Support Vector Machine (SVM)¶
Dieses Tutorial verfügt über die Support Vector Machine (SVM) Technik zur Klassifizierung von Flussbettmorphologietypen in Abhängigkeit von hydraulischen und sedimentären Transportdaten.
Enable interactive reading and executing code blocks with  and find morphology-predictor-svm.ipynb Alternatively, install Python and JupyterLab locally and download this Jupyter notebook.
and find morphology-predictor-svm.ipynb Alternatively, install Python and JupyterLab locally and download this Jupyter notebook.
Theorie¶
Im Bereich der Restaurierungswissenschaft liefert die Identifizierung der Flussmorphologie wesentliche Erkenntnisse, um beispielsweise das Ziel terraforming zu leiten, das darauf abzielt, einen naturnahen Zustand einer fluvialen Landschaft wiederzuerkennen. Darüber hinaus kann morphologisches Muster als Prädiktor für die Schätzung von fluvialsediment transport und umgekehrt dienen. So besteht eine bidirektionale Beziehung zwischen fluvialen Hydraulik, Sedimenttransport und morphologischem Muster, die physischen Lebensraum für Wasserarten darstellen und sogar die Energieerzeugung Recking et al., 2016 beeinflussen können.
Dennoch ist die Klassifizierung und Vorhersage der flouvialen Morphodynamik aufgrund der Komplexität der Flussökosysteme und jeder Fluss eine einzigartige Umgebung. Allerdings wiederholen sich morphologische Einheiten von Flüssen mit ähnlichen Eigenschaften. Ein grundlegender Satz von repetitiven morphologischen Merkmalen wurde von Montgomery & Buffington (1997) eingeführt, und wir werden uns in diesem Tutorial auf die folgenden fünf morphologischen Einheiten konzentrieren (klicken Sie auf die Artikel, um mehr zu lesen):
Diese morphologischen Einheiten finden Sie in der oben genannten Reihenfolge entlang eines Flusses, beginnend an der Quelle und enden mit seiner Mündung. So können Stufenpool-Einheiten in der Regel in stromaufwärts (Mountain) Flussabschnitt gefunden werden, während sand Betten überwiegend in flacheren Flussabschnitten, in der Nähe von Mündungen oder Zusammenflüssen vorhanden sind. Beachten Sie, dass es noch viele andere morphologische Einheiten gibt, wie z.B. Slackwater, swales oder Bars Wyrick & Pasternack, 2014. Abb. Figure 1 illustriert einige morphologische Einheiten von naturnahen Flüssen.

Figure 1:a) Ein kolluvialer Kopfwasserstrom (Furtschaglbach, Österreich), b) ein Kaskadenstrom (Torrent des Favrands, Frankreich), c) ein Gesteinsstrom (Anse St-Jean, Québec, Kanada), d) ein Stufenstrom (Dessoubre, Frankreich), e) ein Flugzeugbettstrom (Dranse, Schweiz), f) ein Riffle-Kan Quelle: Schwindt (2017)
To guide restoration actions, experts often visually classify morphology units on-site, though some of them may also be distinguishable on aerial imagery. On-site (in-situ) expert assessments may also serve as ground truth for machine learning models. In this exercise, we will use hydrodynamic parameters with expert-based ground truth from the database https://
Vorverarbeitung¶
Daten zum Thema¶
We downloaded a dataset from https://
Jede Probe stammt aus den Querschnitten von 146 verschiedenen Flüssen rund um den Globus.
Der Datensatz umfasst Hydraulik- und Sedimenttransporte (z.B. Korngrößen), obwohl wir in diesem Tutorial nur die folgenden Parameter verwenden, um das SVM-Modell zu trainieren:
*W: Kanalbreite (m)
S: Kanalschräge (m)
Q: Entlastung (ms)
U: Volumenstromgeschwindigkeit (m s)
*H: Wassertiefe (m)
In einem maschinellen Lernkontext werden diese Parameter zur Vorhersage von morphologischen Einheiten ** auch Features* genannt. Der erste Schritt besteht darin, die Daten als pandas.DataFrame zu laden (und anzuzeigen):
import pandas as pd
data= pd.read_csv("data/bedload_dataset")
dataDatensatz reinigen¶
Um zu vermeiden, dass das SVM-Modell durch Statiken beeinflusst wird, die auf Nonsense-Einträgen (z.B. Not-a-Number *NaN)-Werten oder extremen Ausreißern, z.B. aus Typos, beruhen, werden wir einige Reinigungsmethoden anwenden.
NaN Werte entfernen¶
Der erste Reinigungsschritt besteht darin, NaNs zu entfernen, die das SVM-Modell später zu schlechten Schlussfolgerungen führen können.
# dataset essencial info
print(data.info(),"\n")
# remove rows that contains at least one NaN value
print(data.dropna(inplace=True))
# verify that all NaN values were removed
for column in data.columns.to_list():
print(column,":",data[column].isnull().any())
# verify final shape of the dataset
print(data.shape)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1067 entries, 0 to 1066
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 W 1067 non-null float64
1 S 1067 non-null float64
2 Q 1067 non-null float64
3 U 1067 non-null float64
4 H 1067 non-null float64
5 Morphology 1067 non-null object
dtypes: float64(5), object(1)
memory usage: 50.1+ KB
None
None
W : False
S : False
Q : False
U : False
H : False
Morphology : False
(1067, 6)
Ausreißer suchen¶
Ausreißer können in extremer Umgebung oder unter extremen Bedingungen auftreten (z.B. intensive Ausfällung), aber einige von ihnen stammen auch aus Geräteausfällen, die die Leistung des SVM-Modells beeinflussen. Das Erkennen und Entfernen solcher gerätebezogenen Ausreißer ist somit ein wesentlicher Schritt.
