Préparez-vous en clonant le dépôt d’exercices :
git clone https://github.com/Ecohydraulics/Exercise-SedimentTransport.git
Figure 1:La rivière Arbogne en Suisse (source: Sebastian Schwindt 2013).
Théorie¶
1d Moyenne de section Hydrodynamique¶
À partir de l’exercice [formule Manning-Strickler*]](https://
où
est le coefficient Manning dans fictionnel des unités (s/m).
est la pente d’énergie hypothétique (m/m) et correspond à la pente du chenal pour des conditions d’écoulement stables et uniformes (non existantes dans les rivières naturelles).
rayon hydraulique , où (pour une section trapézoïdale):
la zone transversale (trapézoïdale) mouillée est ;
le périmètre mouillé d’un trapèze est ;
(largeur de base du canal) et (la pente de la rive) sont illustrés dans la figure ci-dessous pour calculer la largeur de surface de l’eau dépendante de la profondeur .
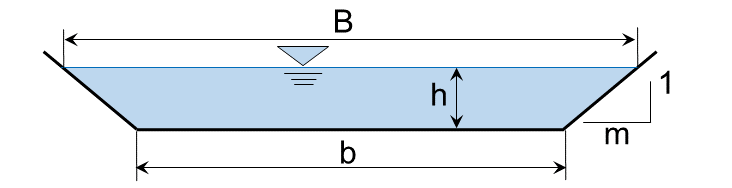
Cet exercice utilise des données hydrauliques moyennes de section unidimensionnelle (1d) produites avec le logiciel HEC-RAS U.S. Army Corps of Engineeers, 2016 du US Army Corps of Engineers, qui résout numériquement la formule Manning-Strickler pour toute forme de section transversale de flux. Dans le cadre de cet exercice, HEC-RAS fournit les données hydrauliques nécessaires pour déterminer la capacité sediment transport d’une section de canal, bien qu’aucune explication pour créer, exécuter et exporter des données à partir des modèles HEC-RAS ne soit donnée.
Transport des sédiments¶
Fluvial Sediment transport peut être distingué en deux modes : (1) suspended load et (2) bedload (voir Fig. 3). Les particules plus fines dont le poids peut être transporté par le fluide (eau) sont transportées comme suspended load. Les particules grossières qui roulent, glissent et sautent sur le lit du canal sont transportées comme bedload. Il y a un autre type de transport, la soi-disant charge de lavage, qui est plus fine que le gros bedload, mais trop lourd (large) pour être transporté en suspension Einstein, 1950.

Figure 3:Deux modes de transport des sédiments (source: Schwindt, 2017).
Dans ce qui suit, nous examinerons le mode de transport bedload. Dans ce cas, une particule sédimentaire située dans ou sur le lit de la rivière est mobilisée par les forces de cisaillement de l’eau dès qu’elles dépassent une valeur critique (voir figure ci-dessous). Dans l’hydraulique fluviale, la contrainte dite de cisaillement du lit sans dimension ou la contrainte Shields Shields, 1936 est souvent utilisée comme valeur seuil pour la mobilisation des sédiments du lit du fleuve (voir Fig. 4). Cet exercice utilise l’une des approches de contrainte de cisaillement de lit sans dimension et la section suivante fournit plus d’explications.
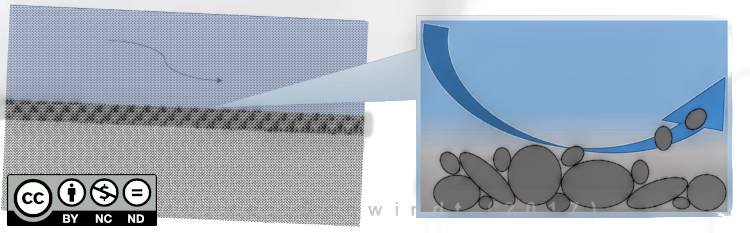
Figure 4:Le principe de la mobilisation des sédiments.
