Préparez-vous en clonant le dépôt d’exercices :
git clone https://github.com/Ecohydraulics/Exercise-SequentPeak.git
Figure 1:Nouveau barrage Bullards Bar en Californie, États-Unis (source: Sebastian Schwindt 2017).
Théorie¶
Les réservoirs de stockage saisonniers conservent l’eau pendant les mois humides (par exemple, la mousson ou les hivers pluvieux dans les climats méditerranéens) afin d’assurer un approvisionnement suffisant en eau potable et en agriculture pendant les mois secs. À cette fin, d’énormes volumes de stockage sont nécessaires, qui dépassent souvent 1 000 000 m.
Le volume de stockage nécessaire est déterminé à partir de mesures historiques des débits et des volumes cibles de rejets (p. ex., l’agriculture, l’eau potable, l’hydroélectricité ou les quantités d’eau résiduelles écologiques). L’algorithme de pic séquentiel Potter, 1977 basé sur Rippl (1883) est une procédure vieille de plusieurs décennies pour déterminer le volume de stockage saisonnier nécessaire basé sur une courbe de volume de stockage (*** courbe SD***). La figure ci-dessous montre une courbe exemplaire avec des pics de volume (maxima local) environ tous les 6 mois et des minima de volume locaux entre les pics. Le volume entre le dernier maximum local et le minimum local le plus bas suivant détermine le volume de stockage requis (voir la ligne bleu vif dans la figure).
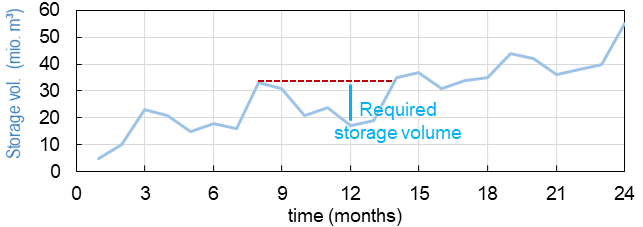
Figure 2:Schéma de l’algorithme de crête séquentielle.
L’algorithme de crête séquentielle répète ce calcul sur plusieurs années et le volume le plus élevé observé détermine le volume requis.
Dans le cadre de cet exercice, nous utilisons des mesures quotidiennes des débits de la rivière Vanilla (dans le pays aride de Vanilla avec des périodes de mousson) et nous visons les volumes d’écoulement pour fournir aux agriculteurs et à la population du pays aride de Vanilla suffisamment d’eau pendant les saisons sèches. Cet exercice vous guide en chargeant les données quotidiennes de décharge, en créant la courbe mensuelle (stockage) et en calculant le volume de stockage requis.
Prétraitement des données de flux¶
Les données quotidiennes de débit de la rivière Vanilla sont disponibles de 1979 à 2001 sous la forme de fichiers .csv (flows dossier).
Écrire une fonction pour lire les données de flux¶
La fonction va passer en boucle les noms de fichiers csv et ajouter le contenu du fichier à un dictionnaire de tableaux numpy. Assurez-vous à import numpy as np, import os et import glob.
Choisissez un nom de fonction (p. ex.
def read_data(args):) et utilisez les arguments d’entrée suivants :directory: string d’un chemin vers les fichiersfn_prefix: string du préfixe de fichier pour enlever les clés de dictée d’un nom de fichierfn_suffix: string du suffixe de fichier pour enlever les clés de dictées d’un nom de fichierftype: chaîne de fin de fichierdelimiter: chaîne du séparateur de colonnes
In the function, test if the provided directory ends on
"/"or"\\"with
directory.endswith("/") or directory.endswith("\\")
and read all files that end withftype(we will useftype="csv"here) with thegloblibrary:if True:obtenir la liste des fichiers csv (ftype) comme
file_list = glob.glob(directory + "*." + ftype.strip(".").if False:obtenir la liste de fichiers csv (ftype) comme
file_list = glob.glob(directory + "/*." + ftype.strip(".")(la différence n’est qu’un puissant"/"signe).
Créez le dictionnaire vide qui contiendra le contenu du fichier sous forme de tableaux numpy :
file_content_dict = {}Loop sur tous les fichiers de la liste de fichiers avec
for file in file_list:Générer une clé pour
file_content_dict:Détachez le nom du fichier
file(répertoire + nom du fichier + fichier se terminantftype) avecraw_file_name = file.split("/")[-1].split("\\")[-1].split(".csv")[0]Enlevez le nom du fichier brut
fn_prefixetfn_suffixstrings et utilisez une déclarationtry:pour convertir les caractères restants en une valeur numérique :int(raw_file_name.strip(fn_prefix).strip(fn_suffix)*Note: Nous utiliserons plus tard
fn_prefix="daily_flows_etfn_suffix=""pour tourner l’année contenue dans les noms de fichiers csv vers la cléfile_content_dict.Utilisez
except ValueError:dans le cas où le reste string ne peut pas être converti enint:dict_key = raw_file_name.strip(fn_prefix).strip(fn_suffix)(si tout est bien codé, le script ne devra pas sauter dans cette déclaration d’exception plus tard).
