Machine vectorielle de soutien (SVM)¶
Ce tutoriel présente la technique SVM (Support Vector Machine) pour classer les types de morphologie des lits fluviaux en fonction des données de transport hydraulique et sédimentaire.
Enable interactive reading and executing code blocks with  and find morphology-predictor-svm.ipynb Alternatively, install Python and JupyterLab locally and download this Jupyter notebook.
and find morphology-predictor-svm.ipynb Alternatively, install Python and JupyterLab locally and download this Jupyter notebook.
Théorie¶
Dans le domaine de la science de la restauration, l’identification de la morphologie fluviale fournit des indications essentielles, par exemple, pour guider la terraformation ciblée visant à rétablir un état naturel proche du recensement d’un paysage fluvial. De plus, le modèle morphologique peut servir de prédicteur pour estimer le fluvial sediment transport et vice versa. Ainsi, il existe une relation bidirectionnelle entre l’hydraulique fluviale, le transport des sédiments et le modèle morphologique, qui représentent l’habitat physique des espèces aquatiques et peuvent même affecter la production d’énergie Recking et al., 2016.
Pourtant, la classification et la prédiction de la morphodynamique fluviale sont difficiles en raison de la complexité des écosystèmes fluviaux et de chaque rivière étant un environnement unique. Cependant, on répète des unités morphologiques de rivières ayant des caractéristiques similaires. Un ensemble de fonctionnalités morphologiques répétitives a été introduit par Montgomery & Buffington (1997), et nous nous concentrerons dans ce tutoriel sur les cinq unités morphologiques suivantes (cliquez sur les éléments pour en savoir plus) :
Ces unités morphologiques se trouvent dans l’ordre indiqué ci-dessus le long d’une rivière, en commençant par la source et se terminant par son estuaire. Ainsi, les unités pool peuvent généralement être trouvées en amont (montagne) de la rivière, tandis que sand beds sont principalement présents dans les sections de rivière les moins profondes, à proximité des estuaires ou des confluents. Notez qu’il y a de nombreuses autres unités morphologiques en plus, telles que les eaux de relâche, les scalles, ou les bars Wyrick & Pasternack, 2014. Fig. Figure 1 illustre certaines unités morphologiques des rivières naturelles proches du Census.

Figure 1:a) Un cours d’eau d’amont colluvial (Furtschaglbach, Autriche), b) un cours d’eau en cascade (Torrent des Favrands, France), c) un cours d’eau rocheux (Anse St-Jean, Québec, Canada), d) un cours d’eau à pool à pas (Dessoubre, France), e) un cours d’eau à lit plat (Dranse, Suisse), f) un cours d’eau à pool à rafales (Le Diable, Québec, Canada), g) un cours d’eau tressé (Jenbach, Allemagne). Source : Schwindt (2017)
To guide restoration actions, experts often visually classify morphology units on-site, though some of them may also be distinguishable on aerial imagery. On-site (in-situ) expert assessments may also serve as ground truth for machine learning models. In this exercise, we will use hydrodynamic parameters with expert-based ground truth from the database https://
Prétraitement¶
Charger les données¶
We downloaded a dataset from https://
Chaque échantillon provient des sections de 146 rivières différentes du monde.
L’ensemble de données englobe le transport hydraulique et sédimentaire (p. ex., granulométrie) bien que dans ce tutoriel, nous n’utilisons que les paramètres suivants pour former le modèle SVM :
W: Largeur du chenal (m)
S: pente du chenal (m)
Q : Décharge (m s)
U: Vitesse de débit en vrac (m s)
H: Profondeur d ’ eau (m)
Dans un contexte d’apprentissage automatique, ces paramètres pour prédire les unités morphologiques sont également appelés caractéristiques. La première étape consiste à charger (et afficher) les données sous la forme d’un pandas.DataFrame:
import pandas as pd
data= pd.read_csv("data/bedload_dataset")
dataNettoyer l’ensemble de données¶
Pour éviter que le modèle SVM ne soit affecté par des statiques faites sur la base d’entrées absurdes (p. ex., valeurs de Not-a-Number NaN) ou de valeurs extrêmes aberrantes, par exemple, résultant de la typographie, nous ferons appliquer certaines méthodes de nettoyage.
Supprimer les valeurs de NaN¶
La première étape de nettoyage est d’enlever les NaN qui peuvent conduire le modèle SVM plus tard à faire de mauvaises conclusions.
# dataset essencial info
print(data.info(),"\n")
# remove rows that contains at least one NaN value
print(data.dropna(inplace=True))
# verify that all NaN values were removed
for column in data.columns.to_list():
print(column,":",data[column].isnull().any())
# verify final shape of the dataset
print(data.shape)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1067 entries, 0 to 1066
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 W 1067 non-null float64
1 S 1067 non-null float64
2 Q 1067 non-null float64
3 U 1067 non-null float64
4 H 1067 non-null float64
5 Morphology 1067 non-null object
dtypes: float64(5), object(1)
memory usage: 50.1+ KB
None
None
W : False
S : False
Q : False
U : False
H : False
Morphology : False
(1067, 6)
Recherches hors normes¶
Des aberrations peuvent se produire dans un environnement extrême ou dans des conditions extrêmes (p. ex. précipitations intenses), mais certaines d’entre elles sont aussi dues à des pannes d’équipement qui affecteront les performances du modèle SVM. Ainsi, la reconnaissance et la suppression de ces valeurs aberrantes liées aux dispositifs constituent une étape essentielle.