Formule Meyer-Peter et Müller (1948)¶
La formule Meyer-Peter & Müller (1948) pour estimer le transport bedload a été publiée par les chercheurs suisses Eugen Meyer-Peter (fondateur du Laboratoire d’hydraulique, d’hydrologie et de glaciologie (VAW) et Robert Müller. Leur étude a commencé un an après la création de la VAW en 1931 quand Robert Müller a été nommé assistant d’Eugen Meyer-Peter. Les deux scientifiques ont travaillé en collaboration avec Henry Favre et le fils d’Albert Einstein Hans Albert. En 1934, le laboratoire a publié pour la première fois une formule pour le calcul du transport bedload et sa relation fondamentale entre les contraintes de cisaillement de lit observées et critiques est utilisée jusqu’à aujourd’hui. Le taux de transport sans dimension bedload selon Meyer-Peter & Müller (1948) est:
Les autres paramètres sont:
2.68, the dimensionless ratio of sediment grain density ( 2680 kg/m³) and water density ( 1000 kg/m³);
, la taille caractéristique du grain en (m). On peut supposer que (c.-à-d. le diamètre du grain dont 84% d’un mélange de sédiments est plus petit) correspond à la littérature scientifique (p. ex. Rickenmann & Recking (2011)).
La formule Meyer-Peter & Müller ne s’applique (comme toute autre formule Sediment transport) qu’à certaines rivières présentant les caractéristiques suivantes (étendue de validité) :
0.4 10 m < 28.6 10 m
10 m 639 ( denotes the dimensionless Froude number)
0,0004 0,02
0,0002 m/(s m) 2.0 m/(s m) ( est la décharge de l’unité, c’est-à-dire )
0.25 3.2
L’expression sans dimension pour bedload a été utilisée pour permettre le transfert d’informations entre différents canaux à travers les échelles en préservant la similitude géométrique, cinématique et dynamique. L’ensemble des paramètres sans dimension utilise les résultats de Buckingham’s theorem Buckingham, 1915. Par conséquent, pour ajouter des dimensions à , il faut les multiplier avec le même ensemble de paramètres utilisés pour dériver l’expression sans dimension de Meyer-Peter & Müller. Leur ensemble de paramètres implique la taille caractéristique du grain , la densité du grain , et l’accélération gravitationnelle . Ainsi, l’unité dimensionnelle bedload est (en kg/s et largeur du compteur, c’est-à-dire kg/(sm):
The cross-section averaged bedload (kg/s) is then:
où est la largeur du canal hydrauliquement actif de la section transversale du flux (par exemple, pour un trapèze ).
Code¶
Définir le cadre¶
Le code orienté objet utilisera des classes personnalisées que nous appellerons dans un script main.py. Créer les scripts ** supplémentaires** suivants, qui contiendra les classes et les fonctions personnalisées pour contrôler l’enregistrement.
fun.pycontiendra des fonctions d’enregistrement.hec.pycontiendra une classeHecSetpour lire les données de sortie hydraulique de HEC-RAS comme objets structurés.grains.pycontiendra une classeGrainReaderpour lire les informations de classe de taille de grain comme objets structurés.bedload.pycontiendra la classeBedCoreavec les éléments de base que la plupart des formules bedload ont en commun.mpm.pycontiendra la classeMPM, qui hérite deBedCoreet calcule bedload comme décrit ci-dessus (Meyer-Peter & Müller 1948).