Ouvrir le fichier
file(annuaire complet) en tant que fichier:with open(file, mode="r") as f:Lisez le contenu du fichier avec
f_content = f.read(). La variable stringf_contentressemblera à quelque chose comme";0;0;0;0;0;0;0;0;0;2.1;0;0\n;0...".
Pour obtenir le nombre de lignes (valables) dans chaque fichier utiliser
rows = f_content.strip("\n").split("\n").__len__()Pour obtenir le nombre de colonnes (valables) dans chaque fichier utiliser
cols = f_content.strip("\n").split("\n")[0].strip(delimiter).split(delimiter).__len__()Maintenant, nous pouvons créer un tableau numpy vide de la taille (forme) correspondant au nombre de lignes et de colonnes valides dans chaque fichier:
data_array = np.empty((rows, cols), dtype=np.float32)Pourquoi n’utilisons-nous pas directement
np.empty((31, 12)même si la forme de tous les fichiers est la même?
Nous voulons écrire une fonction généralement valide et les deux lignes pour calculer le nombre valide de lignes et de colonnes font la tâche de généralisation.Ensuite, nous devons analyser les valeurs de chaque ligne et les ajouter au vide jusqu’à présent
data_array. Par conséquent, nous avons diviséf_contenten ses lignes avecsplit("\n)et utiliser une boucle for:for iteration, line in enumerate(f_content.strip("\n").split("\n"):.
Créer une liste vide pour stocker les données de ligneline_data = [].
Dans une autre boucle for, strip et split la ligne par l’utilisateur-définidelimiter(rappel: nous utiliseronsdelimiter=";")for e in line.strip(delimiter).split(delimiter):. Dans la boucle e-for,try:pour ajouterecomme numéro floatline_data.append(np.float32(e)et utiliserexcept ValueError:àline_data.append(np.nan)(i.e., ajouter une valeur pas-a-numéro dont nous aurons besoin parce que tous les mois n’ont pas 31 jours).
Mettre fin à la boucle e-for en faisant référence à la bouclefor iteration, line in ...et en ajoutant le tableauline_datalist comme tableau numpy àdata_arraydata_array[iteration] = np.array(line_data)De retour dans l’énoncé
with open(file, ...(utiliser le niveau d’indentation correct!), mettre à jourfile_content_dictavec le founddict_keyet ledata_arraydufile as f:file_content_dict.update({dict_key: data_array})Retourner au niveau de la fonction (
def read_data(...):- attention à l’indentation correcte!),return file_content_dict
Vérifiez si la fonction fonctionne comme désiré et suivez les instructions dans la section Faites du script autonome pour mettre en œuvre une déclaration if __name__ == "__main__": à la fin du fichier. Ainsi, le script devrait ressembler au bloc de code suivant:
import glob
import os
import numpy as np
def read_data(directory="", fn_prefix="", fn_suffix="", ftype="csv", delimiter=","):
# see above
if __name__ == "__main__":
# LOAD DATA
file_directory = os.path.abspath("") + "\\flows\\"
daily_flow_dict = read_data(directory=file_directory, ftype="csv",
fn_prefix="daily_flows_", fn_suffix="",
delimiter=";")
print(daily_flow_dict[1995])L’exécution du script renvoie le numpy.array des flux moyens quotidiens pour l’année 1995 :
[[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 4. 0. 14.2 0. 0. 0. 81.7 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 19.7 0. ]
[ 0. 0. 19.8 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 4.8 0. 0. 0. 77.2 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 10.2 0. 0. 0. 0. 0. 0. 12. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 671.8]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 4.6 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 34.2 0. 0. 0. 0. ]
[ 0. 0. 0. 6.3 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 25.3 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 5. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 98.7 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 22.1 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. nan 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. nan 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[ 0. nan 0. nan 0. nan 0. 0. nan 0. nan 0. ]]Convertir les débits quotidiens en volumes mensuels¶
L’algorithme de crête séquentielle prend des débits mensuels, ce qui correspond à la somme de la décharge moyenne quotidienne multipliée par la durée d’une journée (par exemple, 11,0 m/s 24 h/d 3600 s/h). Lire les données de flux comme ci-dessus montre les résultats dans les tableaux de flux annuels (flux quotidiens moyens en m/s) avec les numpy.arrays des tableaux de forme 31x12 (matrices) pour chaque année. Nous voulons obtenir les montants de la colonne et multiplier la somme par 24 h/d 3600 s/h. Parce que les volumes mensuels sont de l’ordre de millions de mètres cubes (CMS), diviser les montants mensuels par 10**6 simplifiera la représentation des nombres.
