Lineare Klassifizierung¶
In diesem Abschnitt werden wir die Grundlagen der linearen Klassifizierung durch einen einfachen ML-Algorithmus, den Perceptron. Darüber hinaus werden wir die Konzepte hinter dem Perceptron-Algorithmus erweitern, indem wir Aspekte der Regularisierung berücksichtigen, um einen Margen-Linear-Klassifikator aufzubauen.
Hyperplane¶
Angenommen, wir möchten positive und negative Objekte aus dem Trainingssatz unten (Abbildung links) klassifizieren:
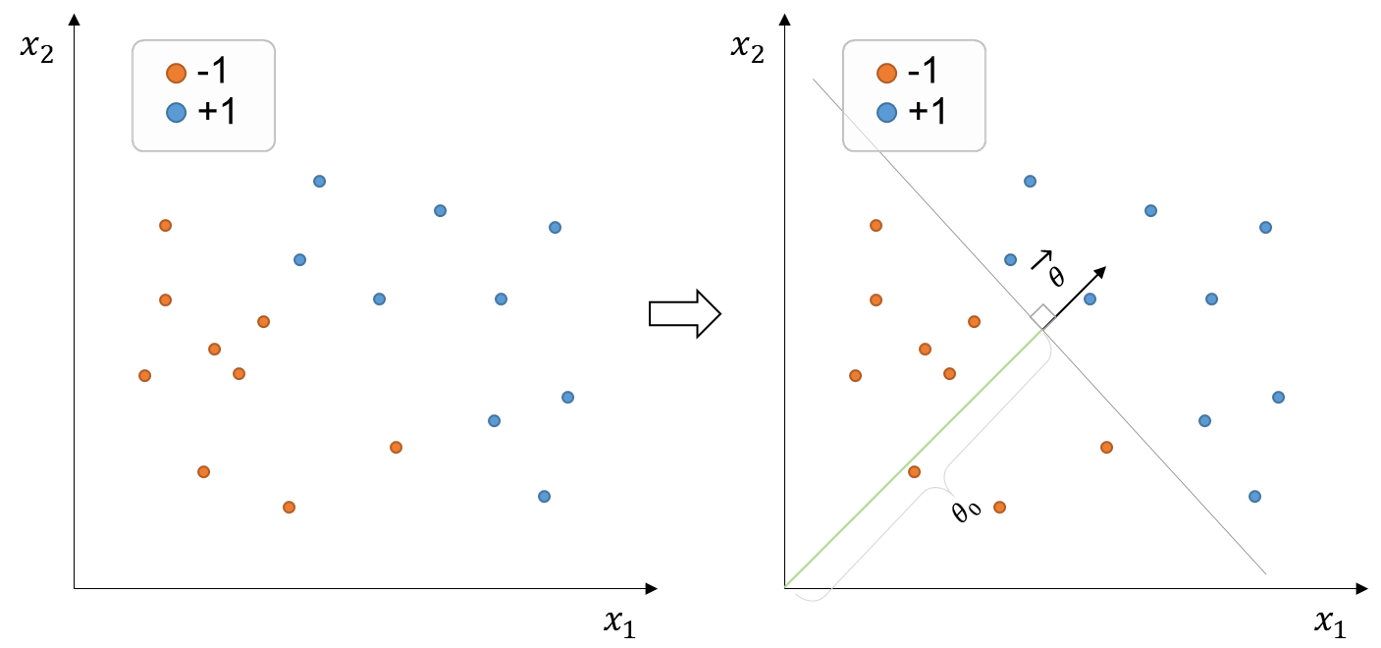
Figure 1:Trainingsset von Punkten mit binären Labels (+1, -1) und zweidimensionalen Features. Die Entscheidungsgrenze (graue Linie) wird durch den Parametervektor , der der Entscheidungsgrenze normal ist, und den Offsetparameter , der die Daten linear trennt, definiert.