Die Visualisierung der aufgetragenen Funktionen in einem Scatter-Plot kann hilfreich sein, um Ausreißer Kandidaten zu erkennen. Der folgende Codeblock erzeugt Streubilder jeder Funktion, markiert den erwarteten Wert und den Abstand von 2 Standardabweichungen (erfasst eine Gaussian-ähnliche Verteilung).
from mpl_toolkits.axes_grid1 import host_subplot
import mpl_toolkits.axisartist as AA
import numpy as np
import matplotlib.pyplot as plt
# visualize scatter of the features
host = host_subplot(111, axes_class=AA.Axes)
plt.subplots_adjust(right=0.75)
# plot visualization parameters
labels = data.columns[0:5].tolist()
colors = ["crimson", "purple", "limegreen", "gold", "blue"]
width=0.5
# iterate on features of the dataset (i.e. column names)
for i, l in enumerate(labels):
if i ==0:
ax = host
ax.set_ylabel(labels[i])
else:
ax = host.twinx()
new_fixed_axis = ax.get_grid_helper().new_fixed_axis
ax.axis["right"] = new_fixed_axis(loc="right",
axes=ax,
offset=(60*(i-1), 0))
ax.axis["right"].toggle(all=True)
ax.set_ylabel(labels[i])
x = np.ones(data.shape[0])*i + (np.random.rand(data.shape[0])*width-width/2.)
ax.scatter(x, data[data.columns[i]],color=colors[i])
mean = data[f"{data.columns[i]}"].mean()
std = np.std(data[data.columns[i]])
ax.plot([i-width/2., i+width/2.], [mean, mean], color="k")
ax.plot([i,i], [mean-2*std, mean+2*std], color="k")
ax.set_xticks(range(len(labels)))
ax.set_xticklabels(labels)
plt.draw()
plt.show()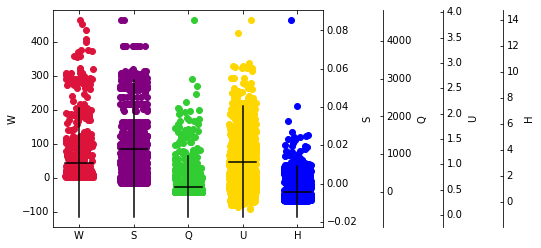
Ausreißer entfernen¶
Ausreißer können mit zwei verschiedenen Methoden entfernt werden:
Handbuch (d.h. fachkundiges Urteil): Erkennen von Ausreißern der Merkmale und entfernen sie durch Festlegung von Grenzen ihres Intervalls.
Automated: Nehmen Sie eine Wahrscheinlichkeitsverteilung an und setzen Sie Grenzen basierend auf einer niedrigen Wahrscheinlichkeit des Beobachtungsereignisses.
Die folgenden Codeblöcke implementieren diese beiden Optionen (manual-expert und automatisiert) Methoden. Die manuelle Ausreißerentfernung ist hard coded , da die Grenzen von Experten gegeben werden sollten.
The automated approach (below else statement) assumes the data having a Gaussian distribution, where points with a so-called z-score greater than 4 (four) are removed. Data points with a z-score less or equal to four have a 99.9%-chance of being inside an interval of four standard deviations away from the expected value. Thus, a sample that has a 0.01%-chance of occurrence is considered automatically an outlier and removed from the dataset. Thus, in this case, the z-score represents the standard deviation, and we use the zscore function of the scipy library.
from scipy.stats import zscore
# choose the method to remove outliers
# remove_method = "expert_analysis"
remove_method = "zscore"
if "expert" in remove_method:
data = data.loc[(data["qs"]<0.02) &
(data["Q"]<2000) &
(data["W"]<250)]
else:
data = data[(np.abs(zscore(data.loc[:,data.columns!="Morphology"])) < 4).all(axis=1)]
dataÜberprüfung der Klassenproportionen¶
Ein maschinelles Lernmodell erfordert die Grundwahrheitsdaten, um einem Qualitätsstandard gerecht zu werden. Diese beinhalten (u.a.):
Jede Kombination von Modellen benötigt eine andere Mindestanzahl an Proben statistische Signifikanz. Es ist keine triviale Aufgabe, die minimale Anzahl von Proben zu identifizieren, die ein vertrauenswürdiges Modell liefern. Um jedoch eine Klasse korrekt darzustellen (was auch immer das bedeutet), muss die so genannte Frequenzverteilung jeder Funktion ähnlich sein wie die populationFrequenzverteilung.
Mit mehr als 30 Samples, wenn es um normal verteilte Variablen geht, ist eine bewährte Daumenregel.