Nous allons créer les classes et les fonctions dans les scripts indiqués selon le diagramme de flux suivant:
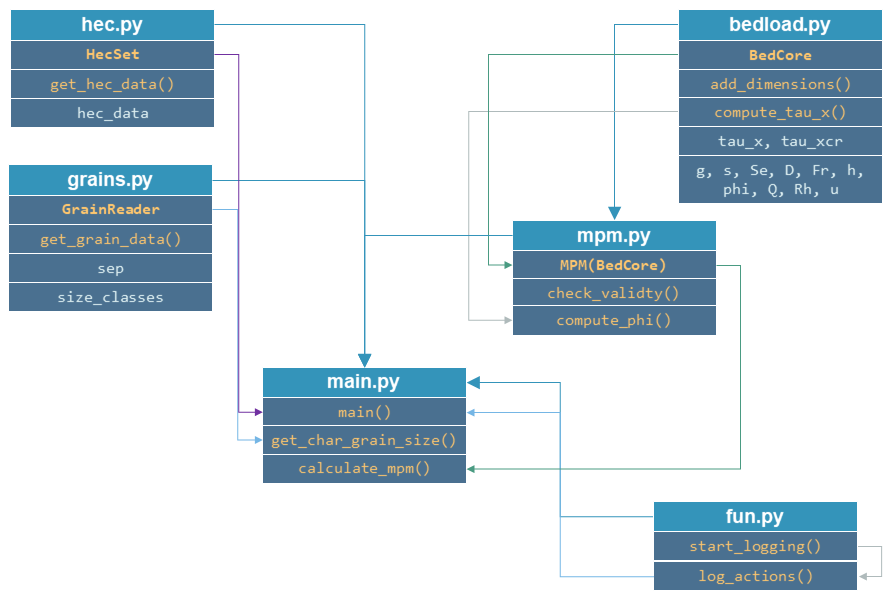
Pour commencer avec le script main.py, ajoutez une fonction main ainsi qu’une fonction get_char_grain_size et une fonction calculate_mpm. De plus, rendre le script stand-alone exécutable :
# This is main.py
import os
def get_char_grain_size(file_name, D_char):
return None
def calculate_mpm(hec_df, D_char):
return None
def main():
pass
if __name__ == '__main__':
main()
Fonctions d’exploitation¶
Le script fun.py contiendra deux fonctions :
start_loggingpour configurer des formats de journalisation et un nom de fichier journal comme décrit dans la section sur logging, etlog_actions, qui est une fonction d’emballage pour les fonctionsmain()(main.py) pour enregistrer les messages d’exécution de script.
La fonction start_logging devrait ressembler à cela (changer le nom du fichier journal si désiré):
import logging
def start_logging():
logging.basicConfig(filename="logfile.log", format="[%(asctime)s] %(message)s",
filemode="w", level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler()
La fonction log_actions wrapper suit les instructions de functions theory section:
def log_actions(fun):
def wrapper(*args, **kwargs):
start_logging()
fun(*args, **kwargs)
logging.shutdown()
return wrapperPour utiliser l’enveloppe log_actions tout au long du programme, nous le mettrons en œuvre au plus haut niveau, qui est la fonction main() à main.py:
# main.py
from fun import *
...
@log_actions
def main():
logging.info("This is a test message (do not keep in the function).")
if __name__ == '__main__':
main()
Maintenant, nous pouvons enregistrer des messages à différents niveaux (info, avertissement, erreur, etc.) dans toutes les fonctions appelées dans main() en utilisant par exemple logging.info("Message"), logging.warning("Message"), ou logging.error("Message") plutôt que la fonction print().
Lire les données sur la taille du grain¶
Sediment grain size classes (ranging from to ) are provided in the file grains.csv (delimiter=",") and can be customized.
Écrire une classe GrainReader qui utilise la méthode read_csv de Pandas pour lire la distribution de la taille du grain de grains.csv. Écrire la classe dans un script distinct Python (par exemple, grains.py comme indiqué dans la figure ci-dessus) :
class GrainReader:
def __init__(self, csv_file_name="grains.csv", delimiter=","):
self.sep = delimiter
self.size_classes = pd.DataFrame
self.get_grain_data(csv_file_name)La méthode get_grain_data devrait ressembler à ceci pour la lecture des classes de granulométrie fournies:
def get_grain_data(self, csv_file_name):
self.size_classes = pd.read_csv(csv_file_name,
names=["classes", "size"],
skiprows=[0],
sep=self.sep,
index_col=["classes"])Implémenter l’instantiation d’un objet GrainReader dans le script main.py dans la fonction get_char_grain_size. La fonction devrait recevoir les arguments de type string file_name (ici: "grains.csv") et D_char (i.e., la taille caractéristique du grain à utiliser de grains.csv). La fonction main() appelle la fonction get_char_grain_size avec les arguments file_name=os.path.abspath("..") + "\\grains.csv" et D_char="D84" (correspond à la première colonne grains.csv).