Visualiser les caractéristiques tracées dans un graphique scatter peut être utile pour repérer des candidats aberrants. Le bloc de code suivant crée des diagrammes de dispersion de chaque caractéristique, marque la valeur attendue, et la distance de 2 écarts-types (en supposant une distribution de type gaussien) de celle-ci.
from mpl_toolkits.axes_grid1 import host_subplot
import mpl_toolkits.axisartist as AA
import numpy as np
import matplotlib.pyplot as plt
# visualize scatter of the features
host = host_subplot(111, axes_class=AA.Axes)
plt.subplots_adjust(right=0.75)
# plot visualization parameters
labels = data.columns[0:5].tolist()
colors = ["crimson", "purple", "limegreen", "gold", "blue"]
width=0.5
# iterate on features of the dataset (i.e. column names)
for i, l in enumerate(labels):
if i ==0:
ax = host
ax.set_ylabel(labels[i])
else:
ax = host.twinx()
new_fixed_axis = ax.get_grid_helper().new_fixed_axis
ax.axis["right"] = new_fixed_axis(loc="right",
axes=ax,
offset=(60*(i-1), 0))
ax.axis["right"].toggle(all=True)
ax.set_ylabel(labels[i])
x = np.ones(data.shape[0])*i + (np.random.rand(data.shape[0])*width-width/2.)
ax.scatter(x, data[data.columns[i]],color=colors[i])
mean = data[f"{data.columns[i]}"].mean()
std = np.std(data[data.columns[i]])
ax.plot([i-width/2., i+width/2.], [mean, mean], color="k")
ax.plot([i,i], [mean-2*std, mean+2*std], color="k")
ax.set_xticks(range(len(labels)))
ax.set_xticklabels(labels)
plt.draw()
plt.show()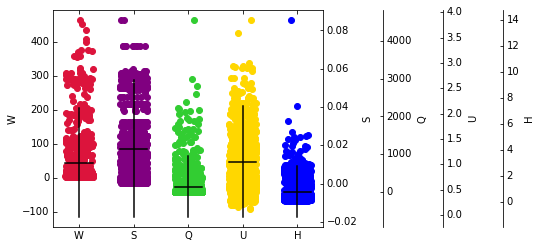
Supprimer les valeurs aberrantes¶
Les valeurs aberrantes peuvent être supprimées avec deux méthodes différentes:
Manuel (c.-à-d. jugement d’expert): identifier les aberrations des caractéristiques et les supprimer en fixant des limites de leur intervalle.
Automatisation : supposez une distribution de probabilité et fixez des limites en fonction de la faible probabilité d’occurrence de l’observation.
Les blocs de code suivants implémentent ces deux options (manuel-expert et méthode automatisée). La suppression manuelle aberrante est hard codée car les limites doivent être données par des experts.
L’approche automatisée (au-dessous de l’énoncé) suppose que les données ayant une distribution gaussienne, où les points avec une soi-disant z-score supérieure à 4 (quatre) sont supprimés. Les points de données ayant un score en z inférieur ou égal à quatre ont une chance de 99,9 % d’être à l’intérieur d’un intervalle de quatre écarts types éloignés de la valeur prévue. Ainsi, un échantillon ayant une chance d’occurrence de 0,01 % est automatiquement considéré comme un échantillon aberrant et retiré de l’ensemble de données. Ainsi, dans ce cas, le z-score représente l’écart type, et nous utilisons la fonction zscore de la bibliothèque scipy.
from scipy.stats import zscore
# choose the method to remove outliers
# remove_method = "expert_analysis"
remove_method = "zscore"
if "expert" in remove_method:
data = data.loc[(data["qs"]<0.02) &
(data["Q"]<2000) &
(data["W"]<250)]
else:
data = data[(np.abs(zscore(data.loc[:,data.columns!="Morphology"])) < 4).all(axis=1)]
dataVérifier les proportions des classes¶
Un modèle d’apprentissage automatique exige que les données de vérité au sol soient conformes à certaines normes de qualité. Celles-ci concernent (entre autres):
Chaque combinaison de modèles a besoin d’un nombre minimum d’échantillons différent pour avoir une signification statistique](Statistical significance). Il n’est pas trivial d’identifier le nombre minimum d’échantillons qui donnent un modèle digne de confiance. Cependant, pour représenter correctement une classe (quel que soit le sens), la soi-disant distribution de fréquence de chaque fonction doit être similaire à la distribution de fréquence.
Avoir plus de 30 samples lorsqu’il s’agit de variables normalement distribuées est une règle de bonne pratique.