Idealerweise sollten die für ein Klassifikationsproblem verwendeten Klassen durch eine ähnliche Probenmenge repräsentiert werden. Ein unausgeglichener Datensatz kann ein Modell erzeugen, das die Klasse mit einer größeren Anzahl von Proben bevorzugt korrekt klassifiziert. Dies ist eine Folge der Verwendung von Genauigkeit als Leistungsmetrik. Genauigkeit ist das Verhältnis der korrekten und der Gesamtzahl der Vorhersagen (). Durch das Vorziehen der Gesamtzahl der korrekten Vorhersagen über eine ausgeglichene, maskiert die Genauigkeit die Wichtigkeit, die unterrepräsentierten Klassen richtig zu bekommen.
Lösungen zum Ausgleich von unsymmetrischen Proben umfassen:
Erfassung oder Generierung neuer Daten (z.B. Monte Carlo-Methoden). Wenn verfügbar, precision ist für die Messung der Modellpeformance (anstelle der Genauigkeit) bevorzugt.
Weighting-Klasse-Features, was bedeutet, Gewichte zuzuweisen, um die Bedeutung von unterrepräsentierten Klassen richtig zu erhöhen. In Klassifikationsproblemen testen Sie verschiedene Kombinationen der Gewichtsausbeute an ROC-Kurve, die den Einfluss unterschiedlicher Gewichte auf die Modellleistung zeigt.
In diesem Tutorial können die Proben als ausgeglichen angesehen werden, mit Ausnahme der Sandbettklasse (siehe Ausgabe unten). Gewichtung und ROC-Kurven werden hier nicht berücksichtigt. Wenn die Empfindlichkeit und Spezifikation der Sandbettklasse bei der Klassifizierung von Testdaten akzeptabel wäre, könnte das Modell auch für die Sandbettklassifikation verwendet werden, ohne dass dies mit der Anwendung von Ausgleichstechniken zu tun wäre.
data["Morphology"].value_counts()Step-pool 247
Plane Bed 243
Riffle-pool 241
Braiding 228
Sand bed 79
Name: Morphology, dtype: int64Neue Predictors¶
Manchmal ist es möglich, neue aussagekräftige Merkmale aus den vorhandenen zu berechnen. Bekannte Vorhersagen für Morphologie sind beispielsweise:
das Produkt von (Energie) Neigung (-), Schüttgeschwindigkeit (m/s) und Wassertiefe (m), die im Grunde shear stress
das Verhältnis von Entlastung (m/s) und Breite (m) (d.h. Q/W)
import warnings
from pandas.core.common import SettingWithCopyWarning
warnings.simplefilter(action="ignore", category=SettingWithCopyWarning)
# compute new columns for the new features SUH and Q/W
data["SUH"] = (data.loc[:,"S"]*data.loc[:,"U"]*data.loc[:,"H"])
data["Q/W"] = (data.loc[:,"Q"]/data.loc[:,"W"])
dataMulticolinearität überprüfen¶
Korrelierte Merkmale (d.h. statistisch abhängige Messparameter) können zu unzuverlässigen Modellen führen. Betrachten Sie beispielsweise einen Wissenschaftler, der maschinelles Lernen (ML)-Modelle verwenden möchte, um die Anzahl der Touristen vorherzusagen, die in Brasilien während ihres Urlaubs sonnenverbrannt werden. Sie will die Sonneneinstrahlungsintensität und die Anzahl der als Features verkauften Eiscremes nutzen. Der Wissenschaftler kann feststellen, dass beide Merkmale relevant sind, um die Anzahl der sonnenverbrannten Touristen vorherzusagen, aber der Grund für diese Feststellung ist, dass die Anzahl der Eisdielen verkauft wird, und die Sonnenintensität korreliert. So hat der Wissenschaftler keine Möglichkeit zu wissen, was die wirkliche Bedeutung jedes Merkmals bei der Vorhersage von sonnenverbrannten Touristen ist, weil die Merkmale gleichzeitig wachsen und abnehmen. Übrigens haben Eiscreme-Verbrauch und Sonnenbrand keine Kausalität gemein, aber das ist ein weiteres Thema.
Zu diesem Zweck ist es wichtig, die Korrelation zwischen den Merkmalen zu untersuchen und die damit verbundenen Merkmale zu beseitigen, um ein zuverlässigeres Modell zu produzieren. Eine Möglichkeit, die Kolinearität visuell zu erkennen, zeigt die Kombination zweier Variablen in einem Streudiagramm. Zu diesem Zweck werden die nachstehenden Abbildungshilfen folgende Aspekte der bedload_dataset:
Es besteht eine starke lineare Korrelation zwischen den und Features.
Es besteht keine lineare Korrelation zwischen und .
Die Strömungsgeschwindigkeit distribuiton ist annähernd normal (siehe Hauptdiagonale).