# main.py
import os
from grains import GrainReader
def get_char_grain_size(file_name=str, D_char=str):
grain_info = GrainReader(file_name)
return grain_info.size_classes["size"][D_char]
...
@log_actions
def main():
# get characteristic grain size = D84
D_char = get_char_grain_size(file_name=os.path.abspath("..") + "\\grains.csv",
D_char="D84")Lire les données d’entrée HEC-RAS¶
The provided HEC-RAS dataset is stored in the xlsx workbook HEC-RAS/output.xlsx and contains the following output:
Col. noCol. alphabétiqueVariableType/UnitéDescription
Col. 01: 01: 01: 01: 01: 01: 01: 01: 01 Col. 02: B: Sta de la rivière [m]: Position sur l’axe longitudinal de la rivière. C’est ce qu’a dit le Col 03 C’ Profil string
Col.
Col. 05* E* Min Ch El* [m a.s.l.]
Col. 06* F.S. Elev* Col. 07. G. Vel Chnl. [m] Col. 08:00 H:00 Zone de débit [m2]
Col. 09* I* Froude# Chl* Froude number du canal (si 1, erreur de calcul - ne pas utiliser!) Col. 10:00 J:00 Rayon hydraulique Col. 11:00 K:00 Profondeur de l’eau (moyenne de section active) Col. 12, rue E.G. Slope (en m/m)
Pour charger les données de sortie HEC-RAS, écrivez une classe personnalisée (dans un script séparé appelé hec.py) qui prend le nom du fichier comme argument d’entrée et lit le fichier HEC-RAS comme cadre de données pandas :
class HecSet:
def __init__(self, xlsx_file_name="output.xlsx"):
self.hec_data = pd.DataFrame
self.get_hec_data(xlsx_file_name)La méthode get_hec_data devrait ressembler à ceci :
def get_hec_data(self, xlsx_file_name):
self.hec_data = pd.read_excel(xlsx_file_name,
skiprows=[1],
header=[0])Pour créer un objet HecSet dans la fonction main() (main.py), nous devons l’importer et l’actualiser par exemple sous le nom de hec = HecSet(file_name). En outre, nous pouvons déjà implémenter le passage des données pd.DataFrame de HEC-RAS à la fonction calculate_mpm (également à main.py) que nous compléterons plus tard.
# main.py
import os
from ...
from hec import HecSet
...
@log_actions
def main():
D_char = ...
hec_file = os.path.abspath("..") + "{0}HEC-RAS{0}output.xlsx".format(os.sep)
hec = HecSet(hec_file)Créer une classe de base de charge de lit¶
Une classe BedCore écrite dans le script bedload.py fournit des variables et des méthodes, qui sont pertinentes à de nombreuses formules de calcul bedload et Sediment transport, comme la correction Parker-Wong Wong & Parker, 2006 ou Smart & Jaeggi (1983) (téléchargement direct). De plus, la classe BedCore contient des constantes telles que l’accélération gravitationnelle (i.e., self.g=9.81), le rapport entre le grain de sédiments et la densité de l’eau (i.e., self.s=2.68), et la contrainte de cisaillement du lit sans dimension critique (i.e., self.tau_xcr=0.047, qui peut être redéfinie par les utilisateurs). L’en-tête de la classe BedCore devrait ressembler à ceci :
from fun import *
import numpy as np
class BedCore:
def __init__(self):
self.tau_x = np.nan
self.tau_xcr = 0.047
self.g = 9.81
self.s = 2.68
self.rho_s = 2680.0 # kg/m3 sediment grain density
self.Se = np.nan # energy slope (m/m)
self.D = np.nan # characteristic grain size
self.Fr = np.nan # Froude number
self.h = np.nan # water depth (m)
self.phi = np.nan # dimensionless bedload
self.Q = np.nan # discharge (m3/s)
self.Rh = np.nan # hydraulic radius (m)
self.u = np.nan # flow velocity (m/s)Ajouter une méthode pour convertir la valeur sans dimension bedload transport en valeur dimensionnelle (kg/s). En plus des variables définies dans la méthode __init__, la méthode add_dimensions exigera la largeur effective du canal (recall the above calculus):
def add_dimensions(self, b):
try:
return self.phi * b * np.sqrt((self.s - 1) * self.g * self.D ** 3) * self.rho_s
except ValueError:
logging.warning("Non-numeric data. Returning Qb=NaN.")
