Dans cette section, nous aborderons les concepts fondamentaux de classification non linéaire en introduisant le concept de noyaux. Tout d’abord, rappelons ce que nous avons vu jusqu’ici dans notre section sur Classement linéaire. Dans la classification linéaire, notre tâche consistait à classer les points de données à travers un hyperplan qui pourrait séparer linéairement l’ensemble de données dans l’espace de coordonnées des caractéristiques. Par exemple, dans un espace de fonctionnalités 3d, donc un vecteur de fonctionnalités comme (x1,x2,x3)∈R3, rappelez-vous que nos données sont considérées linéairement séparables s’il y a au moins un plan (pas une ligne) qui peut diviser les points. Contrairement à la classification linéaire, qui suppose une relation linéaire entre les caractéristiques d’entrée et les étiquettes de classe, les algorithmes de classification non linéaires utilisent diverses techniques pour saisir les modèles complexes et les limites de décision dans les données. En particulier, nous examinerons comment nous pouvons transformer nos données en un nouvel espace de coordination de dimension supérieure à travers kernels, qui nous aide à transformer le problème non linéaire en un problème linéaire.
Les noyaux nous permettent de transformer les données en un espace de caractéristiques de dimension supérieure où la séparation linéaire devient possible. Un exemple d’algorithme ML qui s’appuie sur des noyaux pour trouver le modèle complexe et les limites de décision dans les données est Support Vector Machine (SVM).
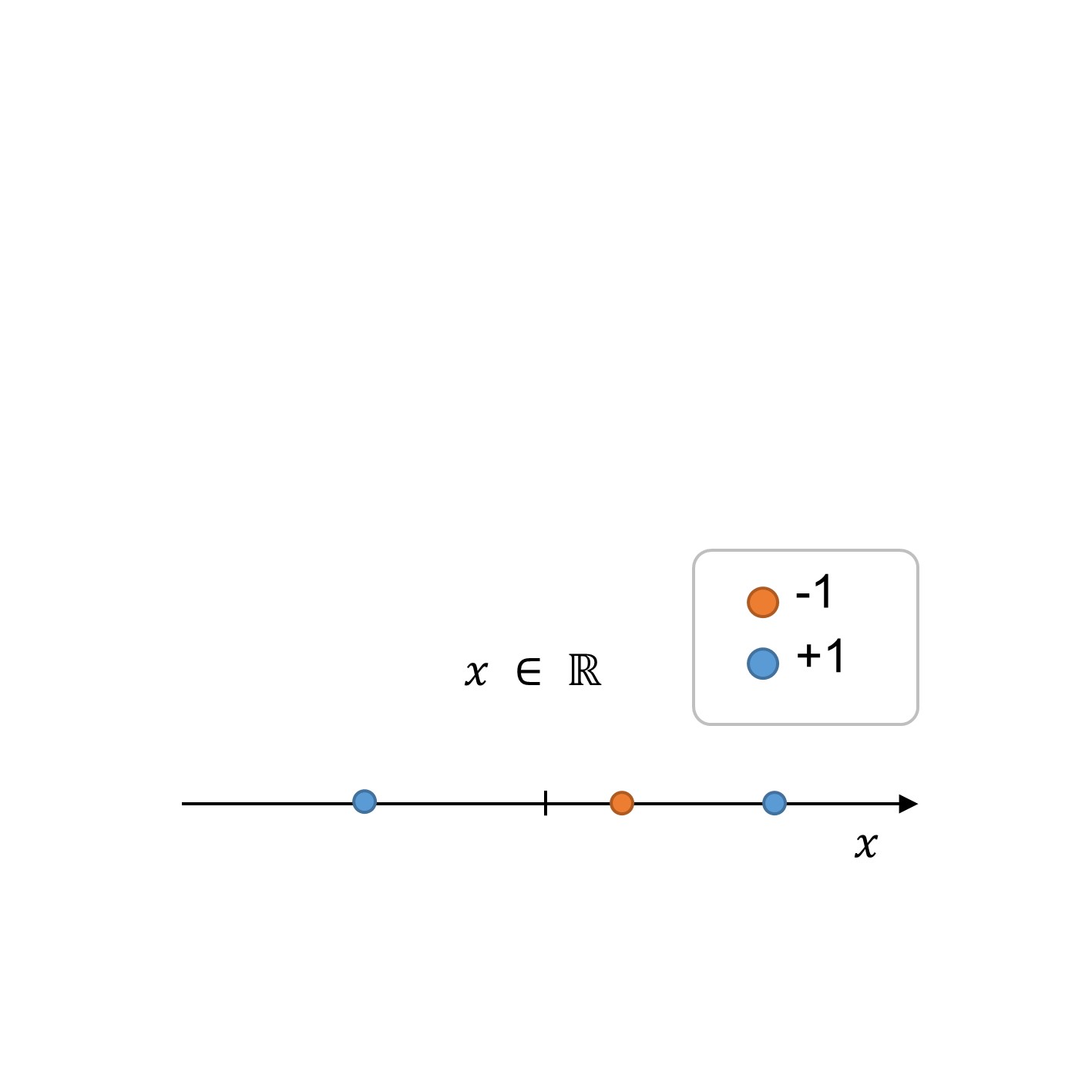
Nous allons maintenant voir comment la transformation des fonctionnalités fonctionne à travers un exemple 1d, c’est-à-dire, nous avons une fonctionnalité x∈R. La figure ci-dessous illustre les points de formation (n=3).