import seaborn as sns
# plot scatter of the 2d (two dimensinal) combination of features
sns.pairplot(data.loc[:,data.columns!="Morphology"])
plt.show()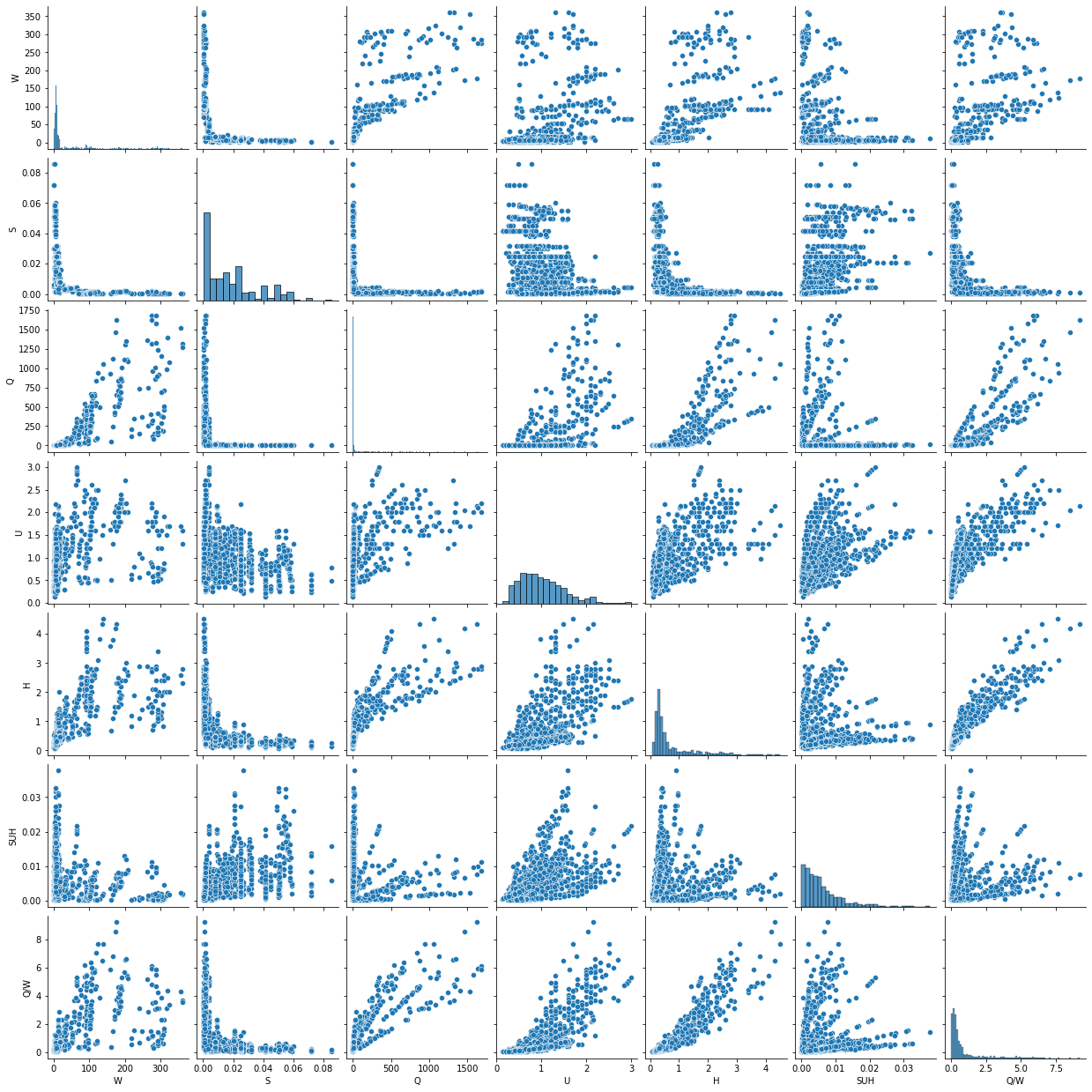
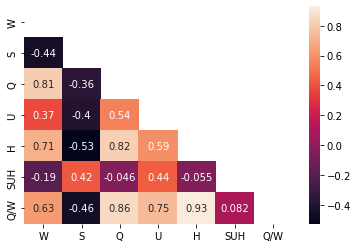
Darüber hinaus ist eine heatmap eine weitere effiziente Methode, um lineare Korrelation unter Features zu visualisieren. Auch die Berechnung lineare Korrelation ermöglicht eine quantitative Analyse.
from seaborn import heatmap
# verify linear coorralation
feature_corr_df = data.loc[:,data.columns!="Morphology"].corr()
mask = np.zeros_like(feature_corr_df)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(feature_corr_df,
annot=True, # print value inside the grid
mask=mask # mask values (boolean matrix)
)
Varianz Inflationsfaktor (VIF)¶
Eine einfache Methode zur Bewertung multicollinerity ist die Berechnung des Varianz-Inflationsfaktors (VIF) für jede Funktion, die die Korrelation unter den Merkmalen quantifiziert.
Der erste Schritt zur Berechnung des VIF behandelt ein Feature als abhängige Variable und passt zu einem linearen Regressionsmodell unter Verwendung der anderen Features als unabhängige Variable. Zweitens speichern Sie die entsprechenden mittleren Quadratfehler , die vom linearen Modell geliefert werden.
Schließlich kann VIF für jedes Merkmal durch folgende Gleichung berechnet werden:
ist der Varianz-Inflationsfaktor der -Funktion und
ist der mittlere Quadratfehler, der sich aus der linearen Regression der -Funktion ergibt.
Je kleiner das MSE (besseres lineares Regressionsmodell) ist, desto größer ist die Inflation. Mit anderen Worten weisen große VIF-Werte eine hohe Korrelation des betrachteten Merkmals mit zumindest einer der anderen Merkmale auf. Dennoch ist es nicht möglich, basierend auf VIF nur zu sagen, was other feature dazu führt, dass VIF aufblasen wird.