return np.nanDe nombreuses formules de transport bedload impliquent la contrainte de cisaillement du lit sans dimension [ (voir ci-dessus definitions) associée à un ensemble de paramètres hydrauliques moyens de section transversale. Par conséquent, implémentez la méthode de calcul compute_tau_x à BedCore:
def compute_tau_x(self):
try:
return self.Se * self.Rh / ((self.s - 1) * self.D)
except ValueError:
logging.warning("Non-numeric data. Returning tau_x=NaN.")
return np.nanÉcrire une classe d’évaluation Meyer-Peter & Müller Charriage¶
Créez un nouveau script (par exemple mpm.py) et implémentez une classe MPM (Meyer-Peter & Müller) qui hérite de la classe BedCore. La méthode __init__ de MPM devrait initialiser BedCore et écraser (rappeler Polymorphisme) les paramètres pertinents au calcul de bedload selon Meyer-Peter & Müller (1948). En outre, l’initialisation d’un objet MPM devrait aller avec une vérification de la validité et le calcul du sans dimension bedload transport (voir ci-dessus explanations of MPM):
from bedload import *
class MPM(BedCore):
def __init__(self, grain_size, Froude, water_depth,
velocity, Q, hydraulic_radius, slope):
# initialize parent class
BedCore.__init__(self)
# assign parameters from arguments
self.D = grain_size
self.h = water_depth
self.Q = Q
self.Se = slope
self.Rh = hydraulic_radius
self.u = velocity
self.check_validity(Froude)
self.compute_phi()Ajouter la méthode check_validity pour vérifier si les caractéristiques transversales fournies tombent dans la plage de validité de la formule Meyer-Peter & Müller (c.-à-d. pente, granulométrie, rapport de débit et profondeur de l’eau, et Froude number):
def check_validity(self, Fr):
if (self.Se < 0.0004) or (self.Se > 0.02):
logging.warning('Warning: Slope out of validity range.')
if (self.D < 0.0004) or (self.D > 0.0286):
logging.warning('Warning: Grain size out of validity range.')
if ((self.u * self.h) < 0.002) or ((self.u * self.h) > 2.0):
logging.warning('Warning: Discharge out of validity range.')
if (self.s < 0.25) or (self.s > 3.2):
logging.warning('Warning: Relative grain density (s) out of validity range.')
if (Fr < 0.0001) or (Fr > 639):
logging.warning('Warning: Froude number out of validity range.')Pour calculer la méthode sans dimension bedload transport selon Meyer-Peter & Müller, implémenter une méthode compute_phi qui utilise la méthode compute_tau_x de BedCore:
def compute_phi(self):
tau_x = self.compute_tau_x()
try:
if tau_x > self.tau_xcr:
self.phi = 8 * (0.85 * tau_x - self.tau_xcr) ** (3 / 2)
else:
self.phi = 0.0
except TypeError:
logging.warning("Could not calculate PHI (result=%s)." % str(tau_x)
self.phi = np.nanAvec la classe MPM définie, nous pouvons maintenant remplir la fonction calculate_mpm dans le script main.py. La fonction devrait créer un cadre de données pandas avec des colonnes sans dimension bedload transport et dimensionnel bedload transport associé à un profil de canal ("River Sta") et un scénario de flux ("Profile" > "Scenario").