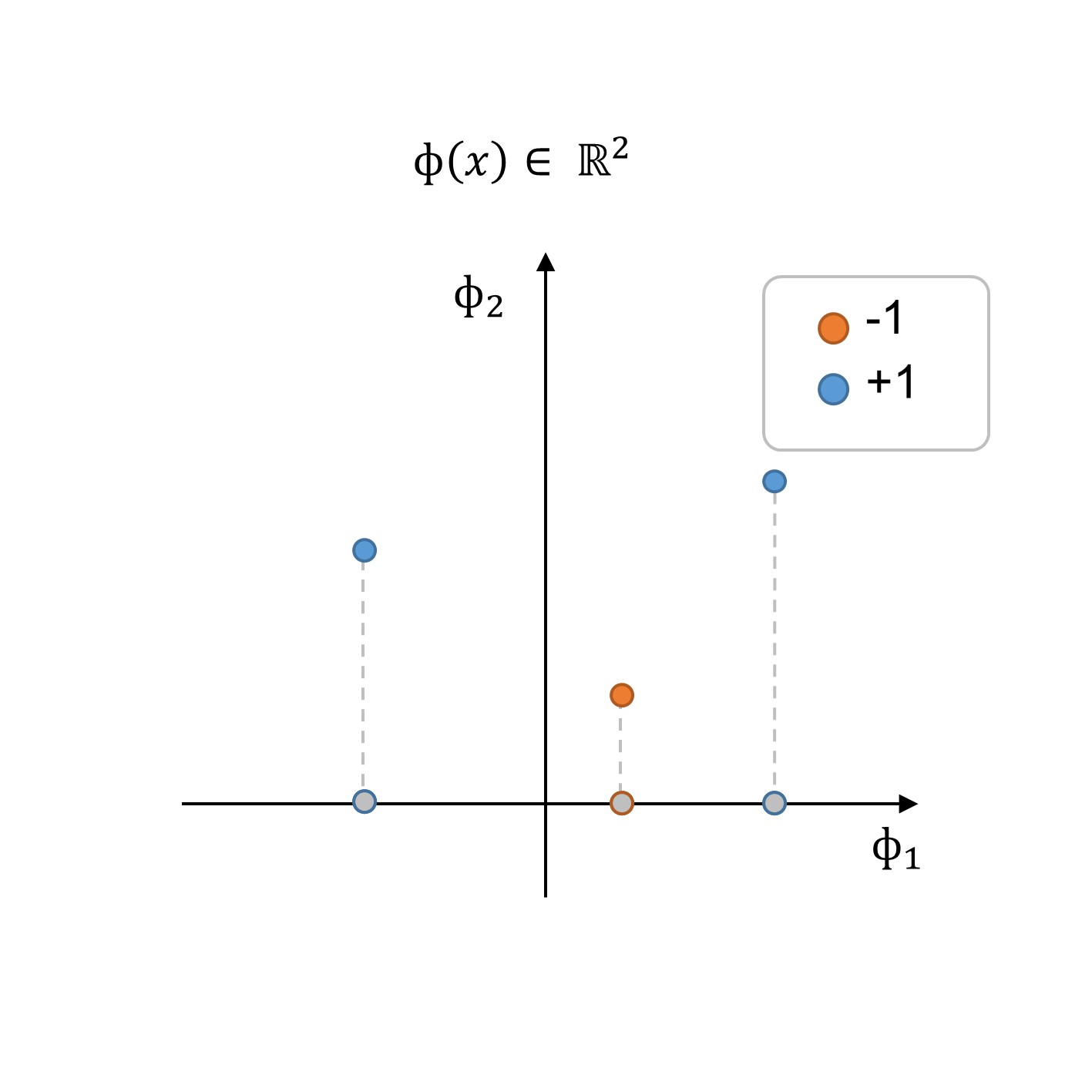
Noter à partir de la figure que l’ensemble de données n’est pas séparable linéairement, du moins pas dans l’espace de caractéristique donné dans une dimension. Pour transformer ce problème en problème linéaire, nous pouvons effectuer une transformation de fonctionnalités (ϕ(x)) pour rechercher une limite de décision dans un espace à dimension supérieure. Dans cet exemple particulier, notez que nous pouvons transformer la fonctionnalité 1d en un nouveau vecteur de fonctionnalités 2d, où la dimension supplémentaire peut être vue comme une sorte de nouvelle fonctionnalité.