Idéalement, les classes utilisées pour un problème de classification devraient être représentées par une quantité similaire d’échantillons. Un ensemble de données déséquilibré peut produire un modèle qui donne la préférence à une classification correcte de la classe avec un plus grand nombre d’échantillons. Ceci est une conséquence de l’utilisation de la précision comme mesure de performance. L’exactitude est le rapport entre les prévisions correctes et le nombre total de prévisions (). En préférant le nombre total de prédictions correctes à un nombre équilibré, la précision masque l’importance d’obtenir correctement les classes sous-représentées.
Les solutions pour équilibrer les échantillons déséquilibrés englobent :
Collecte ou production de nouvelles données (p. ex., méthodes Monte Carlo). Si disponible, précision est préférable pour la mesure de la forme du modèle (au lieu de précision).
Weighting class features, qui signifie attribuer des poids pour augmenter l’importance des classes sous-représentées correctement. Dans le cas des problèmes de classification, l’essai de différentes combinaisons de poids donne une courbe de ROC, qui montre l’effet de divers poids sur les performances du modèle.
Dans ce tutoriel, les échantillons peuvent être considérés comme équilibrés, sauf pour la classe de lit de sable (voir la sortie ci-dessous). La pondération et les courbes ROC ne sont pas considérées ici. Si la sensibilité et la spécification de la classe de banc de sable étaient acceptables lors de la classification des données d’essai, le modèle pourrait également être utilisé pour la classification des bancs de sable sans avoir à utiliser de techniques d’équilibrage.
data["Morphology"].value_counts()Step-pool 247
Plane Bed 243
Riffle-pool 241
Braiding 228
Sand bed 79
Name: Morphology, dtype: int64Nouveaux prédicteurs dérivés¶
Il est parfois possible de calculer de nouvelles fonctionnalités significatives à partir des fonctionnalités existantes. Par exemple, les prédicteurs connus de la morphologie sont :
le produit de la pente (énergie) (-), la vitesse de débit en vrac (m/s) et la profondeur d’eau (m), qui représente essentiellement shear stress
the ratio of discharge (m/s) and width (m) (i.e., Q/W)
import warnings
from pandas.core.common import SettingWithCopyWarning
warnings.simplefilter(action="ignore", category=SettingWithCopyWarning)
# compute new columns for the new features SUH and Q/W
data["SUH"] = (data.loc[:,"S"]*data.loc[:,"U"]*data.loc[:,"H"])
data["Q/W"] = (data.loc[:,"Q"]/data.loc[:,"W"])
dataVérifier la multicolinéarité¶
Des caractéristiques connexes (c.-à-d. des paramètres de mesure statistiquement dépendants) peuvent donner lieu à des modèles peu fiables. Par exemple, considérez un scientifique qui veut utiliser des modèles d’apprentissage automatique (ML) pour prédire le nombre de touristes qui sont brûlés au soleil au Brésil pendant leurs vacances. Elle veut utiliser l’intensité du rayonnement solaire et le nombre de boules de glace vendues en tant que caractéristiques. Le scientifique peut trouver que les deux caractéristiques sont pertinentes pour prédire le nombre de touristes brûlés au soleil, mais la raison de cette constatation est que le nombre de scoops de crème glacée vendus, et l’intensité du soleil sont corrélées. Ainsi, le scientifique n’a aucun moyen de savoir quelle est l’importance réelle de chaque caractéristique dans la prédiction des touristes brûlés au soleil parce que les caractéristiques croissent et diminuent simultanément. D’ailleurs, la consommation de glaces et les brûlures de soleil n’ont aucune causalité en commun, mais c’est un autre sujet.
À cette fin, il est important d’étudier la corrélation entre les caractéristiques et d’envisager d’éliminer celles-ci pour produire un modèle plus fiable. Une façon de repérer visuellement la colinéarité est de tracer la combinaison de deux variables dans un graphique de dispersion. À cette fin, la figure ci-dessous aide à repérer les aspects suivants de la bedload_dataset:
Il y a une forte corrélation linéaire entre les fonctionnalités et .
Il n’y a pas de corrélation linéaire entre et .
La vitesse d’écoulement distribuiton est approximativement normale (voir diagonale principale).