In der Regel des Daumens zeigt ein VIF größer als 10 (ten) einen ungeeigneten Satz von Merkmalen zur Herstellung eines zuverlässigen ML-Modells. Idealerweise sollte der VIF kleiner als 5 (fünf) bleiben, was als moderate Korrelation gilt Franke, 2010. Diese Referenzwerte sind jedoch keine allgemein gültige Regel. VIF gleich oder größer als 10 kann noch ein gutes Modell liefern.
Eine weitere Analyse zur Untersuchung der Auswirkungen eines hohen VIF auf korrelierte Merkmale kann durch Entfernen jeder Funktion zu einem Zeitpunkt durchgeführt werden und untersuchen, wie die Merkmalsentfernung die Variation des Standardfehler und p-value des Modells beeinflusst.
In diesem Tutorial haben 2 Funktionen einen VIF 10 (insbesondere und ), wie die folgenden Code-Block-Shows zeigen.
from sklearn.linear_model import LinearRegression
# compute VIF for the features
def calculate_vif(df, features):
vif, tolerance = {}, {}
for feature in features:
# extract all the other features you will regress against
X = [f for f in features if f != feature]
X, y = df[X], df[feature]
# extract r-squared from the fit
r2 = LinearRegression().fit(X, y).score(X, y)
# compute VIF
vif[feature] = 1 / (1 - r2)
# return VIF DataFrame
return pd.DataFrame({'VIF': vif})
# call fuction calculate_vif with features as input
calculate_vif(df=data,
features=data.columns[data.columns != "Morphology"].to_list())Entfernen Sie die Eigenschaften, um VIF zu reduzieren¶
Mit dem Ziel, die Funktion VIFs auf weniger als 5 zu reduzieren, verwenden wir in diesem Tutorial einen Test-und-Fehler-Ansatz. Die Änderung des folgenden Code-Blocks zeigt, dass die Entfernung von und ausreicht, um die VIFs der übrigen Features auf weniger als 5 zu reduzieren. Insbesondere gehen diese beiden entfernten Variablen auch in oben vorgestellte Features und . Obwohl und entfernt werden, tragen sie immer noch “Informationen” zum Abschlussmodell bei.
Die Kombination von korrelierten Merkmalen, um eine neue zu produzieren und später zu entfernen, ist ein gemeinsamer Ansatz, um VIFs zu reduzieren. Da wir durch Entfernen einiger Merkmale gute VIF-Werte lieferten, ist keine weitere Analyse erforderlich.
Schließlich werden die Merkmale, die zum Trainieren und Testen des SVM-Modells verwendet werden, durch die Ausgabe des Codeblocks unten dargestellt.
# try and error approach removing features get VIFs < 10
data = data.loc[:, data.columns[(data.columns !="H")&
(data.columns !="Q")
]
]
# compute VIF again to verify if VIFs are less than 5
calculate_vif(df=data,
features=data.columns[data.columns != "Morphology"].to_list())Split Test- und Trainingsdatensätze¶
Der letzte Vorbereitungsschritt für den Aufbau des SVM-Modells besteht darin, ein Training und einen Testdatensatz aus dem gesamten bedload_dataset abzuleiten. Die Auswahl eines Anteils an Daten zur Erstellung eines Trainings und eines Testdatensatzes ist in der Regel eine heuristische Wahl. Hier verwenden wir 33% der Daten, um später eine endgültige Hypothese zu testen. Beachten Sie, dass innerhalb der Split-Datensätze der Index der Proben (Reihen der tabellarischen Daten) ihre entsprechende Klasse innerhalb der target-Datensätze haben.
from sklearn.model_selection import train_test_split
# split dataframes with features and labels only
labels = data.loc[:, "Morphology"]
predictors = data.loc[:, data.columns[data.columns != "Morphology"]]
# split testing set as 33% of the data
# X correspond to the featues (matrix form)
# y corresponf to the labels (vector form)
X_train, X_test, y_train, y_test = train_test_split(predictors,
labels,
test_size=0.3,
random_state=42 # seed for random selection of data
)
# visualize training and testing sets
print("TRAINING DATASET PREDICTORS")
print(X_train.head(), "\n")
print("dataframe size", X_train.shape,"\n")
print("------------------------------------------")
print("TRAINING DATASET TARGET")
print(y_train,"\n")
print()
print("------------------------------------------------------------------------------------\n")
print("TESTING DATASET PREDICTORS")
print(X_test.head())
print("dataframe size", X_test.shape,"\n")
print("------------------------------------------")
print("TESTING DATASET TARGET")
print(y_test.head())
print("Vector size", y_test.shape)
TRAINING DATASET PREDICTORS
W S U SUH Q/W
256 6.91 0.01100 1.02 0.003366 0.277858
397 88.09 0.00210 1.99 0.008149 3.889545
586 14.02 0.02070 1.34 0.022190 1.078459
526 218.00 0.00041 0.52 0.000175 0.541284
9 8.00 0.02000 1.18 0.007316 0.370000
dataframe size (726, 5)
------------------------------------------
TRAINING DATASET TARGET
256 Plane Bed
397 Plane Bed
586 Step-pool
526 Sand bed
9 Riffle-pool
...