Figure 1:1 : Formation des données dans l’espace initial.
Figure 2:2: Formation de données dans le nouvel espace de fonctionnalités Φ(x).
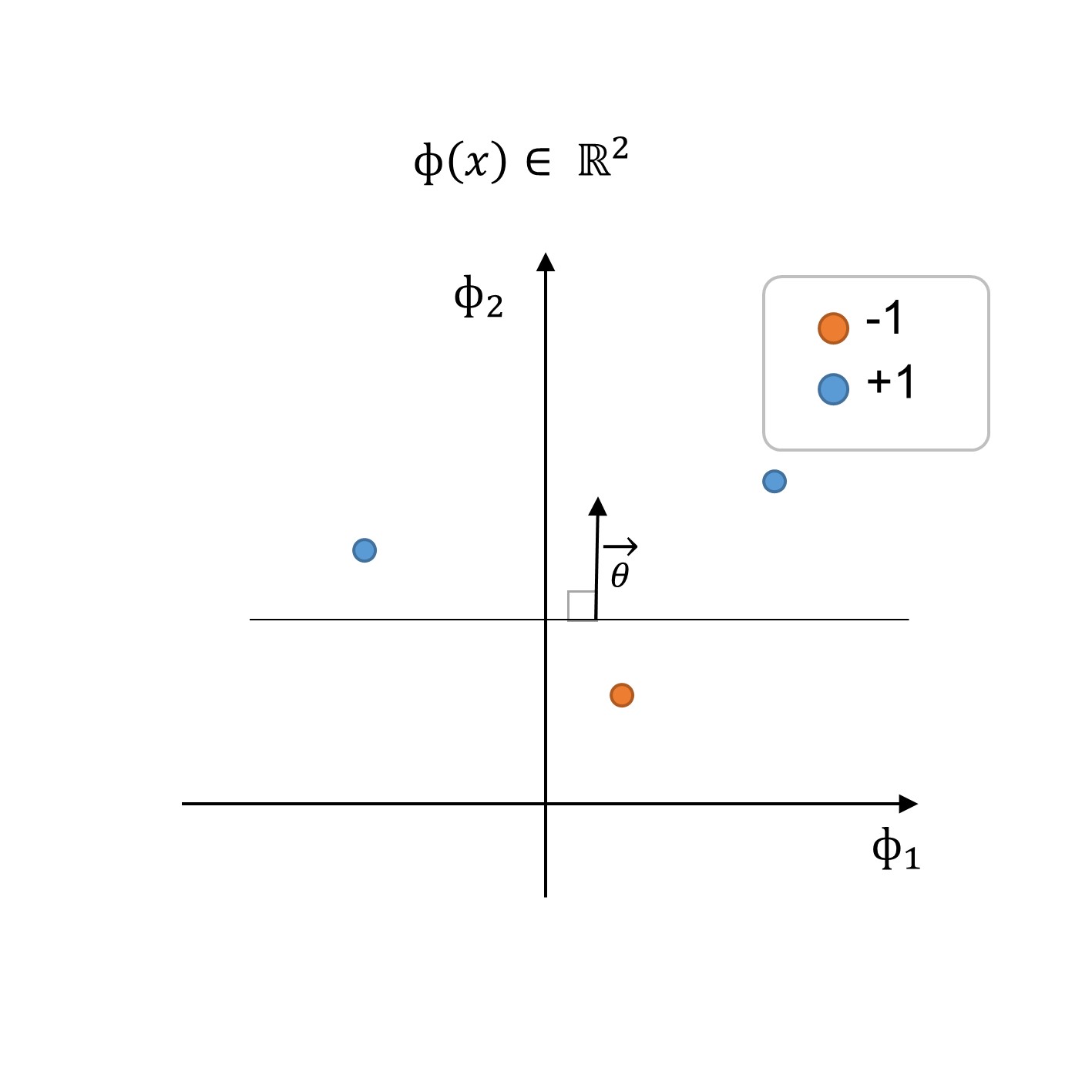
Figure 3:3: Ensemble de données de formation et limite de décision dans le nouvel espace de fonctionnalités Φ(x)
En effectuant la transformation des fonctionnalités comme l’illustre l’étape 2 : formation des données dans le nouvel espace de fonctionnalités Φ(x) (voir figure ci-dessus), nous pouvons trouver un classificateur h(x,θ,θo) avec une limite de décision définie par θ et le paramètre offset θ0 :