import seaborn as sns
# plot scatter of the 2d (two dimensinal) combination of features
sns.pairplot(data.loc[:,data.columns!="Morphology"])
plt.show()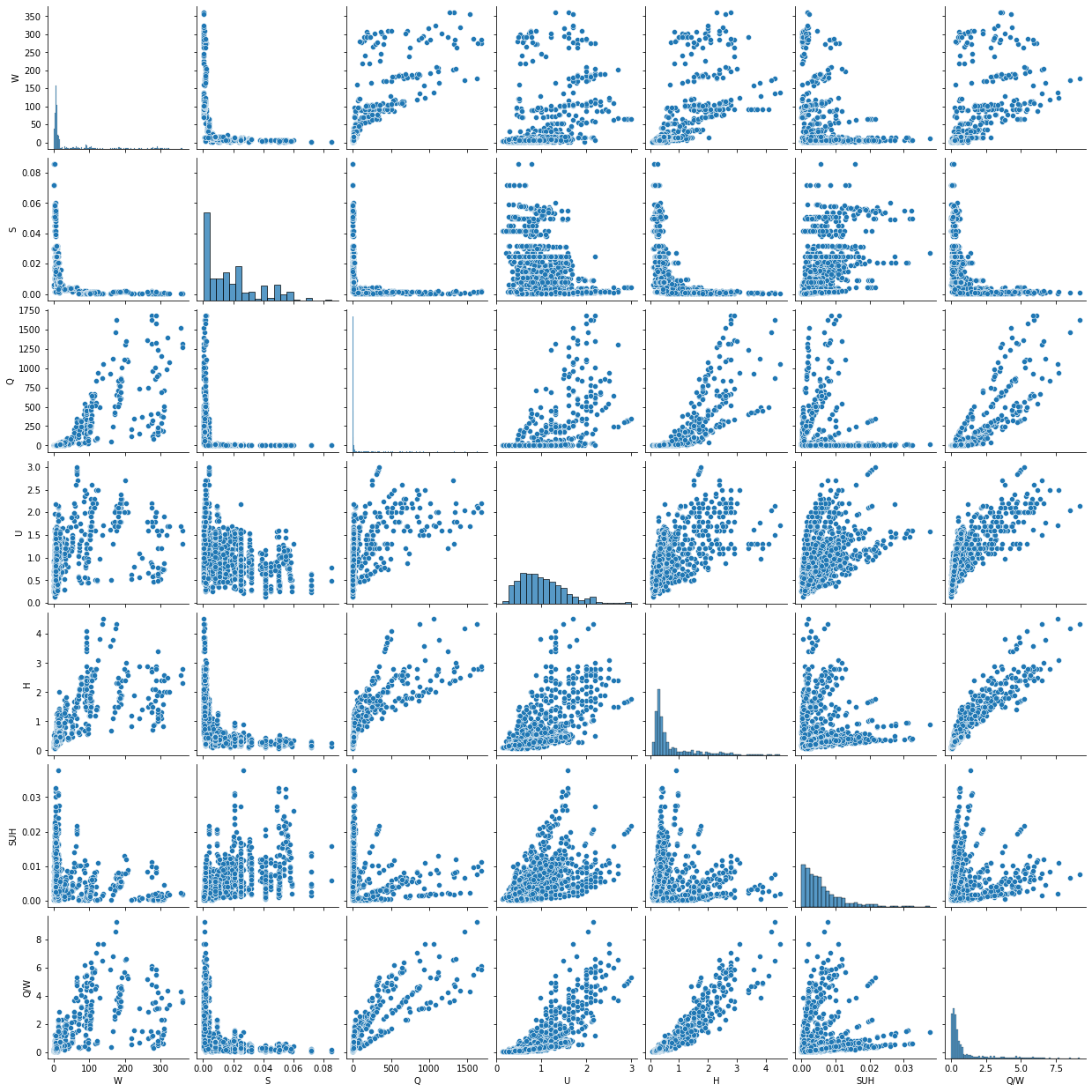
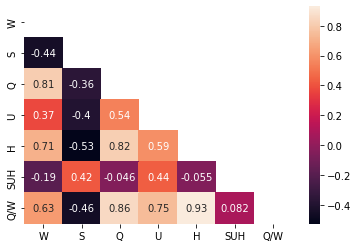
De plus, une heatmap est une autre méthode efficace pour visualiser la corrélation linéaire entre les caractéristiques. De plus, le calcul de correspondance linéaire permet une analyse quantitative.
from seaborn import heatmap
# verify linear coorralation
feature_corr_df = data.loc[:,data.columns!="Morphology"].corr()
mask = np.zeros_like(feature_corr_df)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(feature_corr_df,
annot=True, # print value inside the grid
mask=mask # mask values (boolean matrix)
)
Facteur d’inflation des écarts (FIV)¶
Une méthode simple pour évaluer multicollinerity est le calcul du facteur d’inflation de variation (VIF) pour chaque caractéristique, ce qui quantifie la corrélation entre les caractéristiques.
La première étape pour calculer le FIV est de traiter une fonctionnalité comme une variable dépendante](https://www.scribbr.com/methodology/independent-and-dependent-variables/#:~:text=The independent variable is the,changes in the independent variable.) et d’adapter un modèle de régression linéaire en utilisant les autres fonctionnalités comme une variable indépendante](https://www.scribbr.com/methodology/independent-and-dependent-variables/#:~:text=The independent variable is the,changes in the independent variable.). Deuxièmement, entreposez les erreurs carrées moyennes correspondantes produites par le modèle linéaire.
Enfin, le FIV peut être calculé pour chaque caractéristique par l’équation suivante:
est le facteur d’inflation de la fonction , et
est l’erreur carrée moyenne résultant de la régression linéaire de la fonction .
Notez que plus le MSE (meilleur modèle de régression linéaire) est petit, plus l’inflation est grande. En d’autres termes, les grandes valeurs de la FIV indiquent une corrélation élevée entre la caractéristique considérée et l’une des autres caractéristiques. Néanmoins, il n’est pas possible de dire sur la base de VIF seulement, qui autre fonctionnalité fait gonfler VIF.
