA
...
# CONVERT DAILY TO MONTHLY DATA
monthly_vol_dict = {}
for year, flow_array in daily_flow_dict.items():
monthly_vol_dict.update({year: daily2monthly(flow_array)})Sequent Peak Algorithm¶
Mit den obigen Routinen zum Lesen der Flussdaten haben wir monatliche Zuflussmengen in Mio. m (gespeichert unter monthly_vol_dict) abgeleitet. Für die Bewässerung und Trinkwasserversorgung möchte Vanille-arid das folgende jährliche Volumen aus dem Reservoir zurückziehen:
Monat* | Jan | Feb | Mar | Apr | Mai | Jun | Jul | Aug | Sep | Oct | Nov | Dec |¶
| ****** (10m) | 1.5 | 1.5 | 1.5 | 2 | 4 | 4 | 5 | 5 | 3 | 2 | 1,5 | 1,5 |
Nach dem Schema der Zuflussvolumina können wir eine numpy.array für die monatlichen Abflussvolumina erstellen.
monthly_supply = np.array([1.5, 1.5, 1.5, 2.0, 4.0, 4.0, 4.0, 5.0, 5.0, 3.0, 2.0, 1.5])Speichervolumen und Differenz (SD-line) Kurven¶
Das Lagervolumen des vorliegenden Monats wird aus der Wasserbilanz des letzten Monats berechnet, z.B.:
= + -
= + - = + + - -
In der Zusammenfassungsnotation können wir schreiben:
Die letzten beiden Begriffe sind die Speicherdifferenz () Zeile:
So ist die Speicherkurve in Abhängigkeit von der -Linie:
Die Summennotation der Speicherkurve in Abhängigkeit von der -Linie ermöglicht es uns, die Berechnung in eine einfache def sequent_peak(in_vol_series, out_vol_target):-Funktion umzusetzen.
Die neue def sequent_peak(in_vol_series, out_vol_target):-Funktion muss:
Berechnen Sie die monatlichen Speicherdifferenzen ( - ), z.B. in einer for-Schleife über das
in_vol_seriesWörterbuch:
# create storage-difference SD dictionary
SD_dict = {}
for year, monthly_volume in in_vol_series.items():
# add a new dictionary entry for every year
SD_dict.update({year: []})
for month_no, in_vol in enumerate(monthly_volume):
# append one list entry per month (i.e., In_m - Out_m)
SD_dict[year].append(in_vol - out_vol_target[month_no])Richten Sie das Wörterbuch auf eine Liste (das hätten wir auch direkt tun können) entsprechend der oben definierten -Linie:
SD_line = []
for year in SD_dict.keys():
for vol in SD_dict[year]:
SD_line.append(vol)Berechnen Sie die Speicherzeile mit
storage_line = np.cumsum(SD_line)Finden Sie lokale Extrema und es gibt zwei (und mehr) Optionen:
Verwenden Sie
from scipy.signal import argrelextremaund erhalten Sie die Indizes (Positionen) lokale Extrema und ihren Wert von derstorage_line:
seas_max_index = np.array(argrelextrema(storage_line, np.greater, order=12)[0])
seas_min_index = np.array(argrelextrema(storage_line, np.less, order=12)[0])
seas_max_vol = np.take(storage_line, seas_max_index)
seas_min_vol = np.take(storage_line, seas_min_index)Schreiben Sie zwei Funktionen, die nacheinander lokale Maxima und dann lokale Minima zwischen dem Extrema (Kurs *homework) finden ODER verwenden
from scipy.signal import find_peaks, um die Indizes (Positionen) zu finden - einefind_seasonal_extrema(storage_line)-Funktion schreiben.