89 Riffle-pool
337 Plane Bed
476 Plane Bed
123 Riffle-pool
876 Braiding
Name: Morphology, Length: 726, dtype: object
------------------------------------------------------------------------------------
TESTING DATASET PREDICTORS
W S U SUH Q/W
203 2.57 0.01040 1.58 0.008216 0.793774
937 105.00 0.00096 1.90 0.002918 3.076190
546 93.00 0.00050 1.10 0.001320 2.688172
214 53.04 0.00380 1.44 0.004596 1.211916
312 6.28 0.02020 0.34 0.001511 0.074841
dataframe size (312, 5)
------------------------------------------
TESTING DATASET TARGET
203 Riffle-pool
937 Braiding
546 Sand bed
214 Riffle-pool
312 Plane Bed
Name: Morphology, dtype: object
Vector size (312,)
Bauen Sie das SVM Modell¶
Arbeitsprinzip¶
Eine Support Vector Machine (SVM) ist ein Lernalgorithmus, der nach einem sogenannten *hyperplane sucht, der Funktionsklassen optimal trennt. Um eine optimale Trennung zu finden, versucht der Algorithmus, den Abstand (oder den Rand) vom Hyperplan zu den nächsten Datenpunkten zu maximieren. Die Datenpunkte in der Nähe der Grenzen der Marge werden auch mit -Unterstützungsvektoren bezeichnet, da sie als Verweis auf draw das Hyperplane arbeiten (siehe Abb. Figure 2 unten).
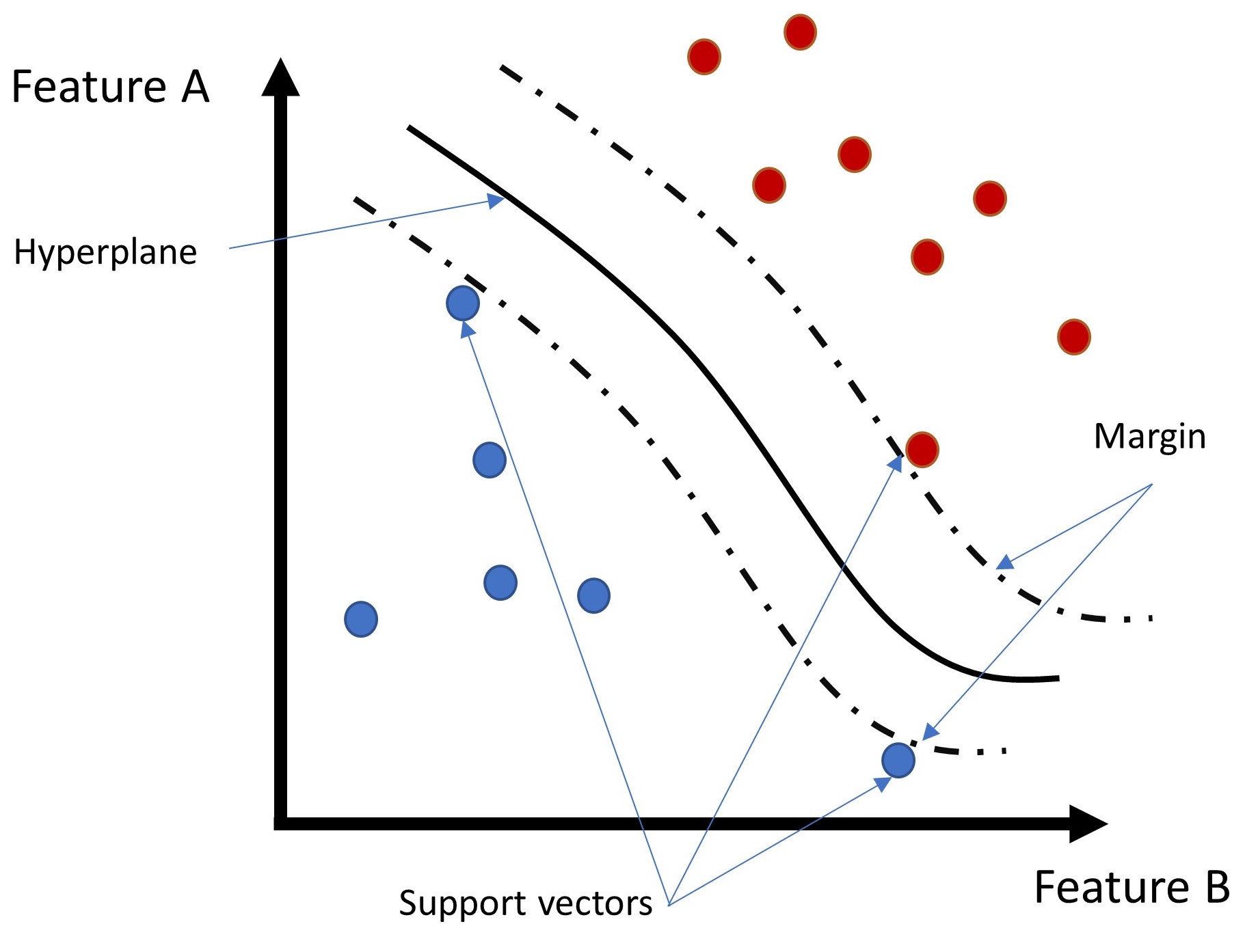
Figure 2:Abbildung eines Hyperplans und Margen eines SVM. Quelle: Ricardo Barros
Nehmen Sie beispielsweise an, dass zwei der obigen Klassen linear trennbar sind. Wir können die Regionen definieren, die jede Klasse mittels des folgenden Hyperplans enthalten:
--> Class Red und --> Class Blue
wenn
ist der Gewichtsvektor,
ist die Matrix der Features,
ist die unabhängige Variable (auch bias) und
der Wert von 1 wird als repräsentative Vereinfachung gewählt, da grundsätzlich jeder Wert sein kann.
