Classement linéaire¶
Dans cette section, nous aborderons les fondamentaux de la classification linéaire à travers un simple algorithme ML, le Perceptron. En outre, nous étendrons les concepts derrière l’algorithme de Perceptron en examinant des aspects de régularisation pour construire un classificateur linéaire de marge.
Hyperplans¶
Supposons que nous souhaitions classer les objets positifs et négatifs à partir de l’ensemble de points d’entraînement ci-dessous (figure à gauche):
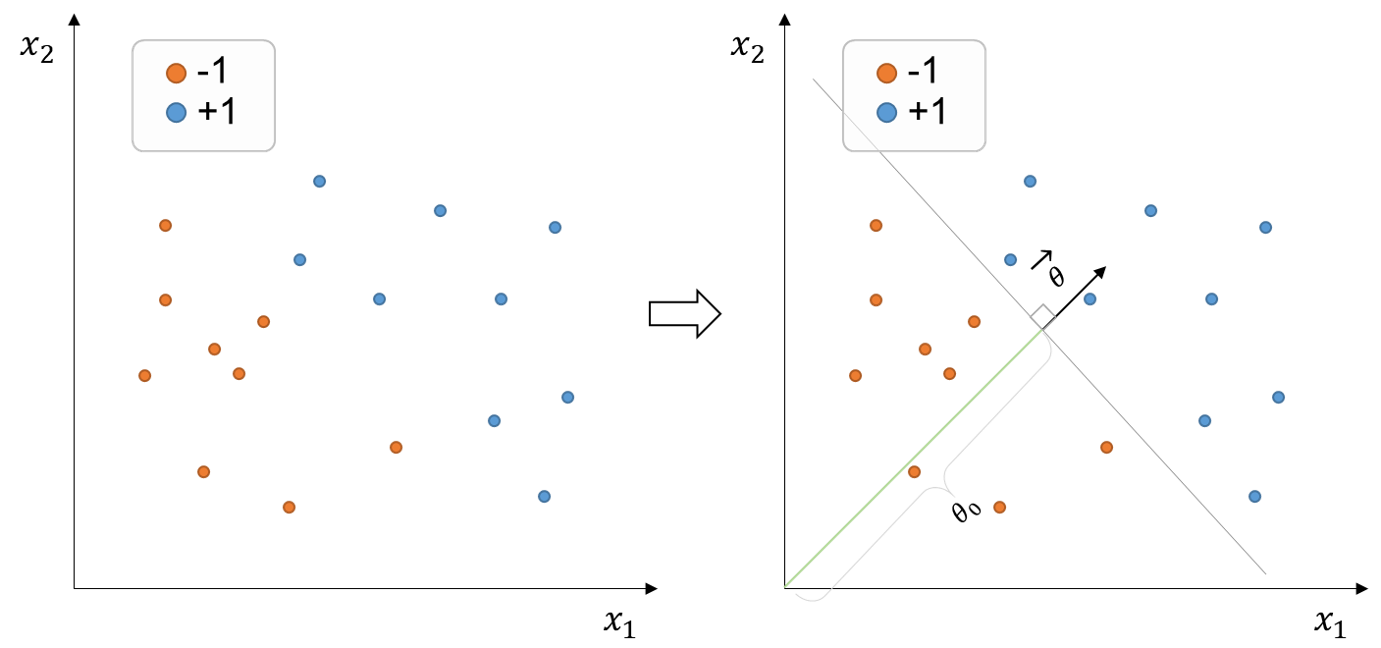
Figure 1:Ensemble de points de formation avec étiquettes binaires (+1, -1) et deux dimensions fonctionnalités. La limite de décision (ligne grise) est définie par le vecteur de paramètre , qui est normal à la limite de décision, et le paramètre offset qui sépare linéairement les données.
L’ensemble de données ci-dessus est considéré linéairement séparable parce qu’il existe au moins une limite de décision linéaire capable de diviser correctement l’ensemble de données. Par exemple, nous pourrions passer une limite de décision comme la ligne grise au-dessus (figure à droite)
Dans ce cas, puisque les fonctionnalités , c’est-à-dire que l’ensemble de fonctionnalités appartient à l’espace bidimensionnel, la limite de décision constitue une ligne. Si nous avions affaire à un ensemble de caractéristiques dans l’espace tridimensionnel , la limite de décision serait un plan. Pareillement, si notre ensemble de caractéristiques se trouvait dans un espace de dimension supérieure, la limite de décision constituerait un hyperplan.
Un hyperplan aux dimensions est habituellement indiqué par le vecteur normal du plan, , et le paramètre offset (scalar) . Dans l’exemple ci-dessus, nous définirions l’hyperplan (ou la limite de décision) comme suit :
Notre classificateur est donc égal à où et . Rappelez-vous que la fonction de signe, aussi appelée fonction de signe, est une fonction mathématique qui renvoie le signe ou la direction d’un nombre réel. C’est-à-dire que si le numéro d’entrée est positif, négatif ou 0, la fonction de signe retourne respectivement +1, -1 ou 0.