En règle générale, un VIF supérieur à 10 (dix) indique un ensemble de caractéristiques inappropriées pour produire un modèle ML fiable. Idéalement, le FIV devrait rester inférieur à 5 (cinq), ce qui est considéré comme une corrélation modérée Franke, 2010. Toutefois, ces valeurs de référence ne sont pas une règle générale et toujours applicable. VIF égal ou supérieur à 10 peut encore donner un bon modèle.
Une analyse plus approfondie pour étudier l’impact d’un FIV élevé sur les caractéristiques corrélées peut être effectuée en supprimant chaque caractéristique à la fois et en étudiant comment la suppression de la fonctionnalité affecte la variation de erreur standard et p-value du modèle.
Dans ce tutoriel, 2 fonctionnalités ont un VIF 10 (notamment, et ), comme l’indique le bloc de code suivant.
from sklearn.linear_model import LinearRegression
# compute VIF for the features
def calculate_vif(df, features):
vif, tolerance = {}, {}
for feature in features:
# extract all the other features you will regress against
X = [f for f in features if f != feature]
X, y = df[X], df[feature]
# extract r-squared from the fit
r2 = LinearRegression().fit(X, y).score(X, y)
# compute VIF
vif[feature] = 1 / (1 - r2)
# return VIF DataFrame
return pd.DataFrame({'VIF': vif})
# call fuction calculate_vif with features as input
calculate_vif(df=data,
features=data.columns[data.columns != "Morphology"].to_list())Supprimer les fonctionnalités pour réduire la FIV¶
Dans le but de réduire les FIV à moins de 5, nous utilisons une approche d’essai et d’erreur dans ce tutoriel. Modifier le bloc de code ci-dessous montre que supprimer et est suffisant pour réduire les FIV des fonctionnalités restantes à moins de 5. En particulier, ces deux variables supprimées entrent également dans les fonctionnalités ci-dessus introduites et . Ainsi, bien que et soient supprimés, ils continuent de “contribuer l’information” au modèle final.
La combinaison de caractéristiques corrélées pour en produire une nouvelle, puis pour les éliminer, est une approche commune pour réduire les FIV. Puisque nous avons obtenu de bonnes valeurs VIF en supprimant certaines caractéristiques, aucune analyse supplémentaire n’est nécessaire.
Enfin, les caractéristiques qui sont utilisées pour former et tester le modèle SVM sont indiquées par la sortie du bloc de code ci-dessous.
# try and error approach removing features get VIFs < 10
data = data.loc[:, data.columns[(data.columns !="H")&
(data.columns !="Q")
]
]
# compute VIF again to verify if VIFs are less than 5
calculate_vif(df=data,
features=data.columns[data.columns != "Morphology"].to_list())Séparer les ensembles de données des tests et de la formation¶
La dernière étape de préparation à la construction du modèle SVM est de tirer une formation et un ensemble de données d’essai de l’ensemble bedload_dataset. Choisir une part de données pour composer une formation et un ensemble de données de test est généralement un choix heuristique. Ici, nous utilisons 33 % des données pour tester une hypothèse finale plus tard. Notez que dans les ensembles de données fractionnés, l’index des échantillons (lignes des données tabulaires) a leur classe correspondante à l’intérieur des ensembles de données cible .
from sklearn.model_selection import train_test_split
# split dataframes with features and labels only
labels = data.loc[:, "Morphology"]
predictors = data.loc[:, data.columns[data.columns != "Morphology"]]
# split testing set as 33% of the data
# X correspond to the featues (matrix form)
# y corresponf to the labels (vector form)
X_train, X_test, y_train, y_test = train_test_split(predictors,
labels,
test_size=0.3,
random_state=42 # seed for random selection of data
)
# visualize training and testing sets
print("TRAINING DATASET PREDICTORS")
print(X_train.head(), "\n")
print("dataframe size", X_train.shape,"\n")
print("------------------------------------------")
print("TRAINING DATASET TARGET")
print(y_train,"\n")
print()
print("------------------------------------------------------------------------------------\n")
print("TESTING DATASET PREDICTORS")
print(X_test.head())
print("dataframe size", X_test.shape,"\n")
print("------------------------------------------")
print("TESTING DATASET TARGET")
print(y_test.head())
print("Vector size", y_test.shape)
TRAINING DATASET PREDICTORS
W S U SUH Q/W
256 6.91 0.01100 1.02 0.003366 0.277858
397 88.09 0.00210 1.99 0.008149 3.889545
586 14.02 0.02070 1.34 0.022190 1.078459
526 218.00 0.00041 0.52 0.000175 0.541284
9 8.00 0.02000 1.18 0.007316 0.370000
dataframe size (726, 5)
------------------------------------------
TRAINING DATASET TARGET
256 Plane Bed
397 Plane Bed
586 Step-pool
526 Sand bed
9 Riffle-pool
...