Écrire une fonction (p. ex., def daily2monthly(daily_flow_series)) pour effectuer la conversion des séries de flux moyens quotidiens en volumes mensuels à 10m:
La fonction doit être appelée pour chaque entrée de dictionnaire (année) de la série de données. Par conséquent, l’argument d’entrée
daily_flow_seriesdevrait être unnumpy.array, la forme étant(31, 12).Pour obtenir des statistiques en colonne (mensuelles), transposez le tableau d’entrées :
daily_flow_series = np.transpose(daily_flow_series)Create a void list to store monthly flow values:
monthly_stats = []Plongez sur la ligne de la (transposée)
daily_flow_serieset ajoutez la somme multipliée par24 * 3600 / 10**6àmonthly_stats
for daily_flows_per_month in daily_flow_series:
monthly_stats.append(np.nansum(daily_flows_per_month * 24 * 3600) / 10**6)Retour
monthly_statsasnumpy.array:
return np.array(monthly_stats)En utilisant une boucle, nous pouvons maintenant écrire les volumes mensuels semblables aux flux quotidiens dans un dictionnaire, que nous prolongeons d’un an à la fois dans l’énoncé if __name__ == "__main__":
import ...
def read_data(directory="", fn_prefix="", fn_suffix="", ftype="csv", delimiter=","):
# see above section
def daily2monthly(daily_flow_series):
# see above descriptions
if __name__ == "__main__":
# LOAD DATA
...
# CONVERT DAILY TO MONTHLY DATA
monthly_vol_dict = {}
for year, flow_array in daily_flow_dict.items():
monthly_vol_dict.update({year: daily2monthly(flow_array)})Algorithme de pic de séquence¶
Avec les routines ci-dessus pour la lecture des données de flux, nous avons calculé des volumes mensuels d’entrée in million m (stockés à monthly_vol_dict). Pour l’irrigation et l’approvisionnement en eau potable, le pays aride de la Vanille veut retirer du réservoir le volume annuel suivant :
| Month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vol. (10 m) | 1.5 | 1.5 | 1.5 | 2 | 4 | 4 | 4 | 5 | 5 | 3 | 2 | 1.5 |
Suivant le schéma des volumes entrants, nous pouvons créer un numpy.array pour les volumes sortants mensuels .
monthly_supply = np.array([1.5, 1.5, 1.5, 2.0, 4.0, 4.0, 4.0, 5.0, 5.0, 3.0, 2.0, 1.5])Volume de stockage et différences (ligne SD) Courbes¶
Le volume de stockage du présent mois est calculé en fonction du bilan hydrique du dernier mois, par exemple:
= + -
= + - = + + - -
En notation sommaire, nous pouvons écrire:
Les deux derniers termes constituent la différence de stockage () ligne:
Ainsi, la courbe de stockage en fonction de la ligne est :
La notation de sommation de la courbe de stockage en fonction de la ligne nous permet d’implémenter le calcul en une simple fonction def sequent_peak(in_vol_series, out_vol_target):.
La nouvelle fonction def sequent_peak(in_vol_series, out_vol_target): doit :
Calculer les différences mensuelles de stockage ( - ), par exemple dans une boucle for sur le dictionnaire
in_vol_series:
# create storage-difference SD dictionary
SD_dict = {}
for year, monthly_volume in in_vol_series.items():
# add a new dictionary entry for every year
SD_dict.update({year: []})
for month_no, in_vol in enumerate(monthly_volume):
# append one list entry per month (i.e., In_m - Out_m)
SD_dict[year].append(in_vol - out_vol_target[month_no])Aplatissez le dictionnaire sur une liste (nous aurions pu le faire directement) correspondant à la ligne :
SD_line = []
for year in SD_dict.keys():
for vol in SD_dict[year]:
SD_line.append(vol)Calculer la ligne de stockage avec
storage_line = np.cumsum(SD_line)Trouvez l’extrémité locale et il y a deux (et plus) options:
Utilisez
from scipy.signal import argrelextremaet obtenez les indices (positions de) local extrema et leur valeur à partir destorage_line:
seas_max_index = np.array(argrelextrema(storage_line, np.greater, order=12)[0])
seas_min_index = np.array(argrelextrema(storage_line, np.less, order=12)[0])
seas_max_vol = np.take(storage_line, seas_max_index)
seas_min_vol = np.take(storage_line, seas_min_index)Écrire deux fonctions, qui trouvent consécutivement maxima local et puis minima locaux situés entre l’extrémité (cours travail à domicile) OU utilisez
from scipy.signal import find_peakspour trouver les indices (positions) - envisager d’écrire une fonctionfind_seasonal_extrema(storage_line).