Der vorstehende Datensatz wird als linear trennbar angesehen, da er mindestens eine lineare Entscheidungsgrenze zur korrekten Aufteilung des gesamten Datensatzes aufweist. Zum Beispiel könnten wir eine Entscheidungsgrenze wie die graue Linie oben passieren (Abbildung rechts)
Da die Merkmale , d.h. der Merkmalssatz zum zweidimensionalen Raum gehört, stellt die Entscheidungsgrenze eine Linie dar. Wenn wir mit einer Reihe von Features im dreidimensionalen Raum umgehen, wäre die Entscheidungsgrenze ein Flugzeug. In analoger Weise, wenn unser Feature-Set in einem höheren Raum wäre, würde die Entscheidungsgrenze eine Hyperplane bilden.
Ein Hyperplan mit -Dimensionen wird üblicherweise durch den flugzeugnormalen Vektor und Offset (scalar) Parameter bezeichnet. Im obigen Beispiel würden wir das Hyperplan (oder die Entscheidungsgrenze) definieren als:
Unser Klassifikator ist damit gleich , wo und . Rufen Sie die Vorzeichenfunktion, auch als Vorzeichenfunktion bekannt, ist eine mathematische Funktion, die das Vorzeichen oder die Richtung einer realen Zahl zurückgibt. Das heißt, wenn die Eingangszahl positiv, negativ oder 0 ist, kehrt die Vorzeichenfunktion +1, -1 bzw. 0 zurück.
Perceptron-Algorithmus¶
Im Perceptron-Algorithmus initialisieren wir typischerweise als Null (Nullvektor) und schleifen durch das Paar von Trainingsbeispielen. Bei jeder Iteration werden wir überprüfen, ob der Klassifikator einen Fehler macht, dieses Trainingsbeispiel (i-th Beispiel) einzustufen, und wenn ja, dann aktualisieren wir die Parameter von .
Assume that for simplicity (the decision boundary must pass through the origin). Our perceptron classifier will make a mistake if . We will then update our to no longer misclassify that training example. The way to do this is by adding to the previous . Thus, the update would look like:
Wir haben in den Händen eine Reihe von verschiedenen Trainingsbeispielen, die das Potenzial haben, unseren Klassifikator in viele Richtungen zu nudeln/zu aktualisieren. So ist es möglich und sogar erwartet, dass die letzten Trainingsbeispiele Updates verursachen, die frühere, erste Updates überschreiben werden. Dies führt dazu, dass frühere Beispiele nicht mehr korrekt klassifiziert werden. Aus diesem Grund müssen wir durch das gesamte Trainingsset mehrere -Zeiten schleifen, um sicherzustellen, dass alle Beispiele korrekt klassifiziert werden. Solche Iterationen können sowohl in Reihenfolge als auch zufällig aus den Trainingsbeispielen ausgewählt werden.
Wir können den Algorithmus wie folgt kodieren:
import numpy as np
# Algorithm always starting to loop from x1
def perceptron(X, y, theta, t_times):
n_mistakes = 0
# Initialize list to show the progress (updates) of theta
progress_theta = []
# Initialize an array with same size as the total number of examples to count how many mistake are made at each training example
explicit_mistakes = np.zeros(shape=y.shape[0])
# Loop through the training set T times
for t in t_times:
# Loop through the training examples in order
for index, x in enumerate(X):
# Check if the algorithm makes a mistake in the i-th (or index-th) example
if y[index] * np.dot(theta, x) <= 0:
# Update theta to no longer misclassify the i-th example
theta = theta + y[index] * x
# Save the update theta
progress_theta.append(theta)
# Update total number of mistakes
n_mistakes += 1
# Update total number of mistakes at the i-th training example
explicit_mistakes[index] += 1
print('The perceptron did {} mistakes until convergence'.format(n_mistakes))
return progress_theta, n_mistakes, explicit_mistakes
if __name__ == '__main__':
X = np.array([[-1, -1], [1, 0], [-1, 1.5]])
# X = np.array([[-1, -1], [1, 0], [-1, 10]])
y = np.array([1, -1, 1])
t_times = range(0, 100)
theta = np.array([-1, -1])
a, b, c = perceptron(X, y, theta, t_times)Margengrenzen und Scharnierverlust¶
Wie Sie vielleicht bemerkt haben, bietet der Perceptron-Algorithmus keinen Regularisierungsbegriff. Das Ziel war einfach, jede Entscheidungsgrenze zu finden, die die Daten richtig teilen kann. Hier werden wir das Konzept von hinge loss und margin Grenzen einführen, um das Problem des Lernens einer Entscheidungsgrenze in ein Optimierungsproblem unter Berücksichtigung der Regularisierung zu transformieren.