89 Riffle-pool
337 Plane Bed
476 Plane Bed
123 Riffle-pool
876 Braiding
Name: Morphology, Length: 726, dtype: object
------------------------------------------------------------------------------------
TESTING DATASET PREDICTORS
W S U SUH Q/W
203 2.57 0.01040 1.58 0.008216 0.793774
937 105.00 0.00096 1.90 0.002918 3.076190
546 93.00 0.00050 1.10 0.001320 2.688172
214 53.04 0.00380 1.44 0.004596 1.211916
312 6.28 0.02020 0.34 0.001511 0.074841
dataframe size (312, 5)
------------------------------------------
TESTING DATASET TARGET
203 Riffle-pool
937 Braiding
546 Sand bed
214 Riffle-pool
312 Plane Bed
Name: Morphology, dtype: object
Vector size (312,)
Construire le modèle SVM¶
Principe de travail¶
Une machine vectorielle de soutien (SVM) est un algorithme d’apprentissage qui recherche un soi-disant hyperplan qui sépare de façon optimale les classes de fonctionnalités. Pour trouver une séparation optimale, l’algorithme essaie de maximiser la distance (ou la marge) entre l’hyperplan et les points de données les plus proches. Les points de données proches des limites de la marge sont également appelés « vecteurs de soutien »** parce qu’ils servent de référence à draw l’hyperplan (voir fig. Figure 2 ci-dessous).
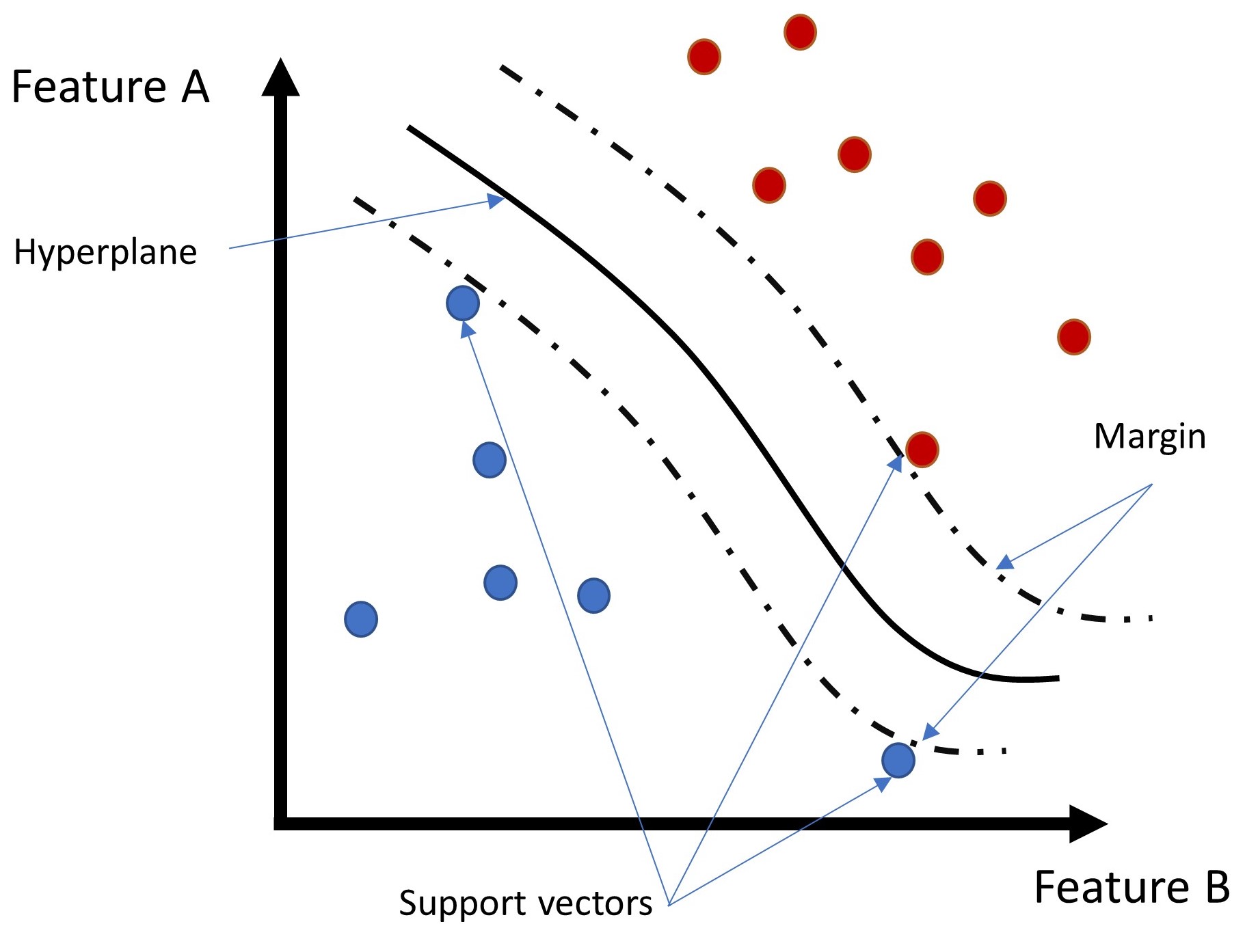
Figure 2:Illustration d’un hyperplan et marges d’un SVM. Source: Ricardo Barros
Par exemple, supposons que deux des classes ci-dessus sont linéairement séparables. Nous pouvons définir les régions qui contiennent chaque classe au moyen de l’hyperplan suivant:
--> Class Red , et --> Class Blue
où
est le vecteur des poids,
est la matrice des caractéristiques,
est la variable indépendante (également appelée bias), et
la valeur de 1 est choisie comme une simplification représentative, puisque peut être n’importe quelle valeur.