Schließlich (nach einigen Schritten, die hier nicht diskutiert werden), können wir ein optimales Hyperplane berechnen, indem wir den folgenden Ausdruck minimieren:
wobei der transponierte Gewichtsvektor ist.
In der realen Welt ist es jedoch üblich, Probleme zu finden, bei denen Klassen nicht linear trennbar sind. In solchen Situationen können sogenannte Kernel eingesetzt werden. Ein Kernel ist eine Funktion, die zu einer Matrix mit höheren Dimensionen transformiert, indem die verfügbaren Funktionen kombiniert werden, um neue Features zu erstellen (d.h. neue Dimensionen).
Hier wenden wir die Radius Base Function (RBF) kernel an. Der RBF ist ein beliebter Kernel, weil er den in eine unendliche Dimensionsmatrix verwandelt, ohne dass das Modell überholt werden kann.
k-fach Kreuzvalidierung¶
SVMs, bestehend aus einem RBF-Kernel, können durch Abstimmung zweier Parameter validiert werden:
C : bestimmt, wie viel die Margen permissiv sind. Sie unterscheidet sich zwischen einer hard-Marge (d.h. einer Marge, die ein Eindringen von Datenpunkten nur wenig oder gar nicht ermöglicht) und einer soft-Marge* (d.h. einer Marge, die das Eindringen von Datenpunkten innerhalb der Marge ermöglicht). Ein höherer C entspricht einer härteren Marge.
gamma : bestimmt den Bereich der Ähnlichkeit zwischen den Proben. Es ist die einzige Variable des RBF-Kernels. Je höher Gamma ist, desto breiter ist der Einfluss einer markierten Probe auf die Klassifizierung einer neuen Probe.
Harte Margen können auch als *-Sensitivität des Hyperplans interpretiert werden, wenn es mit den Daten passt. Je härter der Rand, umso mehr die Hyperplane verdreht, um keinen Datenpunkt in den Rand eindringen zu lassen.
In diesem Tutorial definieren wir C basierend auf einem Try-and-Eror-Ansatz und einem Gamma, das aus einem fünffachen cross-validation. Der folgende Codeblock baut die SVM mit der sklearnBibliothek auf und druckt die Validierungs- und Trainingsfehlerkurven, die sich aus unterschiedlichen gamma ergeben.
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
# define C, gamma range, kernel and number of cross-val. folds
gamma_range = np.logspace(-5, 3, 13)
C=500 # chosen hyperparameter through tunnig
kernel = "rbf" # radius base function
n_of_folds = 5
# Peform 5-fold cross-validation and save training and validation error
train_scores, test_scores = validation_curve(SVC(kernel=kernel,
C=C),
X_train,
y_train,
param_name="gamma",
param_range=gamma_range,
scoring="accuracy",
cv=n_of_folds
)
# convert accuracy into error
train_error = 1-train_scores
validation_error = 1-test_scores
# compute 5-fold cross-validation mean and std of error
train_error_mean = np.mean(train_error, axis=1)
train_error_std = np.std(train_error, axis=1)
validation_error_mean = np.mean(validation_error, axis=1)
validation_error_std = np.std(validation_error, axis=1)
#-------------------------------------------------------------------
# visualization of training and error validation
plt.title("Validation Curve with SVM")
plt.xlabel(r"$\gamma$")
plt.ylabel("Error (1-accuracy)")
plt.ylim(-0.01, 1.1)
lw = 2
plt.semilogx(
param_range, train_error_mean, label="Training error", color="darkorange", lw=lw
)
plt.fill_between(
param_range,
train_error_mean - train_error_std,
train_error_mean + train_error_std,
alpha=0.2,
color="darkorange",
lw=lw,
)
plt.semilogx(
param_range, validation_error_mean, label="Cross-validation error", color="navy", lw=lw
)
plt.fill_between(
param_range,
validation_error_mean - validation_error_std,
validation_error_mean + validation_error_std,
alpha=0.2,
color="navy",
lw=lw,
)
plt.legend(loc="best")
plt.show()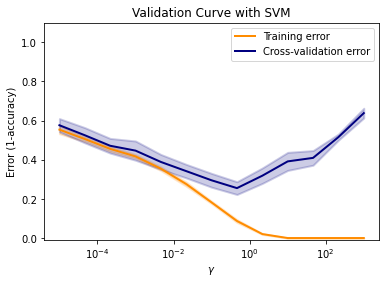
Optimale Parameter auswählen¶
Die Entscheidung über optimale Parameter für den SVM hängt von Ihrer Meinung ab. Zur Auswahl optimaler Parameter in diesem Tutorial quantifiziert der nachfolgende Codeblock das oben gezeigte Diagramm (insbesondere die blaue Kurve) in tabellarischer Form und speichert das Gamma, das den kleinsten Fehler liefert ( gamma opt ).
