In diesem Abschnitt werden wir grundlegende Konzepte der nichtlinearen Klassifizierung durch die Einführung des Konzepts von Kerneln abdecken. Lassen Sie uns zunächst daran erinnern, was wir bisher in unserem Abschnitt über Lineare Klassifizierung gesehen haben. In der linearen Klassifikation bestand unsere Aufgabe darin, Datenpunkte durch ein Hyperplan zu klassifizieren, das den Datensatz in den Merkmalen den Koordinatenraum linear trennen könnte. Zum Beispiel in einem 3d-Funktionsraum, also einem Merkmalsvektor wie (x1,x2,x3)∈R3, erinnern Sie daran, dass unsere Daten als linear trennbar angesehen werden, wenn es mindestens eine Ebene (nicht Zeile), die die Punkte teilen kann. Im Gegensatz zur linearen Klassifizierung, die eine lineare Beziehung zwischen Eingabemerkmalen und Klassenetiketten einnimmt, verwenden nichtlineare Klassifizierungsalgorithmen verschiedene Techniken, um komplexe Muster und Entscheidungsgrenzen in den Daten zu erfassen. Insbesondere werden wir uns anschauen, wie wir unsere Daten durch Kernels in einen neuen Koordinatenraum höherer Dimension transformieren können, der uns dabei hilft, das nichtlineare Problem in einen linearen zu verwandeln.
Kernels ermöglichen es uns, Daten in einen überdimensionalen Funktionsraum zu transformieren, in dem eine lineare Trennung möglich wird. Ein Beispiel für den ML-Algorithmus, der auf Kernel basiert, um komplexe Muster und Entscheidungsgrenzen in den Daten zu finden, ist Support Vector Machine (SVM).
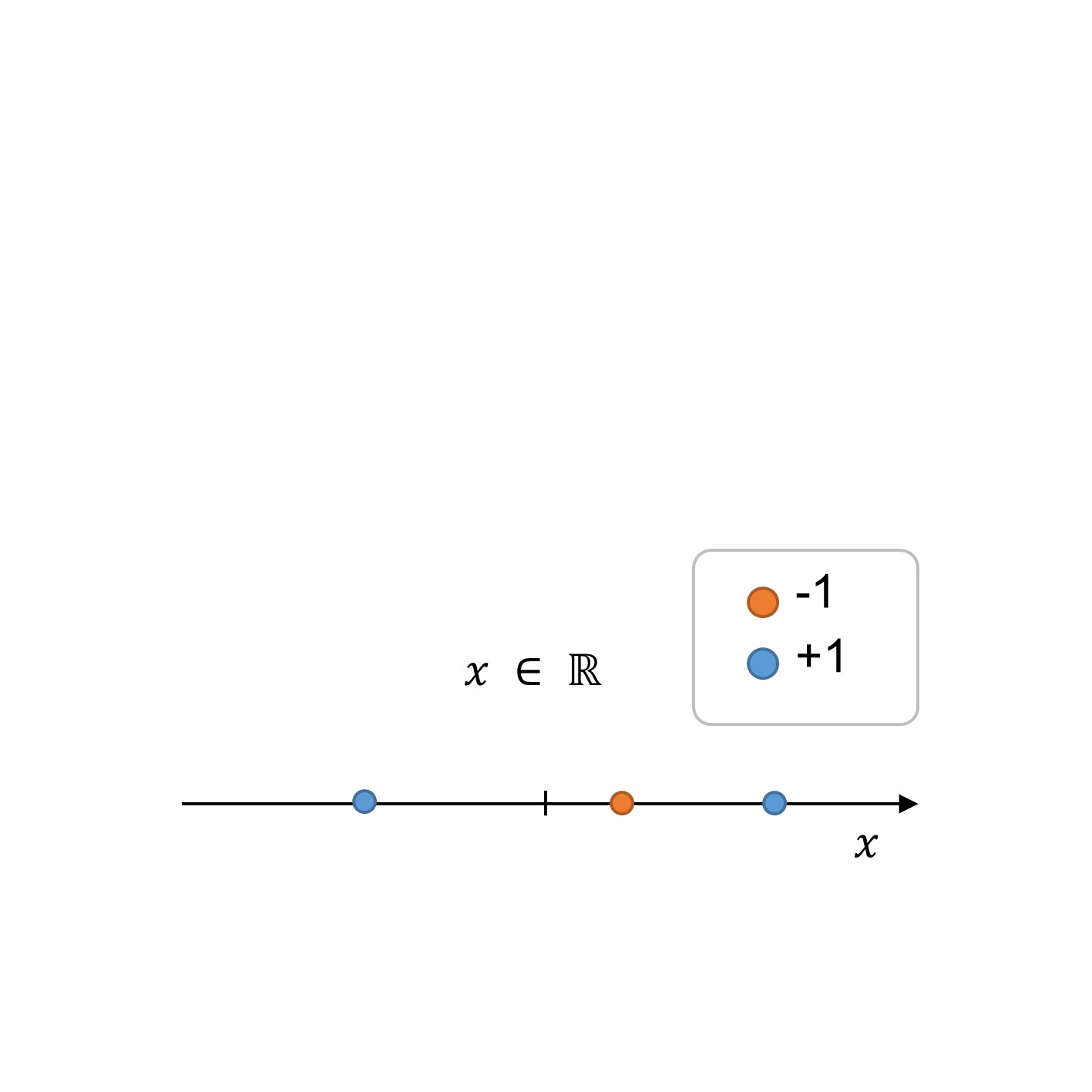
Wir werden nun sehen, wie Feature-Transformation über ein Beispiel funktioniert, d.h. wir haben eine Funktion x∈R. Die nachstehende Abbildung zeigt die Ausbildungspunkte (n=3).