Le bloc de code suivant illustre un exemple de la fonction calculate_mpm qui crée le cadre de données pandas à partir d’un Dictionnaire (mpm_dict). La fonction d’illustration crée le dictionnaire avec des listes de valeurs nulles, extrait les données hydrauliques du cadre de données HEC-RAS et des boucles sur les entrées "River Sta". La boucle vérifie si les entrées "River Sta" sont valides (c.-à-d. pas "Nan") parce que les lignes vides que HEC-RAS ajoute automatiquement entre les profils de sortie ne doivent pas être analysées. Si la vérification a été réussie, la boucle ajoute le profil, le scénario et la décharge directement à mpm_dict. La section bedload résultats de transport d’objets MPM. Après la boucle, la fonction retourne mpm_dict comme objet pd.DataFrame.
# main.py
from ...
from ...
from mpm import *
...
def calculate_mpm(hec_df, D_char):
# create dictionary with relevant information about bedload transport with void lists
mpm_dict = {
"River Sta": [],
"Scenario": [],
"Q (m3/s)": [],
"Phi (-)": [],
"Qb (kg/s)": []
}
# extract relevant hydraulic data from HEC-RAS output file
Froude = hec_df["Froude # Chl"]
h = hec_df["Hydr Depth"]
Q = hec_df["Q Total"]
Rh = hec_df["Hydr Radius"]
Se = hec_df["E.G. Slope"]
u = hec_df["Vel Chnl"]
for i, sta in enumerate(list(hec_df["River Sta"]):
if not str(sta).lower() == "nan":
logging.info("PROCESSING PROFILE {0} FOR SCENARIO {1}".format(str(hec_df["River Sta"][i]), str(hec_df["Profile"][i]))
mpm_dict["River Sta"].append(hec_df["River Sta"][i])
mpm_dict["Scenario"].append(hec_df["Profile"][i])
section_mpm = MPM(grain_size=D_char,
Froude=Froude[i],
water_depth=h[i],
velocity=u[i],
Q=Q[i],
hydraulic_radius=Rh[i],
slope=Se[i])
mpm_dict["Q (m3/s)"].append(Q[i])
mpm_dict["Phi (-)"].append(section_mpm.phi)
b = hec_df["Flow Area"][i] / h[i]
mpm_dict["Qb (kg/s)"].append(section_mpm.add_dimensions(b)
return pd.DataFrame(mpm_dict)Après avoir défini la fonction calculate_mpm(), l’appel à cette fonction à partir de la fonction main() devrait maintenant attribuer un cadre de données Pandas à la variable mpm_results. Pour finaliser le script, écrivez mpm_results à un cahier de travail (par exemple, "bed_load_mpm.xlsx") dans la fonction main():
# main.py
import os
from ...
...
def calculate_mpm(hec_df, D_char):
...
@log_actions
def main():
...
mpm_results = calculate_mpm(hec.hec_data, D_char)
mpm_results.to_excel(os.path.abspath("..") + os.sep + "bed_load_mpm.xlsx")Lancement et débogage¶
Dans votre IDE, exécutez le script (par exemple, PyCharm, faites un clic droit dans le script main.py et cliquez sur > Run 'main'). Si le script s’écrase ou soulève des messages d’erreur, retracez-les et corrigez les problèmes. Ajouter try - except déclarations si nécessaire et rappeler le debugging instructions.
Une exécution réussie de main.py produit un fichier bed_load_mpm.xlsx qui ressemble à ceci:
Scénario Q (m3/s)
Q moyenne HQ2.33.33.43.43.42.72291418. HQ5 : 17 : 0.682792055 : 54.58338633 : HQ10 de 1970 à 1970 HQ10025 0.90554296777.92848176 Q moyenne HQ2.33 ,13 ,144406226 ,14,00424884 HQ5 : 17 : 0.203854633 : 20.40484039 : HQ10: 19:0.29078172:0 23.1352098:0 QG10025 0.29776754631.25225316
Oui.