Enfin (après quelques étapes qui ne sont pas discutées ici), nous pouvons calculer un hyperplan optimal en minimisant l’expression suivante:
où est le vecteur de poids transposé.
Dans le monde réel, cependant, il est courant de trouver des problèmes où les classes ne sont pas linéairement séparables. Dans de telles situations, on peut appliquer ce qu’on appelle les kernels. Un noyau est une fonction qui transforme en une matrice aux dimensions supérieures en combinant les fonctionnalités disponibles pour créer de nouvelles fonctionnalités (c.-à-d. de nouvelles dimensions).
Ici, nous appliquons le noyau Radius Base Function (RBF). Le RBF est un noyau populaire parce qu’il transforme le en une matrice de dimensions infinies sans risquer de suradapter le modèle.
Validation croisée k-fold¶
Les SVM composés d’un noyau RBF peuvent être validés en harmonisant deux paramètres:
C : détermine le montant des marges permissives. Il différencie entre une marge ** dure** (c’est-à-dire une marge qui permet une faible ou aucune pénétration des points de données) et une marge ** molle** (c’est-à-dire une marge qui permet la pénétration des points de données à l’intérieur de la marge). Un C supérieur correspond à une marge plus dure.
gamma : détermine la région de similitude entre les échantillons. C’est la seule variable du noyau RBF. Plus le gamma est élevé, plus l’influence d’un échantillon étiqueté sur la classification d’un nouvel échantillon est grande.
Les marges dures peuvent également être interprétées comme la sensibilité de l’hyperplan lorsqu’on les adapte aux données. Plus la marge est dure, plus l’hyperplane tourne pour ne permettre à aucun point de données de pénétrer la marge.
Dans ce tutoriel, nous définissons C sur la base d’une approche d’essai et d’erreur et d’un gamma provenant d’une validation croisée. Le bloc de code suivant construit le SVM en utilisant la bibliothèque sklearn, et imprime les courbes d’erreur de validation et de formation résultant de différentes gamma .
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
# define C, gamma range, kernel and number of cross-val. folds
gamma_range = np.logspace(-5, 3, 13)
C=500 # chosen hyperparameter through tunnig
kernel = "rbf" # radius base function
n_of_folds = 5
# Peform 5-fold cross-validation and save training and validation error
train_scores, test_scores = validation_curve(SVC(kernel=kernel,
C=C),
X_train,
y_train,
param_name="gamma",
param_range=gamma_range,
scoring="accuracy",
cv=n_of_folds
)
# convert accuracy into error
train_error = 1-train_scores
validation_error = 1-test_scores
# compute 5-fold cross-validation mean and std of error
train_error_mean = np.mean(train_error, axis=1)
train_error_std = np.std(train_error, axis=1)
validation_error_mean = np.mean(validation_error, axis=1)
validation_error_std = np.std(validation_error, axis=1)
#-------------------------------------------------------------------
# visualization of training and error validation
plt.title("Validation Curve with SVM")
plt.xlabel(r"$\gamma$")
plt.ylabel("Error (1-accuracy)")
plt.ylim(-0.01, 1.1)
lw = 2
plt.semilogx(
param_range, train_error_mean, label="Training error", color="darkorange", lw=lw
)
plt.fill_between(
param_range,
train_error_mean - train_error_std,
train_error_mean + train_error_std,
alpha=0.2,
color="darkorange",
lw=lw,
)
plt.semilogx(
param_range, validation_error_mean, label="Cross-validation error", color="navy", lw=lw
)
plt.fill_between(
param_range,
validation_error_mean - validation_error_std,
validation_error_mean + validation_error_std,
alpha=0.2,
color="navy",
lw=lw,
)
plt.legend(loc="best")
plt.show()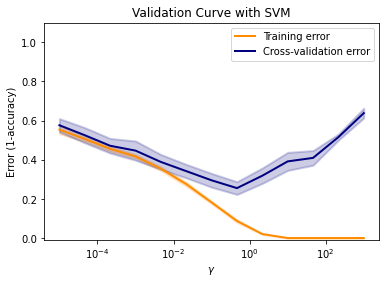
Sélectionner les paramètres optimum¶
La décision sur les paramètres optimaux pour le SVM dépend de votre avis. Aux fins de la sélection des paramètres optimaux dans ce tutoriel, le bloc de code ci-dessous quantifie le tracé ci-dessus (en particulier la courbe bleue) sous forme de tableau et enregistre le gamma qui produit la plus petite erreur ( gamma opt ).