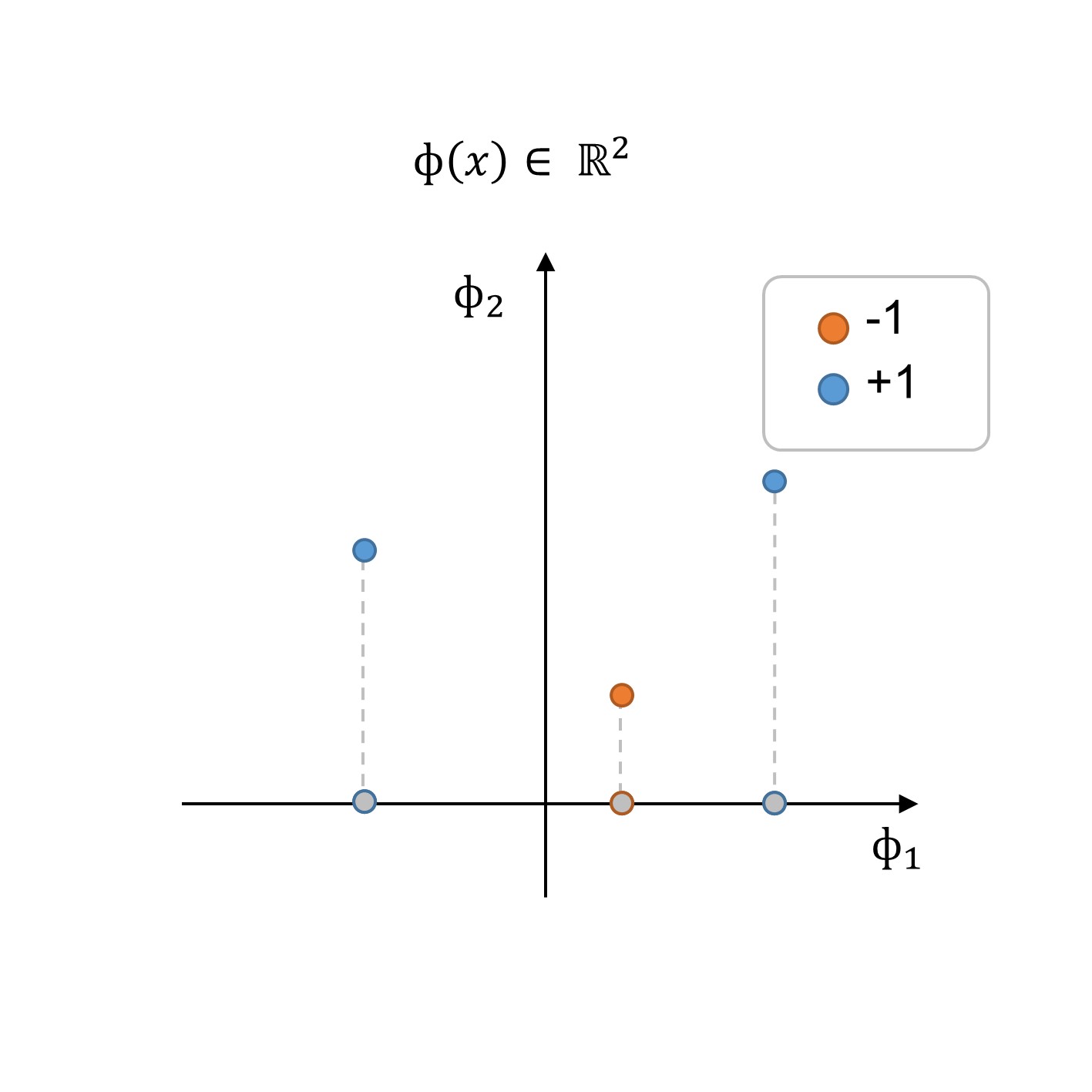
Beachten Sie aus der Figur, dass der Datensatz nicht linear trennbar ist, zumindest nicht in dem angegebenen Merkmalsraum in 1 Dimension. Um dieses Problem zu einem linearen Problem zu machen, können wir eine Feature-Transformation (ϕ(x)) durchführen, um eine Entscheidungsgrenze in einem überdimensionalen Raum zu suchen. In diesem speziellen Beispiel sei darauf hingewiesen, dass wir das 1d-Feature in einen neuen 2d-Featurevektor transformieren können, wo die zusätzliche Dimension als eine Art neues Feature angesehen werden kann.