# save optimal gamma
index_min = min(range(len(validation_error_mean)), key=validation_error_mean.__getitem__)
validation_error_min = validation_error_mean[index_min]
gamma_opt = param_range[index_min] # gamma that gives minimun validation error
# visualize error evolution with gamma
columns = ["Mean validation error","gamma"]
array = np.array([validation_error_mean, param_range]).transpose()
print( pd.DataFrame(array,columns=columns), "\n")
print("Minimun mean validation error:", validation_error_min)
print("optimal gamma:", gamma_opt) Mean validation error gamma
0 0.575739 0.000010
1 0.524856 0.000046
2 0.471101 0.000215
3 0.446311 0.001000
4 0.388474 0.004642
5 0.341606 0.021544
6 0.294709 0.100000
7 0.254861 0.464159
8 0.318262 2.154435
9 0.391252 10.000000
10 0.409173 46.415888
11 0.515144 215.443469
12 0.637789 1000.000000
Minimun mean validation error: 0.2548606518658479
optimal gamma: 0.46415888336127725
Zug Optimum Hypothese SVM Modell¶
Nach der Definition eines Gammas, der den kleinsten Validierungsfehler ( gamma opt ) liefert, können wir auf dem gesamten Trainingsdatensatz ein optimales Hypothesenmodell ( h opt ) trainieren. Darüber hinaus können wir die Genauigkeit des Modells bewerten, indem wir es verwenden, um den Testdatensatz zu klassifizieren. Der untere Codeblock verfügt über das Training, das Bestücken des SVM (d.h. eine optimale Hypothese) und druckt die Punktzahl der optimalen Hypothese.
# train optimal model and evaluate accuracy
h_opt = SVC(kernel=kernel,
gamma=gamma_opt,
C=C) # instantiate optimal model
h_opt.fit(X_train,y_train) # train the model with entire training set
print("Error (1-Accuracy) of h_opt on testing data: \n -->>",1- h_opt.score(X_test,y_test)) Error (1-Accuracy) of h_opt on testing data:
-->> 0.19551282051282048
Performance Evaluation (Confusion Matrix)¶
Schließlich erzeugt der folgende Codeblock die sogenannte -Konfusionsmatrix, um die optimale Hypothesenmodellleistung bei der Klassifizierung der Proben mit unterschiedlichen Morphologien auszuwerten. Die Verwirrungsmatrix verwendet die Gesamtzahl der Proben und visualisiert ihre wahren und vorhergesagten morphologischen Einheiten.
from sklearn.metrics import plot_confusion_matrix
#plot confusion matrix
plot_confusion_matrix(h_opt, # trained optimal hypothesis model
X_test,
y_test,
)
plt.xticks(rotation=45)
plt.show()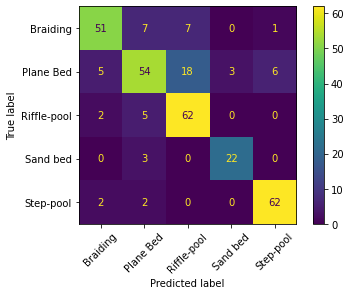
Die Verwirrungsmatrix eines exakten Modells hat nur Diagonaleinträge größer als Null, während alle anderen Null sind. So zeigt die oben gezeigte Verwirrungsmatrix, dass unser SVM-Modell bei der Vorhersage von Schritt-Pool- und Riffle-Pool-Mmorphologien sehr gut ausführt, aber aufgrund nicht vieler Beobachtungen unzuverlässigerweise Sandbettmorphologien vorhersagt. Allerdings machte das Modell auch falsche Vorhersagen von Schritt-Pool und Riffle Pool-Features. So prognostizierte das Modell nach der Verwirrungsmatrix 6 mal Schritt-Pool, wo in Wirklichkeit (wahres Etikett), morphologische Einheiten des Planbetts vorherrschten und es falsch prognostizierte eine Geflechtsbeobachtung als Schritt-Pool Beobachtung. Die Sandbettvorhersagen sind unzuverlässig, da es nur 25 wahr-markierte Sandbettbeobachtungen gibt (begrenzt auf 66 Schritt-Pool Beobachtungen). So sind die Sandbettbeobachtungen unsymmetrisch und eine Lösung zur Entfernung der Unzuverlässigkeit könnte es sein, mehr Sandbett-morphologische Einheiten (wie oben erläutert) abzuproben.
- Montgomery, D. R., & Buffington, J. (1997). Channel-reach morphology in mountain drainage basins. Geological Society of America Bulletin, 109(5), 596–611. https://doi.org/10.1130/0016-7606(1997)109<;0596:CRMIMD>2.3.CO;2
- Recking, A., Piton, G., Vazquez-Tarrio, D., & Parker, G. (2016). Quantifying the morphological print of bedload transport. Earth Surface Processes and Landforms, 41(6), 809–822.
- Wyrick, J. R., & Pasternack, G. B. (2014). Geospatial organization of fluvial landforms in a gravel-cobble river: Beyond the riffle-pool couplet. Geomorphology, 213(Supplement C), 48–65. 10.1016/j.geomorph.2013.12.040
- Schwindt, S. (2017). Hydro-morphological processes through permeable sediment traps [Thesis No. 7655, Laboratory of Hydraulic Constructions (LCH), Ecole Polytechnique fédérale de Lausanne (EPFL)]. 10.5075/epfl-thesis-7655
- Franke, G. R. (2010). Multicollinearity. Wiley International Encyclopedia of Marketing.