Motivation hinter Margengrenzen¶
Schauen wir uns unseren bisher vorgestellten Trainingsdatensatz an (Abbildung unten). Jede Entscheidungsgrenze innerhalb der gestrichelten Graulinien teilt die Trainingsbeispiele richtig auf. Intuitiv möchten wir jedoch eine Entscheidungsgrenze bevorzugen, die die Abstände zwischen der Entscheidungsgrenze und den Trainingspunkten maximieren kann. Der Grund dafür ist, dass es wahrscheinlich ist, dass die Punkte, die wir zukünftig klassifizieren möchten, statistische Geräusche haben, so dass eine zu nahe an den Ausbildungsbeispielen liegende Entscheidungsgrenze eher eine geringfügig veränderte (noisier) Versionen der Ausbildungsbeispiele falsch einstufen kann. Ein Klassifikator, der eine relativ höhere Marge zwischen der Entscheidungsgrenze und den Beispielen hält, wird hingegen bei der Klassifizierung künftiger, nicht gesicherter Daten wahrscheinlich erfolgreicher sein.
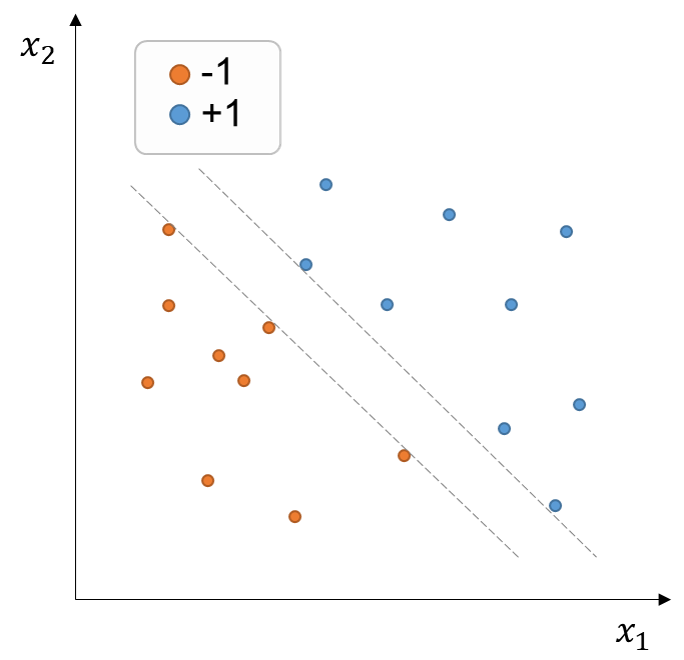
Figure 3:Trainingsset von Punkten mit binären Etiketten (+1, -1) im zweidimensionalen Spielraum . Jede Entscheidungsgrenze innerhalb der gestrichelten Graulinien kann die Daten richtig teilen.
Optimierungsproblem¶
Erinnern Sie sich, dass unser Ziel ist, einen linearen Klassifikator zu finden, der die Entfernungen zwischen der Entscheidungsgrenze und den Trainingspunkten (margin linear Klassifikator) maximiert, aber auch den Trainingsfehler minimiert. Dies stellt also ein Optimierungsproblem dar, das diesen beiden Faktoren entgegenwirken muss, die wir als:
Die Margen (Abstände zwischen der Entscheidungsgrenze und den Trainingspunkten) sollten maximiert werden.
Der Trainingsfehler sollte minimiert werden. Wir werden dies im Sinne von Hintergrundverlust ausdrücken.
Margengrenzen¶
Zuvor sahen wir, dass die Gleichung, die eine Entscheidungsgrenze definiert, genügt.
