Überarbeitetes Lernen¶
Vorhandene ML-Algorithmen sind verschieden und ihre Anwendbarkeit hängt von der zu erlernenden Zielaufgabe (oder mapping) ab. Perceptron, Support Vector Machine, Pegasos, Decision Bäume, Random Forests, Neural Networks, sind alle Beispiele von ML-Algorithmen, die einem supervised learning Ansatz folgen, der im Mittelpunkt dieses Abschnitts steht. Dieser Abschnitt hat folgende Ziele:
Gesamtkonzept des maschinellen Lernens verstehen
Elemente des überwachten Lernens verstehen
Elemente des überwachten Lernens¶
Im beaufsichtigten Lernen gibt es Beispiele (d.h. Messungen) zusammen mit der Ziellösung (d.h. Labels), die wir dem ML-Modell wünschen, um zu lernen, wie man abbildet. Im Gegensatz dazu gibt es bei unsupervised learning Probleme Beispiele, aber wir kennen die Ziellösung nicht oder labels. Ein typisches Beispiel für unübertroffenes Lernproblem ist das Clustering.
Schulung und Prüfung¶
Ziel eines ML-Algorithmus nach einem überwachten Lernansatz ist es, herauszufinden, wie man die Ziellösung aus Training-Beispielen reproduziert. So ist ein ML-Modell eine Funktion, die die Ziellösung aus dem Parametersatz der Beispiele abbildet. Wir beginnen mit der Hypothesisierung eines Satzes von möglichen Mappers (oder Funktionen), die eine Reihe von Parametern (oder features) als Argumente / Eingabe, um die Ziellösungen zu liefern. Damit definieren wir den Hypothesenraum als Satz möglicher Modelle (Klassifikatoren, Regressoren). Der Algorithmus automatisiert dann den Prozess der Suche nach den besten Modell-Parameter (d.h. das beste Modell), die mit den Beispiel-Label-Paare übereinstimmen. Dies geschieht durch Optimierung des Modells auf der Hand eines Trainingsdatensatzes ().
Das Ziel unserer Maschine ist es, eine In-to-Output-Regel zu finden, die durch eine mathematische Funktion gekennzeichnet ist, so dass:
wo unsere Attribute sind, auch als features bekannt sind, sind die Datensatz-Etiketten, die Zielwerte, die wir erstellen möchten.
Unsere Aufgabe ist es, die beste Hypothese (oder bestes Modell) unter dem Satz von Hypothesen zu finden. Wir tun dies, indem wir unsere Hypothese jedes Mal aktualisieren, wenn wir eine ausgewählte Anzahl von Ausbildungsbeispielen durchlaufen, so dass eine verbesserte Hypothese von unserer aktuellen Hypothese berechnet wird. Intuitiv, wenn ein bestimmtes Trainingspaar (Training Dataset) missklassifiziert, dann möchten wir , wie zu sein, aber in Richtung einer genauen Klassifizierung . Um weniger schlecht an einem Trainingsbeispiel zu machen, werden wir in einem winzigen Bit entlang des Negativs der Ableitung der Optimierungsfunktion () nudge nudge. Ein solches Optimierungsverfahren wird Gradient Descent (GD) genannt, da wir den Gradienten der Optimierungsfunktion nutzen, um unsere Hypothese auf eine bessere Version zu aktualisieren.
So würde das Update aussehen:
wobei die so genannte Lernrate ist.
Beachten Sie, dass die Hypothese (Modell) ist hier ein Vektor von Modellparametern (nicht zu verwechseln mit Features), auch genannt Gewichte für einige ML-Algorithmen.
Optimierungsfunktion: Verlust- und Regelbedingungen¶
Der Prozess der Verbesserung unserer Hypothese (oder Modell) besteht aus einem Optimierungsproblem, bei dem wir eine Optimierungsfunktion () minimieren möchten. Intuitiv möchten wir Diskrepanzen zwischen vorhergesagten und tatsächlichen Werten von minimieren. Diese Diskrepanzen werden in Bezug auf eine Verlust-Funktion ausgedrückt, die quantifiziert, wie gut unser Modell bei einem bestimmten Beispielpaar durchgeführt wurde. Gleichzeitig wünschen wir uns nicht, dass unser Modell die Verlustfunktion so sehr minimiert und damit den Trainingsdaten so angepasst ist, dass es nicht mehr auf einen brandneuen Datensatz anwendbar ist. Aus diesem Grund führen wir einen Regelbegriff ein, der darauf abzielt, die Komplexität des Modells zu minimieren. Schließlich wäre unsere Optimierungsfunktion:
wobei die Anzahl der Ausbildungsbeispiele ist.
Es gibt einige Gründe, warum wir unser Modell nicht an den Trainingsdatensatz überrüsten möchten. Zunächst kann unser Trainingsdatensatz statistische Geräusche enthalten, die wir nicht mit unserem Klassifikator erfassen möchten. Die folgende Abbildung verdeutlicht das Konzept:
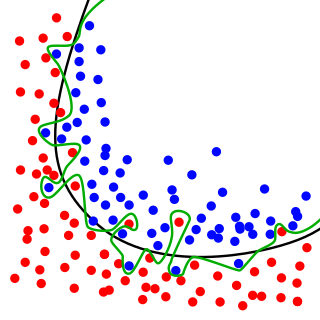
In der Figur können wir deutlich erkennen, dass die grüne Linie auf die von zwei Klassen (blaue und rote Punkte) bezeichneten Trainingsdatenpunkte überreicht wird. Die schwarze Linie ist wahrscheinlich eine zufriedenstellende Entscheidungsgrenze, um die roten und blauen Punkte zu teilen.
Der zweite Grund, warum wir unser Modell nicht überrüsten wollen, ist, weil unser Ziel im Zentrum von maschinellen Lernproblemen ist, ein Modell anwenden zu können, das von einem Trainingsdatensatz auf die Weltdaten gelernt wird. Daher wünschen wir, dass unser Modell allgemeinert oder korrekt das, was für einen breiteren, unseen Datensatz gelernt wurde, anwendet. Um zu überprüfen, ob unser Modell gut funktioniert, reicht es nicht aus, den Trainingsfehler zu minimieren. Wir müssen die gelernten Parameter auf einem ungesehenen Datensatz, dem sogenannten Testdatensatz, testen.
Einstufung und Regression¶
Im Allgemeinen kann ein ML-Modell ausgebildet werden, um zu lernen, wie man Kategorien oder kontinuierliche Werte vorhersagen kann. In beiden Ansätzen verwenden wir die obigen Konzepte, um einen Klassifikator bzw. einen Regressor zu erstellen. Der Hauptunterschied wird darin bestehen, wie wir den Training-Fehler oder loss berechnen. In den nächsten Abschnitten werden wir beide Probleme aus einer überwachten Lernperspektive abdecken.