Algorithme de perceptron¶
Dans l’algorithme de perceptron, nous initialisons généralement comme zéro (vecteur zéro) et en boucle à travers la paire d’exemples de formation. À chaque itération, nous vérifierons si le classificateur fait une erreur en classifiant cet exemple de formation (i-ème exemple), et si oui, nous mettons à jour les paramètres de .
Supposons que pour la simplicité (la limite de décision doit passer par l’origine). Notre classificateur perceptron fera une erreur if . Nous mettrons alors à jour notre pour ne plus mal classifier cet exemple de formation. La façon de le faire est d’ajouter à la précédente . Ainsi, la mise à jour ressemblerait à:
Nous avons entre les mains un ensemble d’exemples de formation différents qui ont le potentiel de rafraîchir / mettre à jour notre classificateur dans de nombreuses directions. Ainsi, il est possible et même attendu que les derniers exemples de formation provoquent des mises à jour qui écraseront plus tôt, les mises à jour initiales. Il en résultera que les exemples précédents ne seront plus correctement classés. Pour cette raison, nous devons boucler l’ensemble de la formation ensemble multiple heures pour nous assurer que tous les exemples sont correctement classifiés. De telles itérations peuvent être effectuées dans l’ordre ou au hasard à partir des exemples de formation.
Nous pouvons coder l’algorithme comme suit:
import numpy as np
# Algorithm always starting to loop from x1
def perceptron(X, y, theta, t_times):
n_mistakes = 0
# Initialize list to show the progress (updates) of theta
progress_theta = []
# Initialize an array with same size as the total number of examples to count how many mistake are made at each training example
explicit_mistakes = np.zeros(shape=y.shape[0])
# Loop through the training set T times
for t in t_times:
# Loop through the training examples in order
for index, x in enumerate(X):
# Check if the algorithm makes a mistake in the i-th (or index-th) example
if y[index] * np.dot(theta, x) <= 0:
# Update theta to no longer misclassify the i-th example
theta = theta + y[index] * x
# Save the update theta
progress_theta.append(theta)
# Update total number of mistakes
n_mistakes += 1
# Update total number of mistakes at the i-th training example
explicit_mistakes[index] += 1
print('The perceptron did {} mistakes until convergence'.format(n_mistakes))
return progress_theta, n_mistakes, explicit_mistakes
if __name__ == '__main__':
X = np.array([[-1, -1], [1, 0], [-1, 1.5]])
# X = np.array([[-1, -1], [1, 0], [-1, 10]])
y = np.array([1, -1, 1])
t_times = range(0, 100)
theta = np.array([-1, -1])
a, b, c = perceptron(X, y, theta, t_times)Limites de la marge et perte de charnière¶
Comme vous l’avez peut-être remarqué, l’algorithme perceptron ne comporte aucun terme de régularisation. Le but était simplement de trouver toute limite de décision qui peut diviser les données correctement. Ici, nous introduirons le concept de perte de marge et de limites de marge pour transformer le problème d’apprentissage d’une limite de décision en un problème d’optimisation en tenant compte de la régularisation.
Motivation derrière les limites de la marge¶
Jetons un coup d’oeil à notre ensemble de données de formation précédemment présenté (figure ci-dessous). Toute limite de décision à l’intérieur des lignes grises pointillées divise correctement les exemples d’entraînement. Cependant, intuitivement, nous aimerions favoriser une limite de décision qui peut maximiser les distances entre la limite de décision et les points d’entraînement. La raison de le faire est parce qu’il est probable que les points que nous souhaitons classer à l’avenir ont un bruit statistique, de sorte qu’une limite de décision trop proche des exemples de formation est plus susceptible de mal classer les versions légèrement modifiées (bruit) des exemples de formation. Par contre, un classificateur qui détient une marge relativement plus élevée entre la limite de décision et les exemples sera probablement plus efficace pour classer les données futures et invisibles.
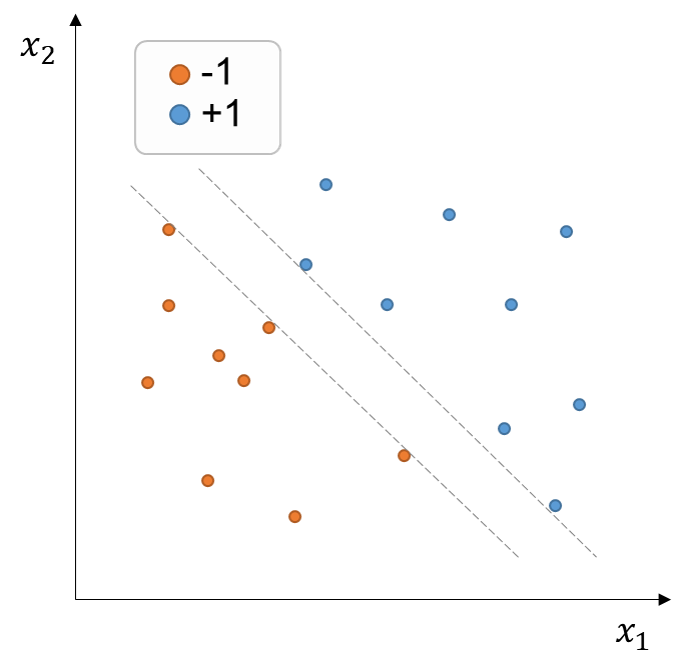
Figure 3:Ensemble de points d’entraînement avec étiquettes binaires (+1, -1) dans l’espace bidimensionnel . Toute limite de décision à l’intérieur des lignes grises pointillées peut diviser correctement les données.