Assurez-vous que les courbes et l’extrémité sont correctes en copiant la courbe
plot_storage_curveà votre script (disponible dans le dépôt d’exercice) et en l’utilisant comme suit :
plot_storage_curve(storage_line, seas_min_index, seas_max_index, seas_min_vol, seas_max_vol)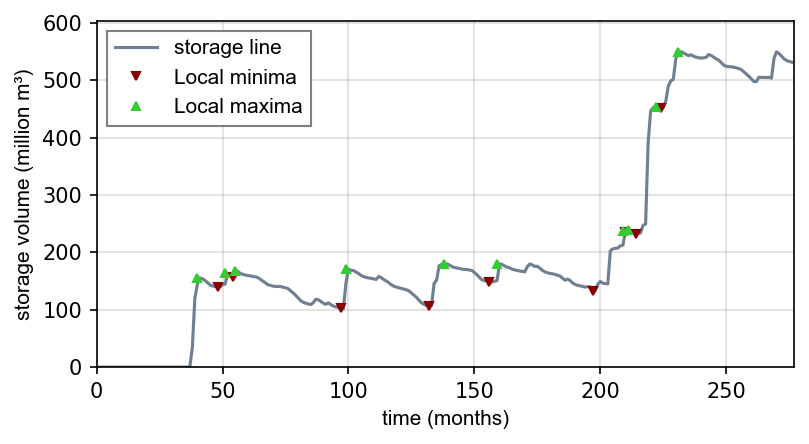
Figure 3:Courbe de la différence de stockage (SD).
Calculer le volume de stockage requis¶
Le volume de stockage requis correspond à la plus grande différence entre un maximum local et son minimum local le plus bas consécutif. Par conséquent, ajouter les lignes suivantes à la fonction sequent_peak:
required_volume = 0.0
for i, vol in enumerate(list(seas_max_vol):
try:
if (vol - seas_min_vol[i]) > required_volume:
required_volume = vol - seas_min_vol[i]
except IndexError:
print("Reached end of storage line.")Fermer la fonction sequent_peak avec return required_volume
Appeler l’algorithme du pic Sequent¶
Avec toutes les fonctions requises écrites, la dernière tâche est d’appeler les fonctions dans l’énoncé if __name__ == "__main__":
import ...
def read_data(directory="", fn_prefix="", fn_suffix="", ftype="csv", delimiter=","):
# see above section
def daily2monthly(daily_flow_series):
# see above section
def sequent_peak(in_vol_series, out_vol_target):
# see above descriptions
if __name__ == "__main__":
# LOAD DATA
...
# CONVERT DAILY TO MONTHLY DATA
...
# MAKE ARRAY OF MONTHLY SUPPLY VOLUMES (IN MILLION CMS)
monthly_supply = np.array([1.5, 1.5, 1.5, 2.0, 4.0, 4.0, 4.0, 5.0, 5.0, 3.0, 2.0, 1.5])
# GET REQUIRED STORAGE VOLUME FROM SEQUENT PEAK ALGORITHM
required_storage = sequent_peak(in_vol_series=monthly_vol_dict, out_vol_target=monthly_supply)
print("The required storage volume is %0.2f million CMS." % required_storage)Remarques finales¶
L’utilisation de l’algorithme de crête séquentielle (aussi connu sous le nom de méthode de Rippl en raison de son auteur original) a évolué et a été mise en œuvre dans des algorithmes sophistiqués de contrôle du volume de stockage avec des modèles prédicteurs (statistiques et/ou numériques).
Finalement, il y a plusieurs algorithmes et moyens de les coder. De nombreux facteurs (p. ex. terrain ou zone climatique) déterminent si un stockage saisonnier est possible ou nécessaire. Pour déterminer le volume de stockage, il ne faut pas négliger les aspects sociaux et environnementaux. Chaque grain de sédiments conservé est manquant dans les sections en aval de la rivière, chaque poisson qui n’est plus en mesure de migrer souffre d’une perte d’habitat, et plus que tout autre, chaque habitant qui subit des pertes économiques ou est même contraint de se réinstaller en raison du barrage doit être évité ou adéquatement compensé.
- Potter, K. W. (1977). Sequent Peak Procedure: Minimum Reservoir Capacity Subject to Constraint on Final Storage. JAWRA Journal of the American Water Resources Association, 13(3), 521–528. 10.1111/j.1752-1688.1977.tb05564.x
- Rippl, W. (1883). The capacity of storage-reservoirs for water-slpply. (including plate). Minutes of the Proceedings of the Institution of Civil Engineers, 71(1883), 270–278. 10.1680/imotp.1883.21797