Wir können jetzt parallele Margengrenzen definieren (gestrichelt in der vorherigen Abbildung) als:
Beachten Sie, dass wir die Grenzen so definieren können, weil wir einen Grad an Freiheit in unserer Definition der Entscheidungsgrenze haben, nämlich die Größe des normalen Vektors . Das ist, unabhängig vom Wert , unsere Entscheidungsgrenze bleibt unverändert.
Rufen Sie das Problem der Berechnung der kleinsten Entfernung eines Punktes an eine plan. Diese Entfernung ist:
Wir können nun den unterschriebenen Abstand zwischen der Entscheidungsgrenze und dem i-ten Beispiel berechnen:
Somit ist der Abstand zwischen den Randgrenzen und der Entscheidungsgrenze:
Hinfälliger Verlust¶
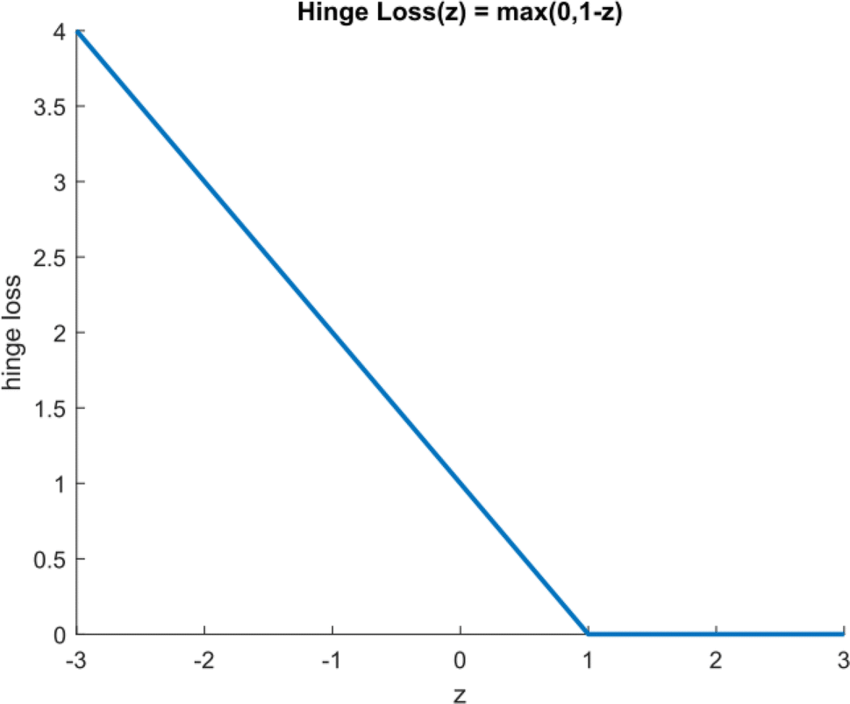
Bisher wissen wir, dass das i-te Beispiel klassifiziert. Der Weg zu wissen, ob die Klassifikation mit dem Label einverstanden ist, indem es von multipliziert. Wir können diese Vereinbarung auch in einer leicht modifizierten Version mit dem Scharnierverlust ausdrücken:
wobei die Vereinbarung ist (bezeichnete Entfernung von der Entscheidungsgrenze) .
Die Abbildung unten zeigt, wie der Scharnierverlust entlang der z-Achse (Abstand von Grenze) funktioniert, wie in dieses ResearchGate Publikation:
Zielfunktion¶
So können wir jetzt eine objektive Funktion schaffen, die (1) den durchschnittlichen Scharnierverlust über die Trainingsbeispiele minimiert und (2) maximiert . Expression (2) kann auch auf eine Minimierung zu reformieren. So definieren wir die Zielfunktion als:
wobei der Regelparameter ist, der die Bedeutung der Minimierung des Regelungsterms zu den Kosten für die Einbindung von mehr Verlusten (Erhöhung der Verlustdauer) ausgleicht. Je kleiner der Wert von ist, desto mehr betonen wir, den durchschnittlichen Verlust zu minimieren.