Stellen Sie sicher, dass die Kurven und Extrema korrekt sind, indem Sie die bereitgestellte
plot_storage_curve-Kurve auf Ihr Skript kopieren (verfügbar in der Übung repository) und wie folgt verwenden:
plot_storage_curve(storage_line, seas_min_index, seas_max_index, seas_min_vol, seas_max_vol)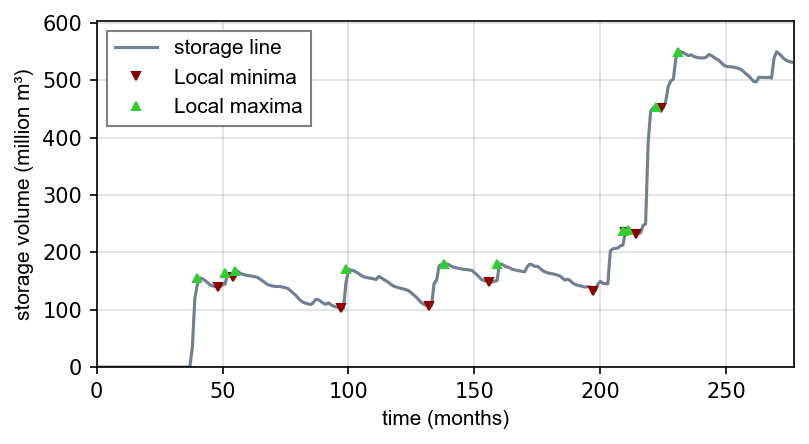
Figure 3:Speicherdifferenz (SD) Kurve.
Erforderliches Speichervolumen berechnen¶
Das benötigte Speichervolumen entspricht der größten Differenz zwischen einem lokalen Maximum und seinem aufeinanderfolgenden niedrigsten lokalen Minimum. Fügen Sie daher die folgenden Zeilen zur sequent_peak-Funktion hinzu:
required_volume = 0.0
for i, vol in enumerate(list(seas_max_vol):
try:
if (vol - seas_min_vol[i]) > required_volume:
required_volume = vol - seas_min_vol[i]
except IndexError:
print("Reached end of storage line.")Schließen Sie die sequent_peak-Funktion mit return required_volume
Call Sequent Peak Algorithm¶
Bei allen erforderlichen Funktionen ist die letzte Aufgabe, die Funktionen in der if __name__ == "__main__"-Anweisung anzurufen:
import ...
def read_data(directory="", fn_prefix="", fn_suffix="", ftype="csv", delimiter=","):
# see above section
def daily2monthly(daily_flow_series):
# see above section
def sequent_peak(in_vol_series, out_vol_target):
# see above descriptions
if __name__ == "__main__":
# LOAD DATA
...
# CONVERT DAILY TO MONTHLY DATA
...
# MAKE ARRAY OF MONTHLY SUPPLY VOLUMES (IN MILLION CMS)
monthly_supply = np.array([1.5, 1.5, 1.5, 2.0, 4.0, 4.0, 4.0, 5.0, 5.0, 3.0, 2.0, 1.5])
# GET REQUIRED STORAGE VOLUME FROM SEQUENT PEAK ALGORITHM
required_storage = sequent_peak(in_vol_series=monthly_vol_dict, out_vol_target=monthly_supply)
print("The required storage volume is %0.2f million CMS." % required_storage)Schlussbemerkungen¶
Die Verwendung des sequenten Spitzenalgorithmus (auch bekannt als Rippl’s Methode, aufgrund seines Originalautors) hat sich entwickelt und wurde in ausgeklügelten Speichervolumensteueralgorithmen mit Prädiktormodellen (statistisch und/oder numerisch) implementiert.
Am Ende gibt es mehrere Algorithmen und Möglichkeiten, sie zu kodieren. Viele Faktoren (z.B. Gelände oder Klimazone) bestimmen, ob eine saisonale Lagerung möglich oder notwendig ist. Bei der Bestimmung des Speichervolumens dürfen soziale und ökologische Aspekte nicht vernachlässigt werden. Jedes zurückgehaltene Sedimentkorn fehlt in nachgeschalteten Abschnitten des Flusses, jeder Fisch, der nicht mehr in der Lage ist, zu wandern, leidet unter einem Verlust des Lebensraums, und mehr als alles andere, jeder Bewohner, der wirtschaftliche Verluste erleidet oder sogar gezwungen ist, wegen des Staudamms zurückzusetzen, muss vermieden oder angemessen kompensiert werden.
- Potter, K. W. (1977). Sequent Peak Procedure: Minimum Reservoir Capacity Subject to Constraint on Final Storage. JAWRA Journal of the American Water Resources Association, 13(3), 521–528. 10.1111/j.1752-1688.1977.tb05564.x
- Rippl, W. (1883). The capacity of storage-reservoirs for water-slpply. (including plate). Minutes of the Proceedings of the Institution of Civil Engineers, 71(1883), 270–278. 10.1680/imotp.1883.21797