# save optimal gamma
index_min = min(range(len(validation_error_mean)), key=validation_error_mean.__getitem__)
validation_error_min = validation_error_mean[index_min]
gamma_opt = param_range[index_min] # gamma that gives minimun validation error
# visualize error evolution with gamma
columns = ["Mean validation error","gamma"]
array = np.array([validation_error_mean, param_range]).transpose()
print( pd.DataFrame(array,columns=columns), "\n")
print("Minimun mean validation error:", validation_error_min)
print("optimal gamma:", gamma_opt) Mean validation error gamma
0 0.575739 0.000010
1 0.524856 0.000046
2 0.471101 0.000215
3 0.446311 0.001000
4 0.388474 0.004642
5 0.341606 0.021544
6 0.294709 0.100000
7 0.254861 0.464159
8 0.318262 2.154435
9 0.391252 10.000000
10 0.409173 46.415888
11 0.515144 215.443469
12 0.637789 1000.000000
Minimun mean validation error: 0.2548606518658479
optimal gamma: 0.46415888336127725
Modèle SVM d’hypothèse optimale du train¶
Après avoir défini un gamma donnant la plus petite erreur de validation ( gamma opt ), nous pouvons former une hypothèse optimale ( h opt ) sur l’ensemble des données de formation. En outre, nous pouvons évaluer la précision du modèle en l’utilisant pour classifier l’ensemble de données de test. Le bloc de code ci-dessous présente la procédure d’entraînement, l’ajustement du SVM (c.-à-d. une hypothèse optimale) et imprime le score de l’hypothèse optimale.
# train optimal model and evaluate accuracy
h_opt = SVC(kernel=kernel,
gamma=gamma_opt,
C=C) # instantiate optimal model
h_opt.fit(X_train,y_train) # train the model with entire training set
print("Error (1-Accuracy) of h_opt on testing data: \n -->>",1- h_opt.score(X_test,y_test)) Error (1-Accuracy) of h_opt on testing data:
-->> 0.19551282051282048
Évaluation du rendement (Matrice de confusion)¶
Enfin, le bloc de code suivant génère la soi-disant matrice confusion pour évaluer la performance optimale du modèle d’hypothèse lors de la classification des échantillons avec des morphologies distinctes. La matrice de confusion utilise le nombre total d’échantillons et visualise leurs unités morphologiques vraies et prédites.
from sklearn.metrics import plot_confusion_matrix
#plot confusion matrix
plot_confusion_matrix(h_opt, # trained optimal hypothesis model
X_test,
y_test,
)
plt.xticks(rotation=45)
plt.show()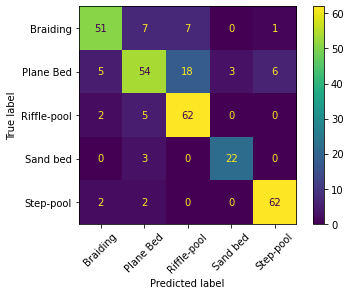
La matrice de confusion d’un modèle exact n’a que des entrées diagonales supérieures à zéro, alors que toutes les autres sont nulles. Ainsi, la matrice de confusion ci-dessus montrée montre que notre modèle SVM fonctionne très bien pour prédire les morphologies des fosses à pas et des fosses à rapides, mais prédit de façon irréprochable les morphologies des lits de sable en raison de peu d’observations. Cependant, le modèle a également fait de fausses prédictions sur les caractéristiques du pool à pas et du pool à truffes. Par exemple, selon la matrice de confusion, le modèle prédit 6 fois pas-pool, où en réalité (vraie étiquette), les unités morphologiques planes lit, et il prédit à tort qu’une observation tressée est une observation pas-pool. Les prédictions du lit de sable ne sont pas fiables parce qu’il n’y a que 25 observations du lit de sable (supposées à 66 observations du puits). Ainsi, les observations du lit de sable sont déséquilibrées et une solution pour éliminer l’infiabilité pourrait être d’échantillonner plus d’unités morphologiques du lit de sable (comme expliqué ci-dessus).
- Montgomery, D. R., & Buffington, J. (1997). Channel-reach morphology in mountain drainage basins. Geological Society of America Bulletin, 109(5), 596–611. https://doi.org/10.1130/0016-7606(1997)109<;0596:CRMIMD>2.3.CO;2
- Recking, A., Piton, G., Vazquez-Tarrio, D., & Parker, G. (2016). Quantifying the morphological print of bedload transport. Earth Surface Processes and Landforms, 41(6), 809–822.
- Wyrick, J. R., & Pasternack, G. B. (2014). Geospatial organization of fluvial landforms in a gravel-cobble river: Beyond the riffle-pool couplet. Geomorphology, 213(Supplement C), 48–65. 10.1016/j.geomorph.2013.12.040
- Schwindt, S. (2017). Hydro-morphological processes through permeable sediment traps [Thesis No. 7655, Laboratory of Hydraulic Constructions (LCH), Ecole Polytechnique fédérale de Lausanne (EPFL)]. 10.5075/epfl-thesis-7655
- Franke, G. R. (2010). Multicollinearity. Wiley International Encyclopedia of Marketing.