Problème d’optimisation¶
Rappelons que notre objectif est de trouver un classificateur linéaire qui maximise les distances entre la limite de décision et les points d’entraînement (classificateur linéaire de marge), mais aussi minimise l’erreur d’entraînement. Il s’agit donc d’un problème d’optimisation qui doit contrebalancer ces deux facteurs, que l’on peut dire comme suit :
Les marges (distances entre la limite de décision et les points d’entraînement) devraient être optimisées.
L’erreur de formation devrait être réduite au minimum. Nous l’exprimerons en termes de perte de poids.
Limites de marge¶
Auparavant, nous avons vu que l’équation définissant une limite de décision satisfait .
Nous pouvons maintenant définir des limites de marge parallèles (ligne déchiquetée dans la figure précédente) comme suit:
Notez que nous pouvons définir les limites comme ceci parce que nous avons un certain degré de liberté dans notre définition de la limite de décision, à savoir, l’ampleur du vecteur normal . Autrement dit, quelle que soit la valeur , notre limite de décision reste inchangée.
Rappelez-vous le problème du calcul de la petite distance d’un point à un plan. Cette distance est:
Nous pouvons maintenant calculer la distance signée entre la limite de décision et le i-ième exemple comme suit:
Ainsi, la distance entre les limites de la marge et la limite de décision est :
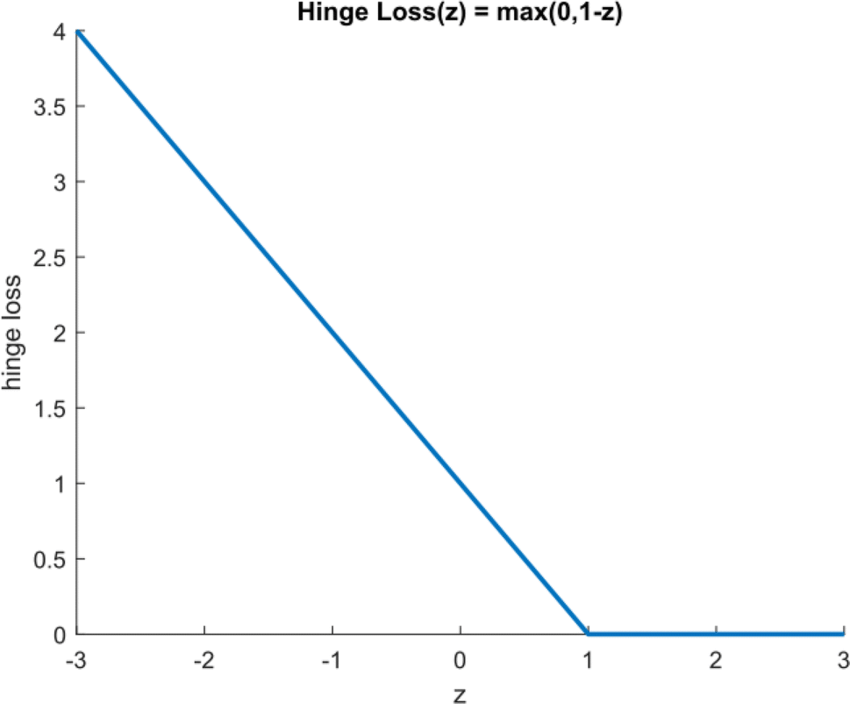
Perte de charnière¶
Nous savons jusqu’ici que classifiera l’exemple i-th. La façon de savoir si la classification est d’accord avec l’étiquette est de la multiplier par . Nous pouvons exprimer cet accord également dans une version légèrement modifiée, en utilisant la perte de charnière:
où est l’accord (distance signée de la limite de décision) .
La figure ci-dessous illustre le fonctionnement de la perte de charnières le long de l’axe des z (distance par rapport aux limites), comme le montre cette publication ResearchGate:
Fonction objective¶
Donc maintenant nous pouvons créer une fonction objective qui (1) minimise la perte moyenne de la charnière par rapport aux exemples de formation, et (2) maximise . Expression (2) peut également être reformulé pour minimiser . Ainsi, nous définissons la fonction objective comme suit:
où est le paramètre de régularisation qui équilibre l’importance de minimiser le terme de régularisation au coût de subir plus de pertes (augmentation du terme de perte). Vice versa, plus la valeur de est faible, plus nous mettrons l’accent sur la réduction de la perte moyenne.