Le fichier journal devrait ressembler à ceci:
[20XX-XX-XX 14:08:22,900] PROCESSING PROFILE 1970.1 FOR SCENARIO Q mean
[20XX-XX-XX 14:08:22,900] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,901] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ2.33
[20XX-XX-XX 14:08:22,901] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,901] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ5
[20XX-XX-XX 14:08:22,902] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,902] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ10
[20XX-XX-XX 14:08:22,902] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,902] PROCESSING PROFILE 1970.1 FOR SCENARIO HQ100
[20XX-XX-XX 14:08:22,903] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,903] PROCESSING PROFILE 1893.37 FOR SCENARIO Q mean
[20XX-XX-XX 14:08:22,903] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,903] PROCESSING PROFILE 1893.37 FOR SCENARIO HQ2.33
[20XX-XX-XX 14:08:22,903] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,904] PROCESSING PROFILE 1893.37 FOR SCENARIO HQ5
[20XX-XX-XX 14:08:22,904] Warning: Discharge out of validity range.
[20XX-XX-XX 14:08:22,904] PROCESSING PROFILE 1893.37 FOR SCENARIO HQ10
[20XX-XX-XX 14:08:22,904] Warning: Discharge out of validity range.
[...]- U.S. Army Corps of Engineeers. (2016). Hydrologic Engineering Centers River Analysis System (HEC-RAS). U.S. Army Corps of Engineeers (USACE). http://www.hec.usace.army.mil/software/hec-ras/
- Einstein, H. A. (1950). The Bed-Load Function for Sediment Transport in Open Channel Flows. Technical Bulletin of the USDA Soil Conservation Service, 1026, 71. 10.22004/ag.econ.156389
- Schwindt, S. (2017). Hydro-morphological processes through permeable sediment traps [Thesis No. 7655, Laboratory of Hydraulic Constructions (LCH), Ecole Polytechnique fédérale de Lausanne (EPFL)]. 10.5075/epfl-thesis-7655
- Shields, A. (1936). Anwendung der Ähnlichkeitsmechanik und der Turbulenzforschung auf die Geschiebebewegung [Application of the similarity in mechanics and turbulence research on the mobility of bed load] (Vol. 26). Preußische Versuchsanstalt für Wasserbau und Schiffbau. http://resolver.tudelft.nl/uuid:61a19716-a994-4942-9906-f680eb9952d6
- Meyer-Peter, E., & Müller, R. (1948). Formulas for Bed-Load transport. IAHSR, Appendix 2, 2nd meeting, 39–65. http://resolver.tudelft.nl/uuid:4fda9b61-be28-4703-ab06-43cdc2a21bd7
- Rickenmann, D., & Recking, A. (2011). Evaluation of flow resistance in gravel-bed rivers through a large field data set. Water Resources Research, 47, W07538. 10.1029/2010WR009793
- Buckingham, E. (1915). Model experiments and the forms of empirical equations. Transactions of the American Society of Mechanical Engineers, 37, 263–296.
- Wong, M., & Parker, G. (2006). Reanalysis and Correction of Bed-Load Relation of Meyer-Peter and Müller Using Their Own Database. Journal of Hydraulic Engineering, 132(11), 1159–1168. 10.1061/(ASCE)0733-9429(2006)132:11(1159)
- Smart, G. M., & Jaeggi, M. N. R. (1983). Sedimenttransport in steilen Gerinnen [Sediment Transport on Steep Slopes]. Mitteilung Nr. 64 der Versuchsanstalt für Wasserbau, Hydrologie und Glaziologie an der Eidgenössischen Technischen Hochschule Zürich. https://ethz.ch/content/dam/ethz/special-interest/baug/vaw/vaw-dam/documents/das-institut/mitteilungen/1980-1989/064.pdf
- Schwindt, S., Negreiros, B., Mudiaga-Ojemu, B. O., & Hassan, M. A. (2023). Meta-Analysis of a Large Bedload Transport Rate Dataset. Geomorphology, 435, 108748. 10.1016/j.geomorph.2023.108748