Figure 1:1: Trainingsdaten im ersten Funktionsraum.
Figure 2:2: Trainingsdatensatz im neuen Feature-Bereich Φ(x).
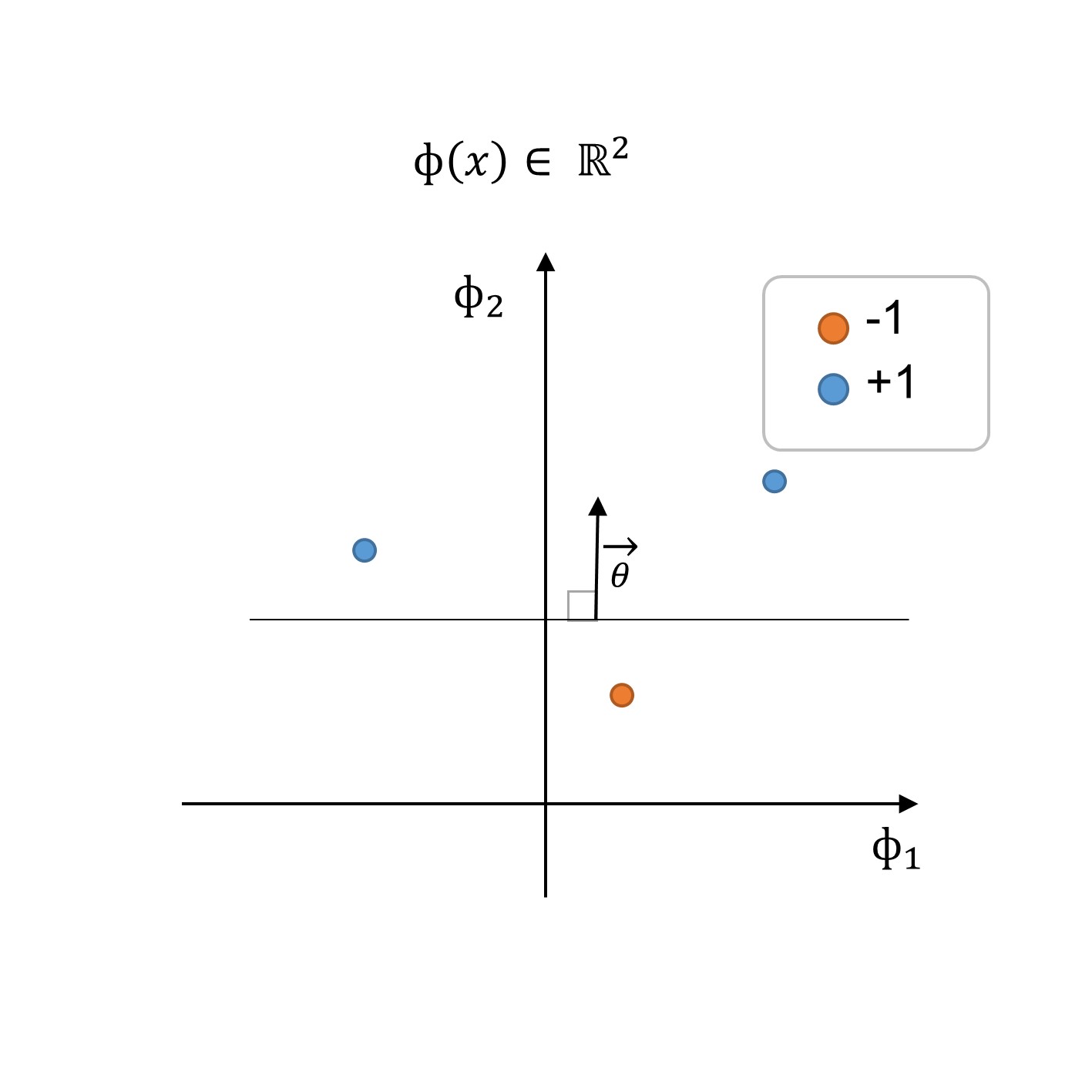
Figure 3:3: Trainingsdatensatz und Entscheidungsgrenzen im neuen Feature-Bereich Φ(x)
Durch die Ausführung der Feature-Transformation, wie in Schritt 2: Trainingsdatensatz im neuen Feature-Bereich Φ(x) (siehe Abbildung oben) dargestellt, finden wir einen Klassifikator h(x,θ,θo) mit einer Entscheidungsgrenze von θ und den Offset-Parameter θ0: